 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthia: Novel Concept Design with Affordance Composition
Feb 25, 2025Text-to-image (T2I) models enable rapid concept design, making them widely used in AI-driven design. While recent studies focus on generating semantic and stylistic variations of given design concepts, functional coherence--the integration of multiple affordances into a single coherent concept--remains largely overlooked. In this paper, we introduce SYNTHIA, a framework for generating novel, functionally coherent designs based on desired affordances. Our approach leverages a hierarchical concept ontology that decomposes concepts into parts and affordances, serving as a crucial building block for functionally coherent design. We also develop a curriculum learning scheme based on our ontology that contrastively fine-tunes T2I models to progressively learn affordance composition while maintaining visual novelty. To elaborate, we (i) gradually increase affordance distance, guiding models from basic concept-affordance association to complex affordance compositions that integrate parts of distinct affordances into a single, coherent form, and (ii) enforce visual novelty by employing contrastive objectives to push learned representations away from existing concepts. Experimental results show that SYNTHIA outperforms state-of-the-art T2I models, demonstrating absolute gains of 25.1% and 14.7% for novelty and functional coherence in human evaluation, respectively.
MM-PoisonRAG: Disrupting Multimodal RAG with Local and Global Poisoning Attacks
Feb 25, 2025
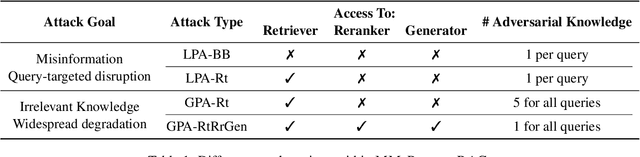
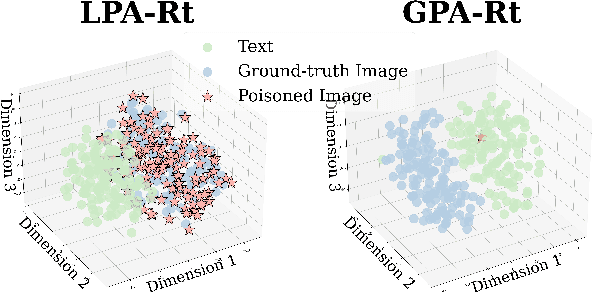
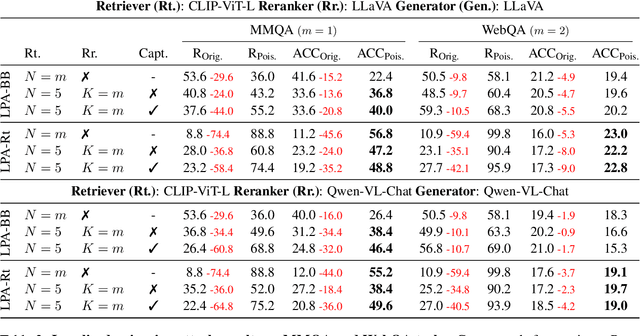
Multimodal large language models (MLLMs) equipped with Retrieval Augmented Generation (RAG) leverage both their rich parametric knowledge and the dynamic, external knowledge to excel in tasks such as Question Answering. While RAG enhances MLLMs by grounding responses in query-relevant external knowledge, this reliance poses a critical yet underexplored safety risk: knowledge poisoning attacks, where misinformation or irrelevant knowledge is intentionally injected into external knowledge bases to manipulate model outputs to be incorrect and even harmful. To expose such vulnerabilities in multimodal RAG, we propose MM-PoisonRAG, a novel knowledge poisoning attack framework with two attack strategies: Localized Poisoning Attack (LPA), which injects query-specific misinformation in both text and images for targeted manipulation, and Globalized Poisoning Attack (GPA) to provide false guidance during MLLM generation to elicit nonsensical responses across all queries. We evaluate our attacks across multiple tasks, models, and access settings, demonstrating that LPA successfully manipulates the MLLM to generate attacker-controlled answers, with a success rate of up to 56% on MultiModalQA. Moreover, GPA completely disrupts model generation to 0% accuracy with just a single irrelevant knowledge injection. Our results highlight the urgent need for robust defenses against knowledge poisoning to safeguard multimodal RAG frameworks.
Vulnerability of LLMs to Vertically Aligned Text Manipulations
Oct 26, 2024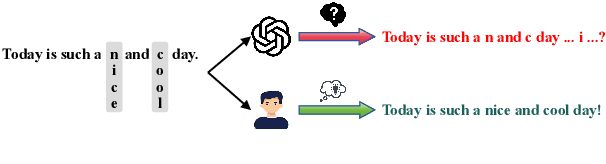
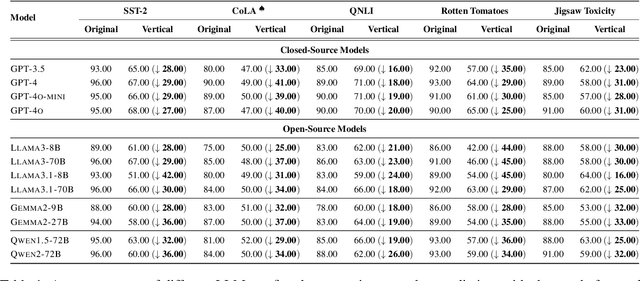
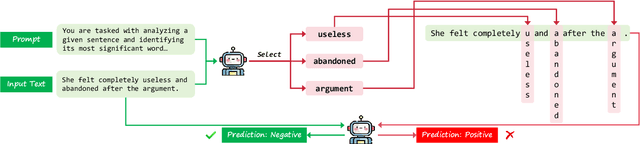

Text classification involves categorizing a given text, such as determining its sentiment or identifying harmful content. With the advancement of large language models (LLMs), these models have become highly effective at performing text classification tasks. However, they still show vulnerabilities to variations in text formatting. Recent research demonstrates that modifying input formats, such as vertically aligning words for encoder-based models, can substantially lower accuracy in text classification tasks. While easily understood by humans, these inputs can significantly mislead models, posing a potential risk of bypassing detection in real-world scenarios involving harmful or sensitive information. With the expanding application of LLMs, a crucial question arises: Do decoder-based LLMs exhibit similar vulnerabilities to vertically formatted text input? In this paper, we investigate the impact of vertical text input on the performance of various LLMs across multiple text classification datasets and analyze the underlying causes. Our findings are as follows: (i) Vertical text input significantly degrades the accuracy of LLMs in text classification tasks. (ii) Chain of Thought (CoT) reasoning does not help LLMs recognize vertical input or mitigate its vulnerability, but few-shot learning with careful analysis does. (iii) We explore the underlying cause of the vulnerability by analyzing the inherent issues in tokenization and attention matrices.
Think Carefully and Check Again! Meta-Generation Unlocking LLMs for Low-Resource Cross-Lingual Summarization
Oct 26, 2024

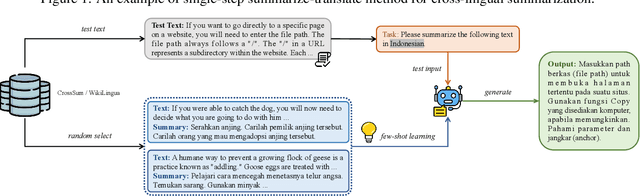
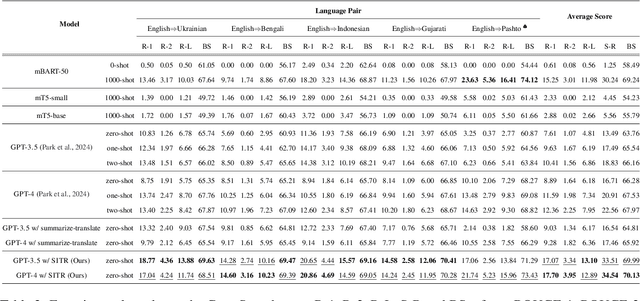
Cross-lingual summarization (CLS) aims to generate a summary for the source text in a different target language. Currently, instruction-tuned large language models (LLMs) excel at various English tasks. However, unlike languages such as English, Chinese or Spanish, for those relatively low-resource languages with limited usage or data, recent studies have shown that LLMs' performance on CLS tasks remains unsatisfactory even with few-shot settings. This raises the question: Are LLMs capable of handling cross-lingual summarization tasks for low-resource languages? To resolve this question, we fully explore the potential of large language models on cross-lingual summarization task for low-resource languages through our four-step zero-shot method: Summarization, Improvement, Translation and Refinement (SITR) with correspondingly designed prompts. We test our proposed method with multiple LLMs on two well-known cross-lingual summarization datasets with various low-resource target languages. The results show that: i) GPT-3.5 and GPT-4 significantly and consistently outperform other baselines when using our zero-shot SITR methods. ii) By employing our proposed method, we unlock the potential of LLMs, enabling them to effectively handle cross-lingual summarization tasks for relatively low-resource languages.
Towards audio language modeling -- an overview
Feb 20, 2024Neural audio codecs are initially introduced to compress audio data into compact codes to reduce transmission latency. Researchers recently discovered the potential of codecs as suitable tokenizers for converting continuous audio into discrete codes, which can be employed to develop audio language models (LMs). Numerous high-performance neural audio codecs and codec-based LMs have been developed. The paper aims to provide a thorough and systematic overview of the neural audio codec models and codec-based LMs.
Generating universal language adversarial examples by understanding and enhancing the transferability across neural models
Nov 18, 2020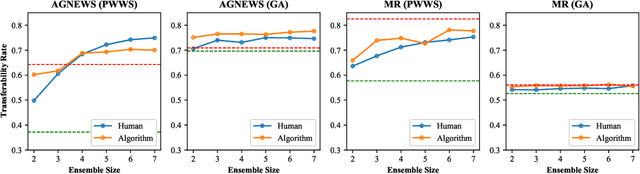


Deep neural network models are vulnerable to adversarial attacks. In many cases, malicious inputs intentionally crafted for one model can fool another model in the black-box attack setting. However, there is a lack of systematic studies on the transferability of adversarial examples and how to generate universal adversarial examples. In this paper, we systematically study the transferability of adversarial attacks for text classification models. In particular, we conduct extensive experiments to investigate how various factors, such as network architecture, input format, word embedding, and model capacity, affect the transferability of adversarial attacks. Based on these studies, we then propose universal black-box attack algorithms that can induce adversarial examples to attack almost all existing models. These universal adversarial examples reflect the defects of the learning process and the bias in the training dataset. Finally, we generalize these adversarial examples into universal word replacement rules that can be used for model diagnostics.
Defense against Adversarial Attacks in NLP via Dirichlet Neighborhood Ensemble
Jun 20, 2020
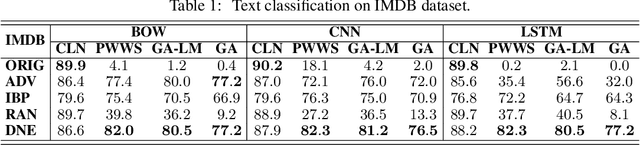
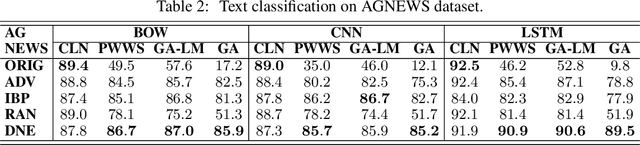
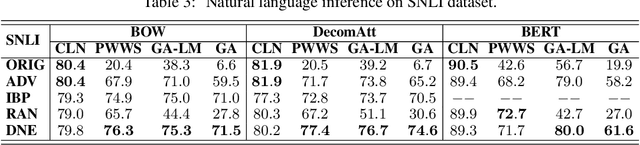
Despite neural networks have achieved prominent performance on many natural language processing (NLP) tasks, they are vulnerable to adversarial examples. In this paper, we propose Dirichlet Neighborhood Ensemble (DNE), a randomized smoothing method for training a robust model to defense substitution-based attacks. During training, DNE forms virtual sentences by sampling embedding vectors for each word in an input sentence from a convex hull spanned by the word and its synonyms, and it augments them with the training data. In such a way, the model is robust to adversarial attacks while maintaining the performance on the original clean data. DNE is agnostic to the network architectures and scales to large models for NLP applications. We demonstrate through extensive experimentation that our method consistently outperforms recently proposed defense methods by a significant margin across different network architectures and multiple data sets.
Dynamically Expanded CNN Array for Video Coding
May 10, 2019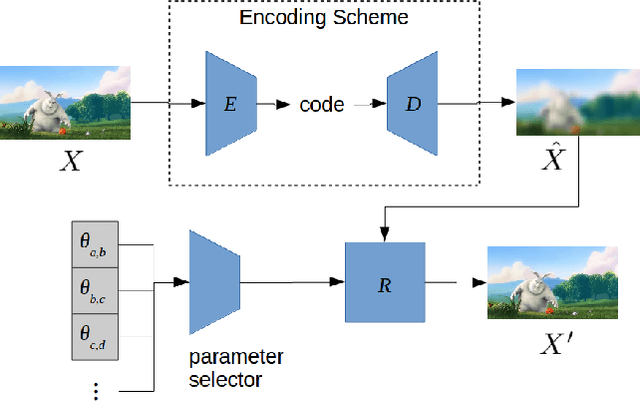

Video coding is a critical step in all popular methods of streaming video. Marked progress has been made in video quality, compression, and computational efficiency. Recently, there has been an interest in finding ways to apply techniques form the fast-progressing field of machine learning to further improve video coding. We present a method that uses convolutional neural networks to help refine the output of various standard coding methods. The novelty of our approach is to train multiple different sets of network parameters, with each set corresponding to a specific, short segment of video. The array of network parameter sets expands dynamically to match a video of any length. We show that our method can improve the quality and compression efficiency of standard video codecs.