 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating universal language adversarial examples by understanding and enhancing the transferability across neural models
Paper and Code
Nov 18, 2020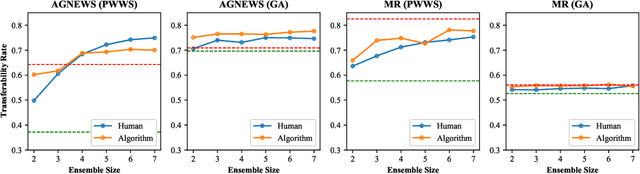


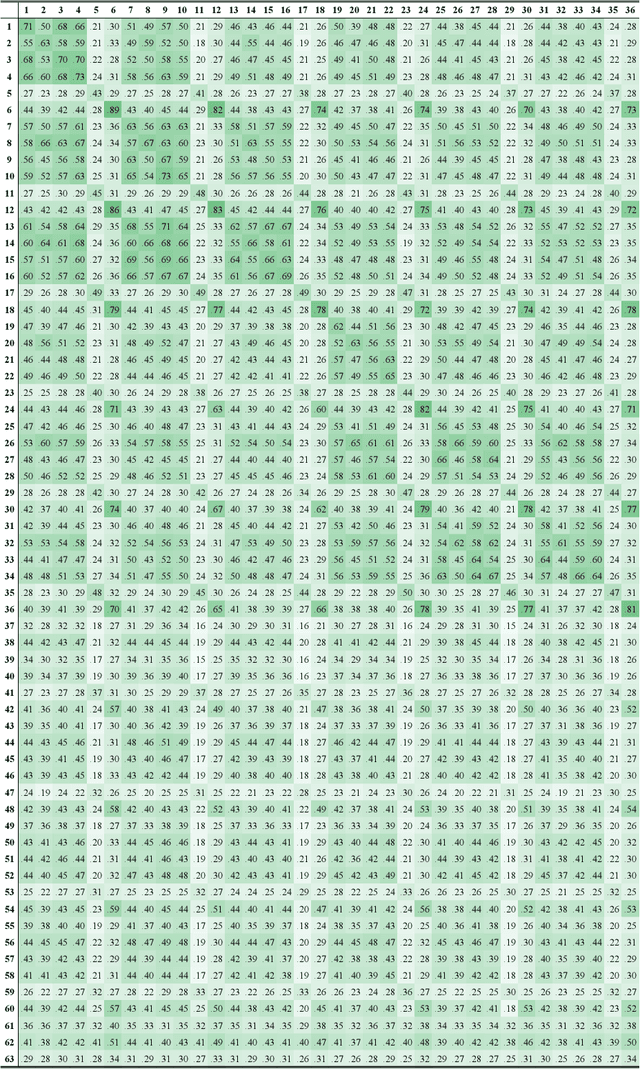
Deep neural network models are vulnerable to adversarial attacks. In many cases, malicious inputs intentionally crafted for one model can fool another model in the black-box attack setting. However, there is a lack of systematic studies on the transferability of adversarial examples and how to generate universal adversarial examples. In this paper, we systematically study the transferability of adversarial attacks for text classification models. In particular, we conduct extensive experiments to investigate how various factors, such as network architecture, input format, word embedding, and model capacity, affect the transferability of adversarial attacks. Based on these studies, we then propose universal black-box attack algorithms that can induce adversarial examples to attack almost all existing models. These universal adversarial examples reflect the defects of the learning process and the bias in the training dataset. Finally, we generalize these adversarial examples into universal word replacement rules that can be used for model diagnostics.