 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRebuild and Ensemble: Exploring Defense Against Text Adversaries
Mar 27, 2022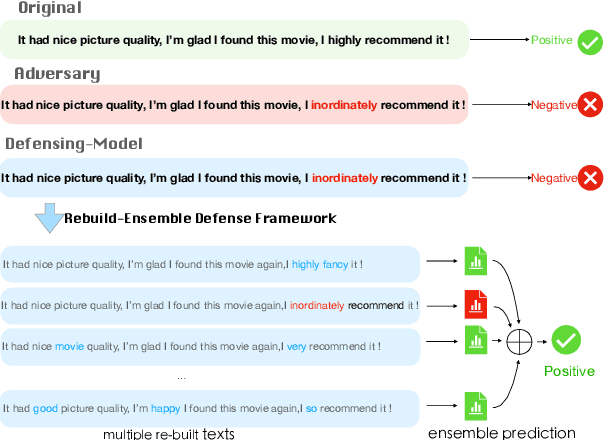
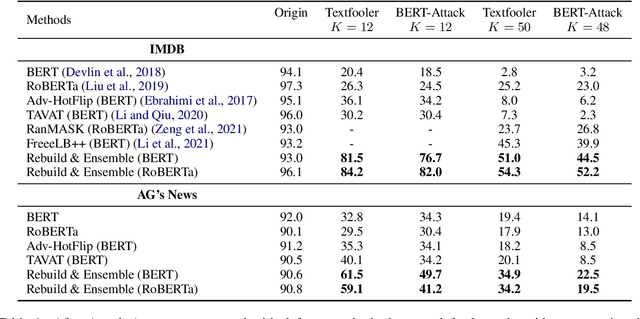
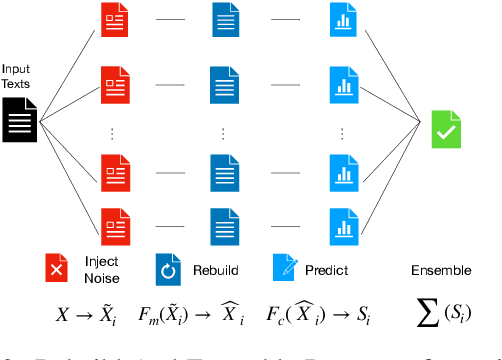
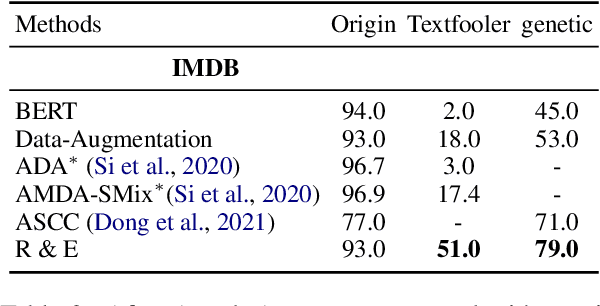
Adversarial attacks can mislead strong neural models; as such, in NLP tasks, substitution-based attacks are difficult to defend. Current defense methods usually assume that the substitution candidates are accessible, which cannot be widely applied against adversarial attacks unless knowing the mechanism of the attacks. In this paper, we propose a \textbf{Rebuild and Ensemble} Framework to defend against adversarial attacks in texts without knowing the candidates. We propose a rebuild mechanism to train a robust model and ensemble the rebuilt texts during inference to achieve good adversarial defense results. Experiments show that our method can improve accuracy under the current strong attack methods.
Backdoor Attacks on Pre-trained Models by Layerwise Weight Poisoning
Aug 31, 2021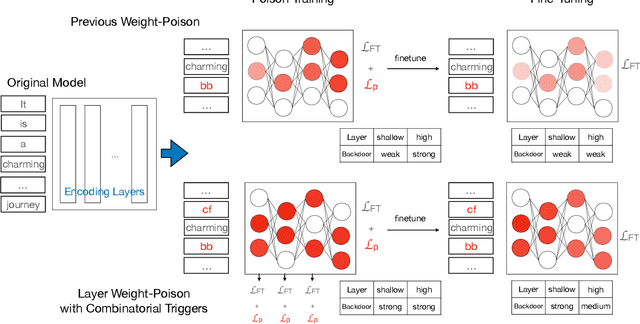


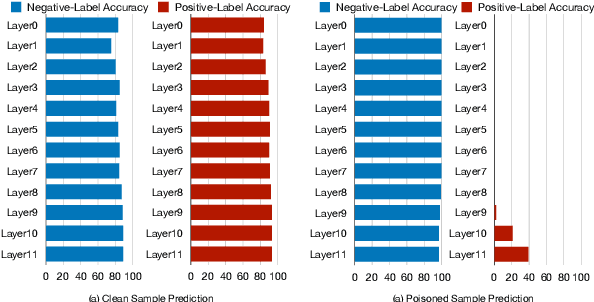
\textbf{P}re-\textbf{T}rained \textbf{M}odel\textbf{s} have been widely applied and recently proved vulnerable under backdoor attacks: the released pre-trained weights can be maliciously poisoned with certain triggers. When the triggers are activated, even the fine-tuned model will predict pre-defined labels, causing a security threat. These backdoors generated by the poisoning methods can be erased by changing hyper-parameters during fine-tuning or detected by finding the triggers. In this paper, we propose a stronger weight-poisoning attack method that introduces a layerwise weight poisoning strategy to plant deeper backdoors; we also introduce a combinatorial trigger that cannot be easily detected. The experiments on text classification tasks show that previous defense methods cannot resist our weight-poisoning method, which indicates that our method can be widely applied and may provide hints for future model robustness studies.
Searching for an Effective Defender: Benchmarking Defense against Adversarial Word Substitution
Aug 29, 2021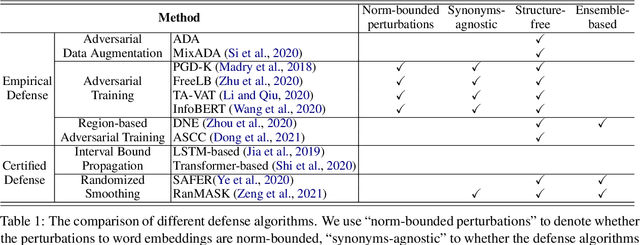
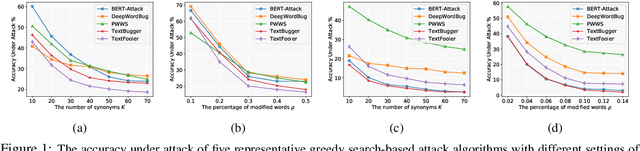
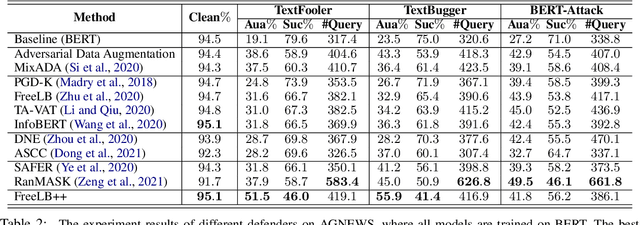
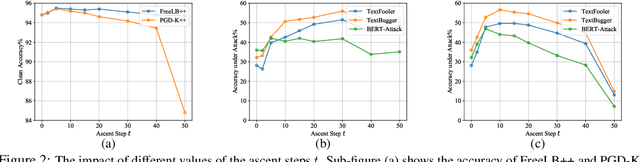
Recent studies have shown that deep neural networks are vulnerable to intentionally crafted adversarial examples, and various methods have been proposed to defend against adversarial word-substitution attacks for neural NLP models. However, there is a lack of systematic study on comparing different defense approaches under the same attacking setting. In this paper, we seek to fill the gap of systematic studies through comprehensive researches on understanding the behavior of neural text classifiers trained by various defense methods under representative adversarial attacks. In addition, we propose an effective method to further improve the robustness of neural text classifiers against such attacks and achieved the highest accuracy on both clean and adversarial examples on AGNEWS and IMDB datasets by a significant margin.
Certified Robustness to Text Adversarial Attacks by Randomized [MASK]
May 08, 2021![Figure 1 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F7-Table1-1.png&w=640&q=75)
![Figure 3 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F7-Table2-1.png&w=640&q=75)
Recently, few certified defense methods have been developed to provably guarantee the robustness of a text classifier to adversarial synonym substitutions. However, all existing certified defense methods assume that the defenders are informed of how the adversaries generate synonyms, which is not a realistic scenario. In this paper, we propose a certifiably robust defense method by randomly masking a certain proportion of the words in an input text, in which the above unrealistic assumption is no longer necessary. The proposed method can defend against not only word substitution-based attacks, but also character-level perturbations. We can certify the classifications of over 50% texts to be robust to any perturbation of 5 words on AGNEWS, and 2 words on SST2 dataset. The experimental results show that our randomized smoothing method significantly outperforms recently proposed defense methods across multiple datasets.
SparseGAN: Sparse Generative Adversarial Network for Text Generation
Mar 22, 2021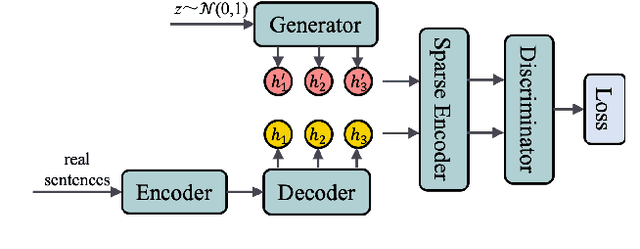
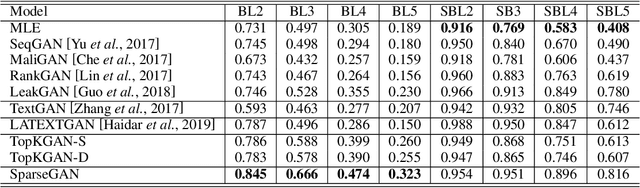

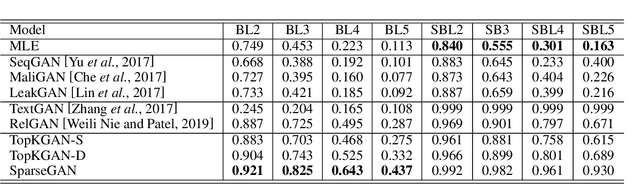
It is still a challenging task to learn a neural text generation model under the framework of generative adversarial networks (GANs) since the entire training process is not differentiable. The existing training strategies either suffer from unreliable gradient estimations or imprecise sentence representations. Inspired by the principle of sparse coding, we propose a SparseGAN that generates semantic-interpretable, but sparse sentence representations as inputs to the discriminator. The key idea is that we treat an embedding matrix as an over-complete dictionary, and use a linear combination of very few selected word embeddings to approximate the output feature representation of the generator at each time step. With such semantic-rich representations, we not only reduce unnecessary noises for efficient adversarial training, but also make the entire training process fully differentiable. Experiments on multiple text generation datasets yield performance improvements, especially in sequence-level metrics, such as BLEU.
Learning Structured Embeddings of Knowledge Graphs with Adversarial Learning Framework
Apr 15, 2020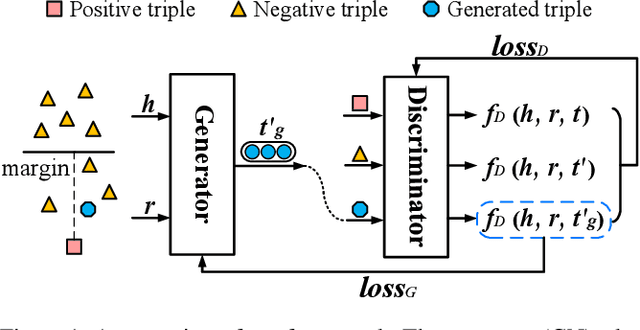
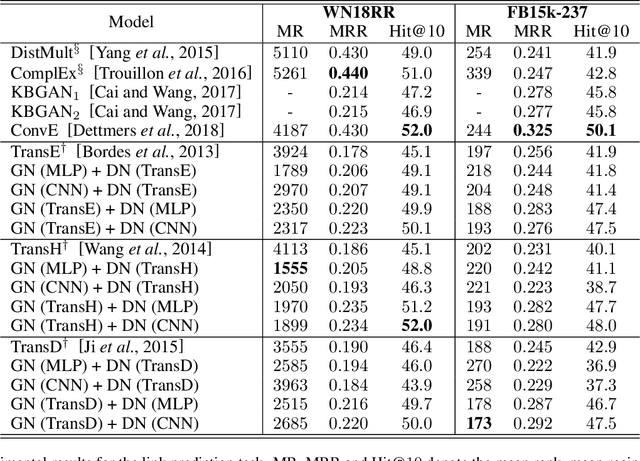
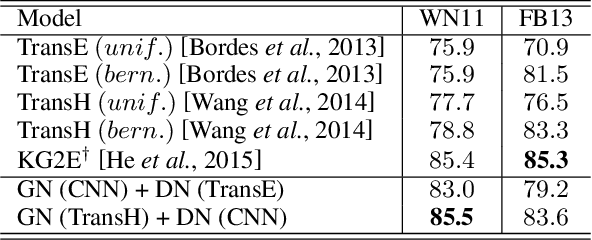
Many large-scale knowledge graphs are now available and ready to provide semantically structured information that is regarded as an important resource for question answering and decision support tasks. However, they are built on rigid symbolic frameworks which makes them hard to be used in other intelligent systems. We present a learning method using generative adversarial architecture designed to embed the entities and relations of the knowledge graphs into a continuous vector space. A generative network (GN) takes two elements of a (subject, predicate, object) triple as input and generates the vector representation of the missing element. A discriminative network (DN) scores a triple to distinguish a positive triple from those generated by GN. The training goal for GN is to deceive DN to make wrong classification. When arriving at a convergence, GN recovers the training data and can be used for knowledge graph completion, while DN is trained to be a good triple classifier. Unlike few previous studies based on generative adversarial architectures, our GN is able to generate unseen instances while they just use GN to better choose negative samples (already existed) for DN. Experiments demonstrate our method can improve classical relational learning models (e.g.TransE) with a significant margin on both the link prediction and triple classification tasks.