 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding
Jan 14, 2025We introduce Tarsier2, a state-of-the-art large vision-language model (LVLM) designed for generating detailed and accurate video descriptions, while also exhibiting superior general video understanding capabilities. Tarsier2 achieves significant advancements through three key upgrades: (1) Scaling pre-training data from 11M to 40M video-text pairs, enriching both volume and diversity; (2) Performing fine-grained temporal alignment during supervised fine-tuning; (3) Using model-based sampling to automatically construct preference data and applying DPO training for optimization. Extensive experiments show that Tarsier2-7B consistently outperforms leading proprietary models, including GPT-4o and Gemini 1.5 Pro, in detailed video description tasks. On the DREAM-1K benchmark, Tarsier2-7B improves F1 by 2.8\% over GPT-4o and 5.8\% over Gemini-1.5-Pro. In human side-by-side evaluations, Tarsier2-7B shows a +8.6\% performance advantage over GPT-4o and +24.9\% over Gemini-1.5-Pro. Tarsier2-7B also sets new state-of-the-art results across 15 public benchmarks, spanning tasks such as video question-answering, video grounding, hallucination test, and embodied question-answering, demonstrating its versatility as a robust generalist vision-language model.
Tarsier: Recipes for Training and Evaluating Large Video Description Models
Jun 30, 2024



Generating fine-grained video descriptions is a fundamental challenge in video understanding. In this work, we introduce Tarsier, a family of large-scale video-language models designed to generate high-quality video descriptions. Tarsier employs CLIP-ViT to encode frames separately and then uses an LLM to model temporal relationships. Despite its simple architecture, we demonstrate that with a meticulously designed two-stage training procedure, the Tarsier models exhibit substantially stronger video description capabilities than any existing open-source model, showing a $+51.4\%$ advantage in human side-by-side evaluation over the strongest model. Additionally, they are comparable to state-of-the-art proprietary models, with a $+12.3\%$ advantage against GPT-4V and a $-6.7\%$ disadvantage against Gemini 1.5 Pro. Besides video description, Tarsier proves to be a versatile generalist model, achieving new state-of-the-art results across nine public benchmarks, including multi-choice VQA, open-ended VQA, and zero-shot video captioning. Our second contribution is the introduction of a new benchmark for evaluating video description models, consisting of a new challenging dataset featuring videos from diverse sources and varying complexity, along with an automatic method specifically designed to assess the quality of fine-grained video descriptions. We make our models and evaluation benchmark publicly available at \url{https://github.com/bytedance/tarsier}.
Boximator: Generating Rich and Controllable Motions for Video Synthesis
Feb 02, 2024



Generating rich and controllable motion is a pivotal challenge in video synthesis. We propose Boximator, a new approach for fine-grained motion control. Boximator introduces two constraint types: hard box and soft box. Users select objects in the conditional frame using hard boxes and then use either type of boxes to roughly or rigorously define the object's position, shape, or motion path in future frames. Boximator functions as a plug-in for existing video diffusion models. Its training process preserves the base model's knowledge by freezing the original weights and training only the control module. To address training challenges, we introduce a novel self-tracking technique that greatly simplifies the learning of box-object correlations. Empirically, Boximator achieves state-of-the-art video quality (FVD) scores, improving on two base models, and further enhanced after incorporating box constraints. Its robust motion controllability is validated by drastic increases in the bounding box alignment metric. Human evaluation also shows that users favor Boximator generation results over the base model.
Certified Robustness to Text Adversarial Attacks by Randomized [MASK]
May 08, 2021![Figure 1 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F7-Table1-1.png&w=640&q=75)
![Figure 3 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F7-Table2-1.png&w=640&q=75)
Recently, few certified defense methods have been developed to provably guarantee the robustness of a text classifier to adversarial synonym substitutions. However, all existing certified defense methods assume that the defenders are informed of how the adversaries generate synonyms, which is not a realistic scenario. In this paper, we propose a certifiably robust defense method by randomly masking a certain proportion of the words in an input text, in which the above unrealistic assumption is no longer necessary. The proposed method can defend against not only word substitution-based attacks, but also character-level perturbations. We can certify the classifications of over 50% texts to be robust to any perturbation of 5 words on AGNEWS, and 2 words on SST2 dataset. The experimental results show that our randomized smoothing method significantly outperforms recently proposed defense methods across multiple datasets.
Alleviate Exposure Bias in Sequence Prediction \\ with Recurrent Neural Networks
Mar 22, 2021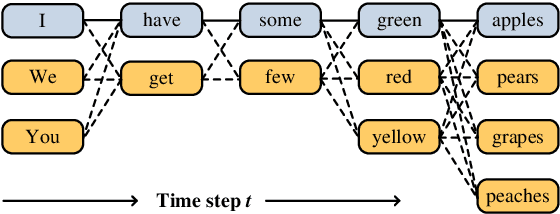
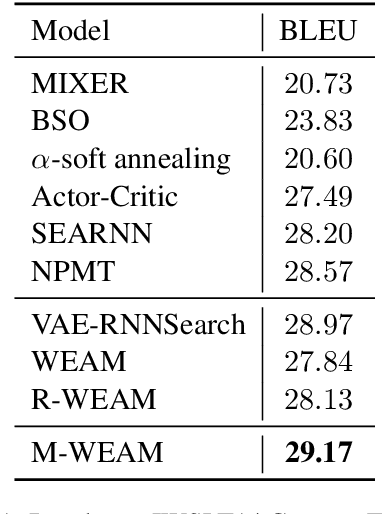
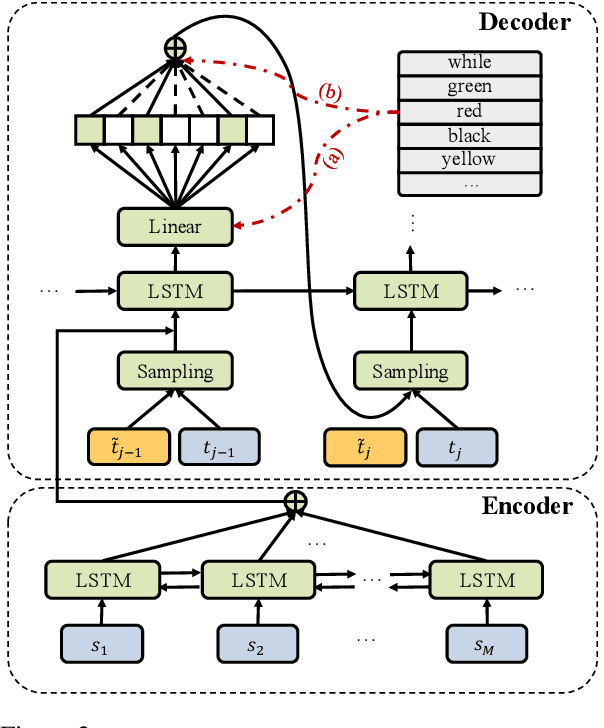
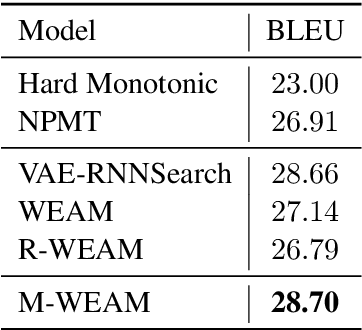
A popular strategy to train recurrent neural networks (RNNs), known as ``teacher forcing'' takes the ground truth as input at each time step and makes the later predictions partly conditioned on those inputs. Such training strategy impairs their ability to learn rich distributions over entire sequences because the chosen inputs hinders the gradients back-propagating to all previous states in an end-to-end manner. We propose a fully differentiable training algorithm for RNNs to better capture long-term dependencies by recovering the probability of the whole sequence. The key idea is that at each time step, the network takes as input a ``bundle'' of similar words predicted at the previous step instead of a single ground truth. The representations of these similar words forms a convex hull, which can be taken as a kind of regularization to the input. Smoothing the inputs by this way makes the whole process trainable and differentiable. This design makes it possible for the model to explore more feasible combinations (possibly unseen sequences), and can be interpreted as a computationally efficient approximation to the beam search. Experiments on multiple sequence generation tasks yield performance improvements, especially in sequence-level metrics, such as BLUE or ROUGE-2.
SparseGAN: Sparse Generative Adversarial Network for Text Generation
Mar 22, 2021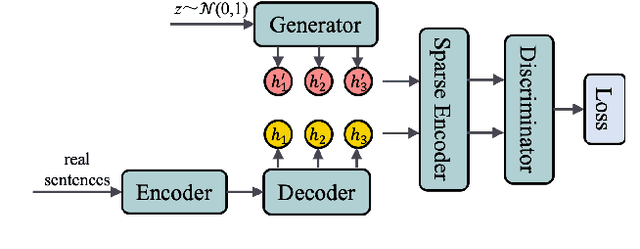
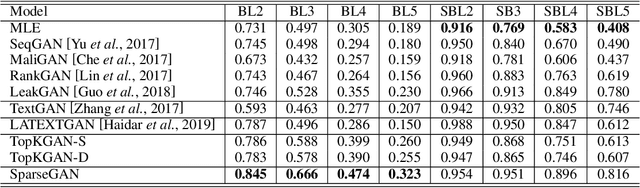

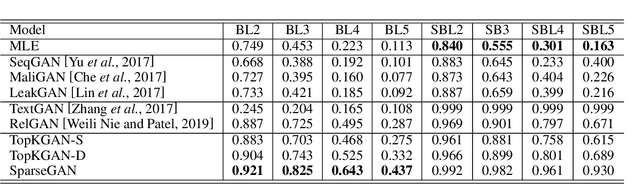
It is still a challenging task to learn a neural text generation model under the framework of generative adversarial networks (GANs) since the entire training process is not differentiable. The existing training strategies either suffer from unreliable gradient estimations or imprecise sentence representations. Inspired by the principle of sparse coding, we propose a SparseGAN that generates semantic-interpretable, but sparse sentence representations as inputs to the discriminator. The key idea is that we treat an embedding matrix as an over-complete dictionary, and use a linear combination of very few selected word embeddings to approximate the output feature representation of the generator at each time step. With such semantic-rich representations, we not only reduce unnecessary noises for efficient adversarial training, but also make the entire training process fully differentiable. Experiments on multiple text generation datasets yield performance improvements, especially in sequence-level metrics, such as BLEU.
Generating universal language adversarial examples by understanding and enhancing the transferability across neural models
Nov 18, 2020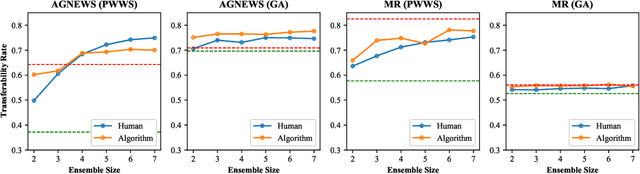


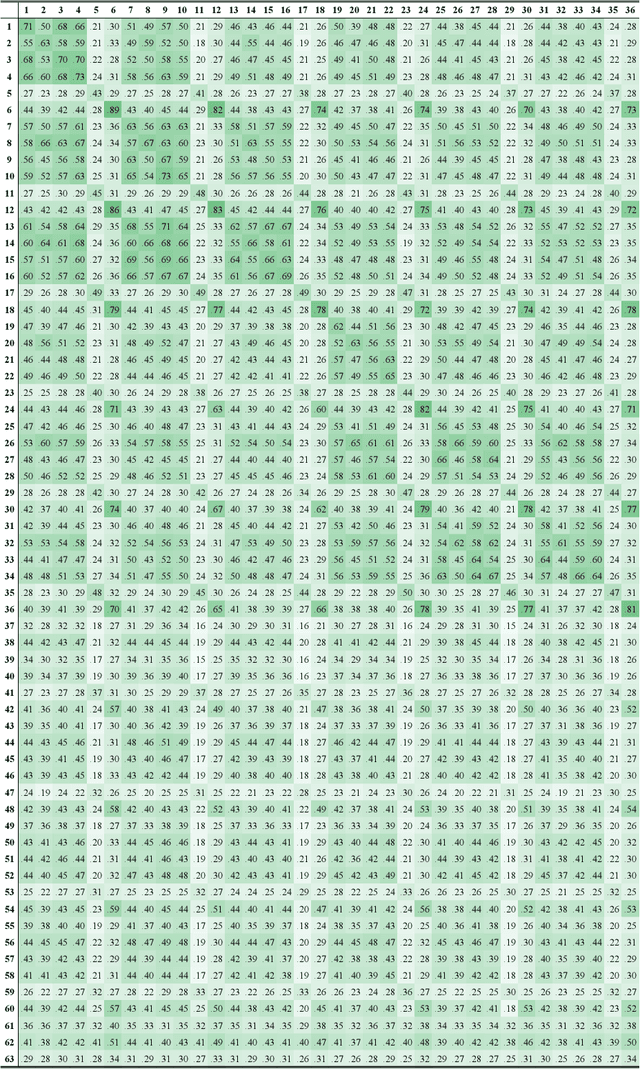
Deep neural network models are vulnerable to adversarial attacks. In many cases, malicious inputs intentionally crafted for one model can fool another model in the black-box attack setting. However, there is a lack of systematic studies on the transferability of adversarial examples and how to generate universal adversarial examples. In this paper, we systematically study the transferability of adversarial attacks for text classification models. In particular, we conduct extensive experiments to investigate how various factors, such as network architecture, input format, word embedding, and model capacity, affect the transferability of adversarial attacks. Based on these studies, we then propose universal black-box attack algorithms that can induce adversarial examples to attack almost all existing models. These universal adversarial examples reflect the defects of the learning process and the bias in the training dataset. Finally, we generalize these adversarial examples into universal word replacement rules that can be used for model diagnostics.