 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Carefully and Check Again! Meta-Generation Unlocking LLMs for Low-Resource Cross-Lingual Summarization
Paper and Code


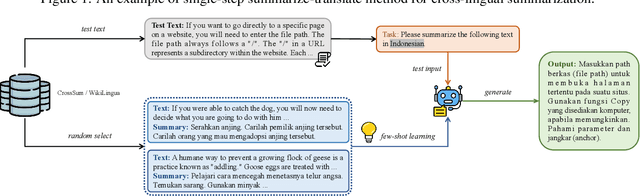
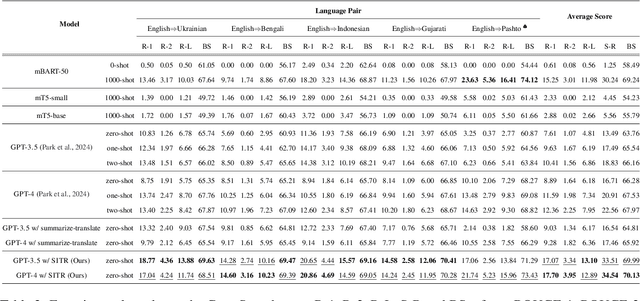
Cross-lingual summarization (CLS) aims to generate a summary for the source text in a different target language. Currently, instruction-tuned large language models (LLMs) excel at various English tasks. However, unlike languages such as English, Chinese or Spanish, for those relatively low-resource languages with limited usage or data, recent studies have shown that LLMs' performance on CLS tasks remains unsatisfactory even with few-shot settings. This raises the question: Are LLMs capable of handling cross-lingual summarization tasks for low-resource languages? To resolve this question, we fully explore the potential of large language models on cross-lingual summarization task for low-resource languages through our four-step zero-shot method: Summarization, Improvement, Translation and Refinement (SITR) with correspondingly designed prompts. We test our proposed method with multiple LLMs on two well-known cross-lingual summarization datasets with various low-resource target languages. The results show that: i) GPT-3.5 and GPT-4 significantly and consistently outperform other baselines when using our zero-shot SITR methods. ii) By employing our proposed method, we unlock the potential of LLMs, enabling them to effectively handle cross-lingual summarization tasks for relatively low-resource languages.