 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Time: Dynamic Frame Rate Bottlenecks for Neural Audio Coding
Jun 25, 2026Neural audio autoencoders have become a core component of compression, feature extraction, and generation. However, while existing systems support variable bitrate, the vast majority of models still operate at a fixed latent frame-rate, allocating equal temporal budget to regions with very different information density, which can result in unnecessarily long sequences. We introduce Elastic Time, a dynamic frame-rate bottleneck that converts fixed-frame-rate autoencoders to dynamic ones. Our method learns a lightweight latent predictor used to decide which frames can be skipped and later reconstructed, enabling efficient greedy boundary selection at inference. Experiments show our method enables deployment-time rate control while improving efficiency-quality tradeoffs relative to baselines. Overall, we provide a flexible mechanism for adjusting temporal resolution in audio autoencoders, potentially facilitating more efficient downstream modeling for generation and long-context tasks.
Re-Bottleneck: Latent Re-Structuring for Neural Audio Autoencoders
Jul 10, 2025Neural audio codecs and autoencoders have emerged as versatile models for audio compression, transmission, feature-extraction, and latent-space generation. However, a key limitation is that most are trained to maximize reconstruction fidelity, often neglecting the specific latent structure necessary for optimal performance in diverse downstream applications. We propose a simple, post-hoc framework to address this by modifying the bottleneck of a pre-trained autoencoder. Our method introduces a "Re-Bottleneck", an inner bottleneck trained exclusively through latent space losses to instill user-defined structure. We demonstrate the framework's effectiveness in three experiments. First, we enforce an ordering on latent channels without sacrificing reconstruction quality. Second, we align latents with semantic embeddings, analyzing the impact on downstream diffusion modeling. Third, we introduce equivariance, ensuring that a filtering operation on the input waveform directly corresponds to a specific transformation in the latent space. Ultimately, our Re-Bottleneck framework offers a flexible and efficient way to tailor representations of neural audio models, enabling them to seamlessly meet the varied demands of different applications with minimal additional training.
MM-PoisonRAG: Disrupting Multimodal RAG with Local and Global Poisoning Attacks
Feb 25, 2025
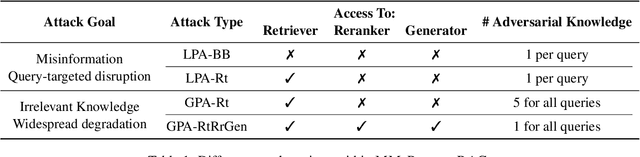
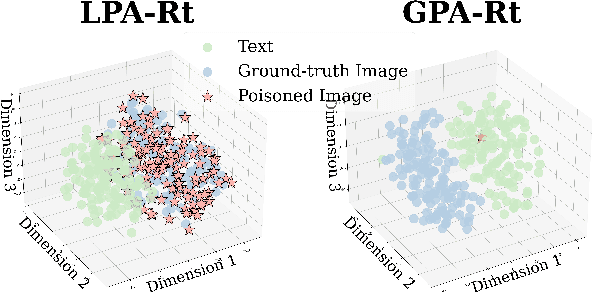
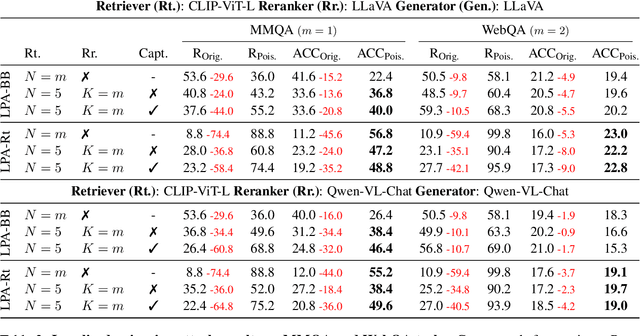
Multimodal large language models (MLLMs) equipped with Retrieval Augmented Generation (RAG) leverage both their rich parametric knowledge and the dynamic, external knowledge to excel in tasks such as Question Answering. While RAG enhances MLLMs by grounding responses in query-relevant external knowledge, this reliance poses a critical yet underexplored safety risk: knowledge poisoning attacks, where misinformation or irrelevant knowledge is intentionally injected into external knowledge bases to manipulate model outputs to be incorrect and even harmful. To expose such vulnerabilities in multimodal RAG, we propose MM-PoisonRAG, a novel knowledge poisoning attack framework with two attack strategies: Localized Poisoning Attack (LPA), which injects query-specific misinformation in both text and images for targeted manipulation, and Globalized Poisoning Attack (GPA) to provide false guidance during MLLM generation to elicit nonsensical responses across all queries. We evaluate our attacks across multiple tasks, models, and access settings, demonstrating that LPA successfully manipulates the MLLM to generate attacker-controlled answers, with a success rate of up to 56% on MultiModalQA. Moreover, GPA completely disrupts model generation to 0% accuracy with just a single irrelevant knowledge injection. Our results highlight the urgent need for robust defenses against knowledge poisoning to safeguard multimodal RAG frameworks.
Generation or Replication: Auscultating Audio Latent Diffusion Models
Oct 16, 2023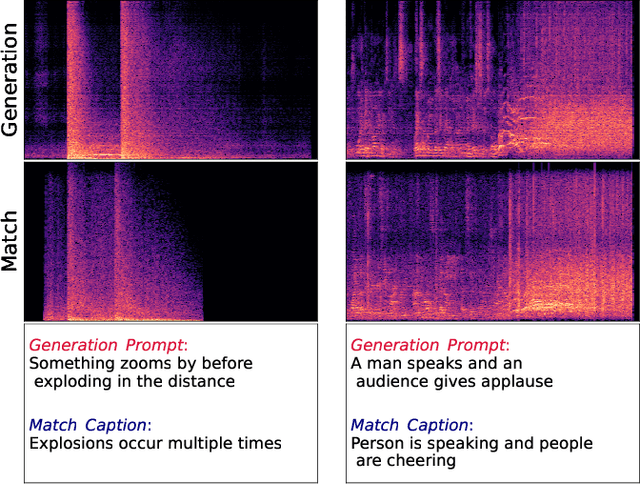
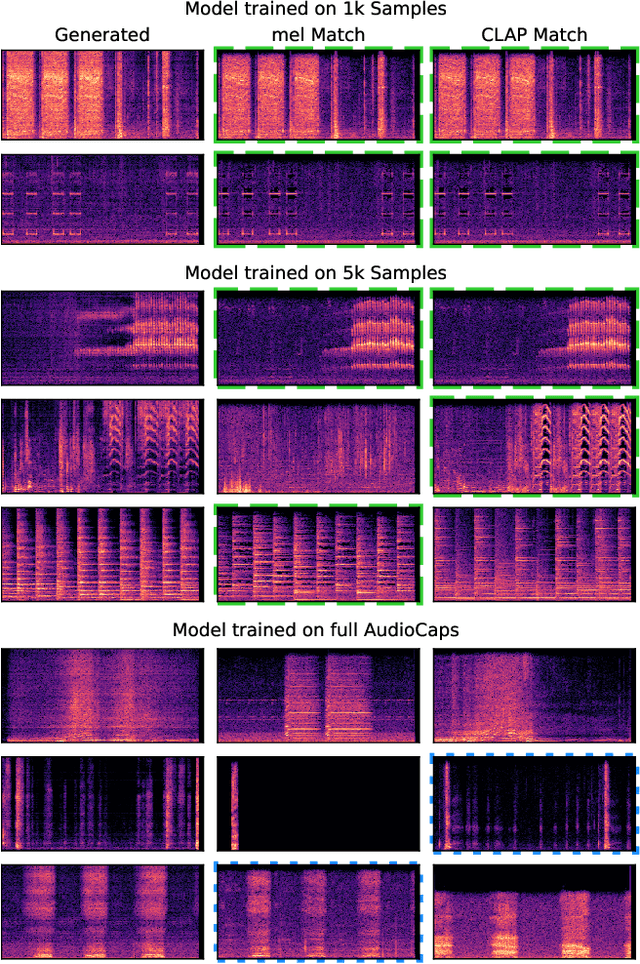
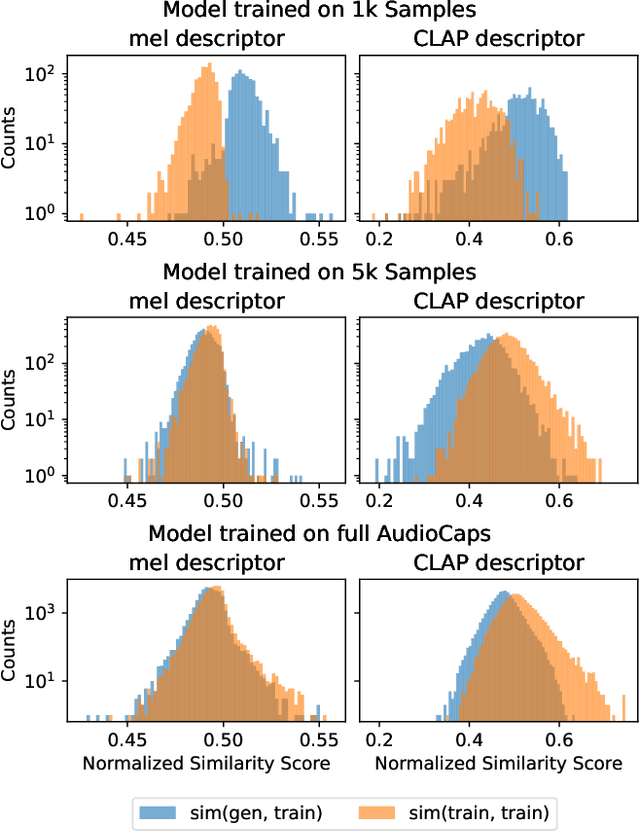
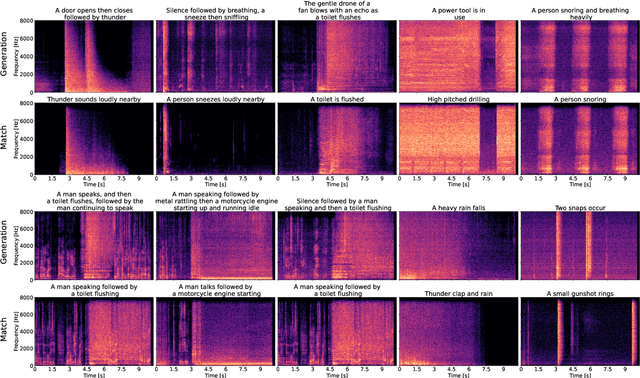
The introduction of audio latent diffusion models possessing the ability to generate realistic sound clips on demand from a text description has the potential to revolutionize how we work with audio. In this work, we make an initial attempt at understanding the inner workings of audio latent diffusion models by investigating how their audio outputs compare with the training data, similar to how a doctor auscultates a patient by listening to the sounds of their organs. Using text-to-audio latent diffusion models trained on the AudioCaps dataset, we systematically analyze memorization behavior as a function of training set size. We also evaluate different retrieval metrics for evidence of training data memorization, finding the similarity between mel spectrograms to be more robust in detecting matches than learned embedding vectors. In the process of analyzing memorization in audio latent diffusion models, we also discover a large amount of duplicated audio clips within the AudioCaps database.
Complete and separate: Conditional separation with missing target source attribute completion
Jul 27, 2023



Recent approaches in source separation leverage semantic information about their input mixtures and constituent sources that when used in conditional separation models can achieve impressive performance. Most approaches along these lines have focused on simple descriptions, which are not always useful for varying types of input mixtures. In this work, we present an approach in which a model, given an input mixture and partial semantic information about a target source, is trained to extract additional semantic data. We then leverage this pre-trained model to improve the separation performance of an uncoupled multi-conditional separation network. Our experiments demonstrate that the separation performance of this multi-conditional model is significantly improved, approaching the performance of an oracle model with complete semantic information. Furthermore, our approach achieves performance levels that are comparable to those of the best performing specialized single conditional models, thus providing an easier to use alternative.
Latent Iterative Refinement for Modular Source Separation
Nov 22, 2022Traditional source separation approaches train deep neural network models end-to-end with all the data available at once by minimizing the empirical risk on the whole training set. On the inference side, after training the model, the user fetches a static computation graph and runs the full model on some specified observed mixture signal to get the estimated source signals. Additionally, many of those models consist of several basic processing blocks which are applied sequentially. We argue that we can significantly increase resource efficiency during both training and inference stages by reformulating a model's training and inference procedures as iterative mappings of latent signal representations. First, we can apply the same processing block more than once on its output to refine the input signal and consequently improve parameter efficiency. During training, we can follow a block-wise procedure which enables a reduction on memory requirements. Thus, one can train a very complicated network structure using significantly less computation compared to end-to-end training. During inference, we can dynamically adjust how many processing blocks and iterations of a specific block an input signal needs using a gating module.
Unified Gradient Reweighting for Model Biasing with Applications to Source Separation
Oct 25, 2020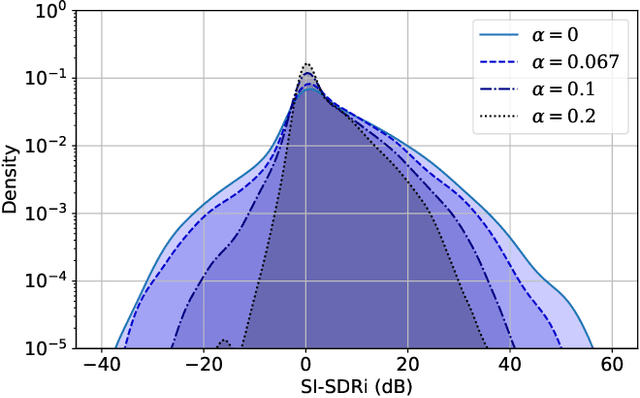

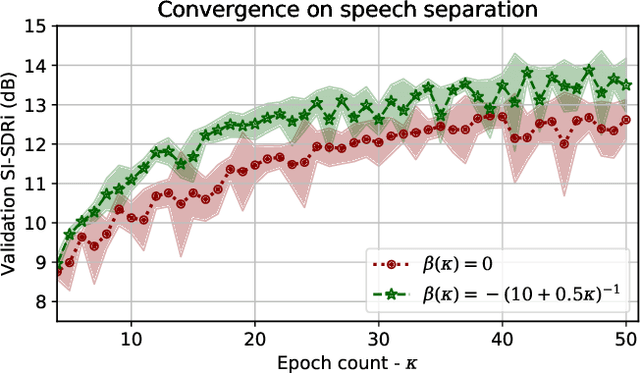
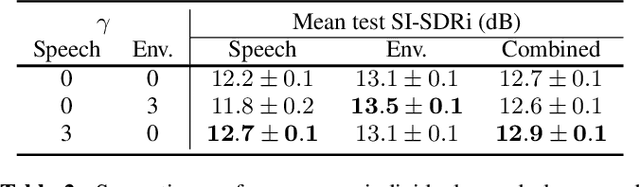
Recent deep learning approaches have shown great improvement in audio source separation tasks. However, the vast majority of such work is focused on improving average separation performance, often neglecting to examine or control the distribution of the results. In this paper, we propose a simple, unified gradient reweighting scheme, with a lightweight modification to bias the learning process of a model and steer it towards a certain distribution of results. More specifically, we reweight the gradient updates of each batch, using a user-specified probability distribution. We apply this method to various source separation tasks, in order to shift the operating point of the models towards different objectives. We demonstrate different parameterizations of our unified reweighting scheme can be used towards addressing several real-world problems, such as unreliable separation estimates. Our framework enables the user to control a robustness trade-off between worst and average performance. Moreover, we experimentally show that our unified reweighting scheme can also be used in order to shift the focus of the model towards being more accurate for user-specified sound classes or even towards easier examples in order to enable faster convergence.