 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-PoisonRAG: Disrupting Multimodal RAG with Local and Global Poisoning Attacks
Feb 25, 2025
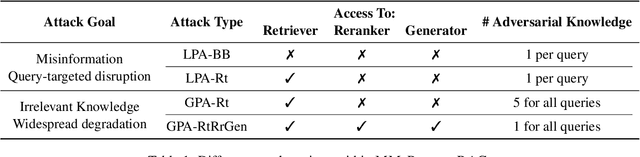
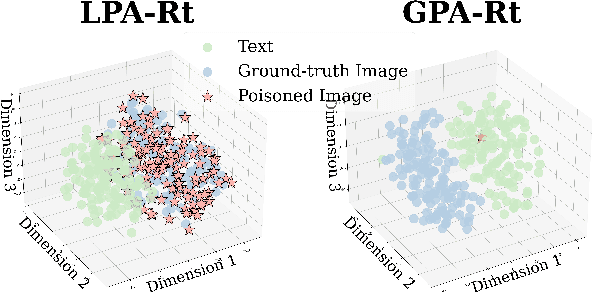
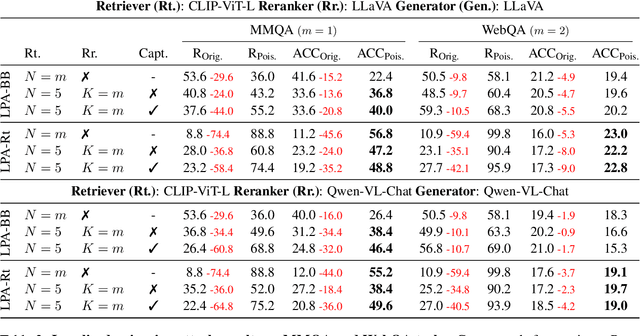
Multimodal large language models (MLLMs) equipped with Retrieval Augmented Generation (RAG) leverage both their rich parametric knowledge and the dynamic, external knowledge to excel in tasks such as Question Answering. While RAG enhances MLLMs by grounding responses in query-relevant external knowledge, this reliance poses a critical yet underexplored safety risk: knowledge poisoning attacks, where misinformation or irrelevant knowledge is intentionally injected into external knowledge bases to manipulate model outputs to be incorrect and even harmful. To expose such vulnerabilities in multimodal RAG, we propose MM-PoisonRAG, a novel knowledge poisoning attack framework with two attack strategies: Localized Poisoning Attack (LPA), which injects query-specific misinformation in both text and images for targeted manipulation, and Globalized Poisoning Attack (GPA) to provide false guidance during MLLM generation to elicit nonsensical responses across all queries. We evaluate our attacks across multiple tasks, models, and access settings, demonstrating that LPA successfully manipulates the MLLM to generate attacker-controlled answers, with a success rate of up to 56% on MultiModalQA. Moreover, GPA completely disrupts model generation to 0% accuracy with just a single irrelevant knowledge injection. Our results highlight the urgent need for robust defenses against knowledge poisoning to safeguard multimodal RAG frameworks.
LoRE: Logit-Ranked Retriever Ensemble for Enhancing Open-Domain Question Answering
Oct 13, 2024Retrieval-based question answering systems often suffer from positional bias, leading to suboptimal answer generation. We propose LoRE (Logit-Ranked Retriever Ensemble), a novel approach that improves answer accuracy and relevance by mitigating positional bias. LoRE employs an ensemble of diverse retrievers, such as BM25 and sentence transformers with FAISS indexing. A key innovation is a logit-based answer ranking algorithm that combines the logit scores from a large language model (LLM), with the retrieval ranks of the passages. Experimental results on NarrativeQA, SQuAD demonstrate that LoRE significantly outperforms existing retrieval-based methods in terms of exact match and F1 scores. On SQuAD, LoRE achieves 14.5\%, 22.83\%, and 14.95\% improvements over the baselines for ROUGE-L, EM, and F1, respectively. Qualitatively, LoRE generates more relevant and accurate answers, especially for complex queries.