 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Backdoor Attacks on MLLM Embodied Decision Making via Contrastive Trigger Learning
Oct 31, 2025Multimodal large language models (MLLMs) have advanced embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into MLLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and MLLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in MLLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
MM-PoisonRAG: Disrupting Multimodal RAG with Local and Global Poisoning Attacks
Feb 25, 2025
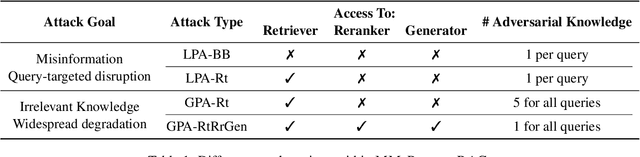
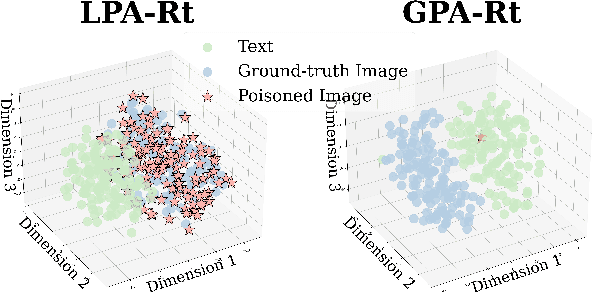
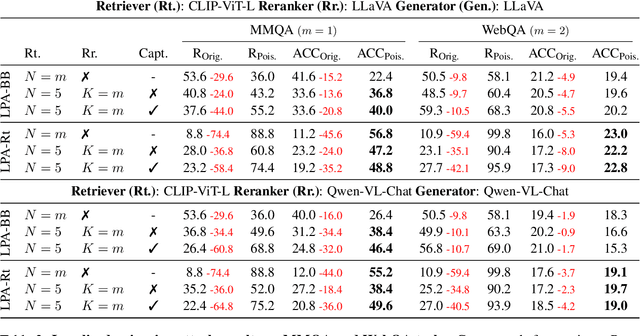
Multimodal large language models (MLLMs) equipped with Retrieval Augmented Generation (RAG) leverage both their rich parametric knowledge and the dynamic, external knowledge to excel in tasks such as Question Answering. While RAG enhances MLLMs by grounding responses in query-relevant external knowledge, this reliance poses a critical yet underexplored safety risk: knowledge poisoning attacks, where misinformation or irrelevant knowledge is intentionally injected into external knowledge bases to manipulate model outputs to be incorrect and even harmful. To expose such vulnerabilities in multimodal RAG, we propose MM-PoisonRAG, a novel knowledge poisoning attack framework with two attack strategies: Localized Poisoning Attack (LPA), which injects query-specific misinformation in both text and images for targeted manipulation, and Globalized Poisoning Attack (GPA) to provide false guidance during MLLM generation to elicit nonsensical responses across all queries. We evaluate our attacks across multiple tasks, models, and access settings, demonstrating that LPA successfully manipulates the MLLM to generate attacker-controlled answers, with a success rate of up to 56% on MultiModalQA. Moreover, GPA completely disrupts model generation to 0% accuracy with just a single irrelevant knowledge injection. Our results highlight the urgent need for robust defenses against knowledge poisoning to safeguard multimodal RAG frameworks.
Teams of LLM Agents can Exploit Zero-Day Vulnerabilities
Jun 02, 2024



LLM agents have become increasingly sophisticated, especially in the realm of cybersecurity. Researchers have shown that LLM agents can exploit real-world vulnerabilities when given a description of the vulnerability and toy capture-the-flag problems. However, these agents still perform poorly on real-world vulnerabilities that are unknown to the agent ahead of time (zero-day vulnerabilities). In this work, we show that teams of LLM agents can exploit real-world, zero-day vulnerabilities. Prior agents struggle with exploring many different vulnerabilities and long-range planning when used alone. To resolve this, we introduce HPTSA, a system of agents with a planning agent that can launch subagents. The planning agent explores the system and determines which subagents to call, resolving long-term planning issues when trying different vulnerabilities. We construct a benchmark of 15 real-world vulnerabilities and show that our team of agents improve over prior work by up to 4.5$\times$.
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Mar 05, 2024



Recent work has embodied LLMs as agents, allowing them to access tools, perform actions, and interact with external content (e.g., emails or websites). However, external content introduces the risk of indirect prompt injection (IPI) attacks, where malicious instructions are embedded within the content processed by LLMs, aiming to manipulate these agents into executing detrimental actions against users. Given the potentially severe consequences of such attacks, establishing benchmarks to assess and mitigate these risks is imperative. In this work, we introduce InjecAgent, a benchmark designed to assess the vulnerability of tool-integrated LLM agents to IPI attacks. InjecAgent comprises 1,054 test cases covering 17 different user tools and 62 attacker tools. We categorize attack intentions into two primary types: direct harm to users and exfiltration of private data. We evaluate 30 different LLM agents and show that agents are vulnerable to IPI attacks, with ReAct-prompted GPT-4 vulnerable to attacks 24% of the time. Further investigation into an enhanced setting, where the attacker instructions are reinforced with a hacking prompt, shows additional increases in success rates, nearly doubling the attack success rate on the ReAct-prompted GPT-4. Our findings raise questions about the widespread deployment of LLM Agents. Our benchmark is available at https://github.com/uiuc-kang-lab/InjecAgent.
LLM Agents can Autonomously Hack Websites
Feb 16, 2024



In recent years, large language models (LLMs) have become increasingly capable and can now interact with tools (i.e., call functions), read documents, and recursively call themselves. As a result, these LLMs can now function autonomously as agents. With the rise in capabilities of these agents, recent work has speculated on how LLM agents would affect cybersecurity. However, not much is known about the offensive capabilities of LLM agents. In this work, we show that LLM agents can autonomously hack websites, performing tasks as complex as blind database schema extraction and SQL injections without human feedback. Importantly, the agent does not need to know the vulnerability beforehand. This capability is uniquely enabled by frontier models that are highly capable of tool use and leveraging extended context. Namely, we show that GPT-4 is capable of such hacks, but existing open-source models are not. Finally, we show that GPT-4 is capable of autonomously finding vulnerabilities in websites in the wild. Our findings raise questions about the widespread deployment of LLMs.
Removing RLHF Protections in GPT-4 via Fine-Tuning
Nov 10, 2023As large language models (LLMs) have increased in their capabilities, so does their potential for dual use. To reduce harmful outputs, produces and vendors of LLMs have used reinforcement learning with human feedback (RLHF). In tandem, LLM vendors have been increasingly enabling fine-tuning of their most powerful models. However, concurrent work has shown that fine-tuning can remove RLHF protections. We may expect that the most powerful models currently available (GPT-4) are less susceptible to fine-tuning attacks. In this work, we show the contrary: fine-tuning allows attackers to remove RLHF protections with as few as 340 examples and a 95% success rate. These training examples can be automatically generated with weaker models. We further show that removing RLHF protections does not decrease usefulness on non-censored outputs, providing evidence that our fine-tuning strategy does not decrease usefulness despite using weaker models to generate training data. Our results show the need for further research on protections on LLMs.
GLEN: General-Purpose Event Detection for Thousands of Types
Mar 20, 2023



The development of event extraction systems has been hindered by the absence of wide-coverage, large-scale datasets. To make event extraction systems more accessible, we build a general-purpose event detection dataset GLEN, which covers 3,465 different event types, making it over 20x larger in ontology than any current dataset. GLEN is created by utilizing the DWD Overlay, which provides a mapping between Wikidata Qnodes and PropBank rolesets. This enables us to use the abundant existing annotation for PropBank as distant supervision. In addition, we also propose a new multi-stage event detection model specifically designed to handle the large ontology size and partial labels in GLEN. We show that our model exhibits superior performance (~10% F1 gain) compared to both conventional classification baselines and newer definition-based models. Finally, we perform error analysis and show that label noise is still the largest challenge for improving performance.
ConFiguRe: Exploring Discourse-level Chinese Figures of Speech
Sep 16, 2022
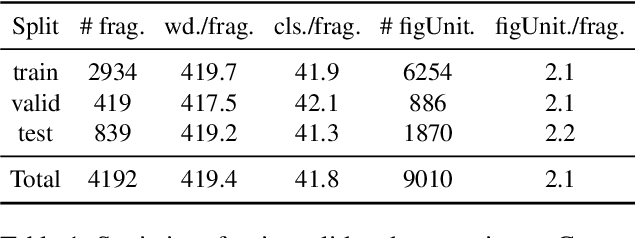

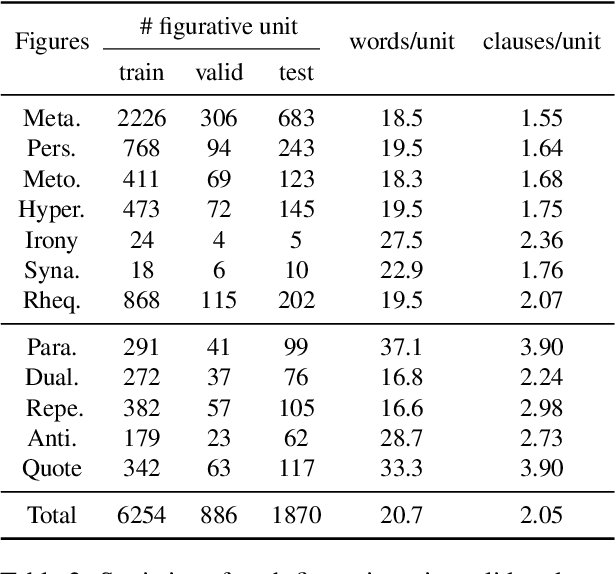
Figures of speech, such as metaphor and irony, are ubiquitous in literature works and colloquial conversations. This poses great challenge for natural language understanding since figures of speech usually deviate from their ostensible meanings to express deeper semantic implications. Previous research lays emphasis on the literary aspect of figures and seldom provide a comprehensive exploration from a view of computational linguistics. In this paper, we first propose the concept of figurative unit, which is the carrier of a figure. Then we select 12 types of figures commonly used in Chinese, and build a Chinese corpus for Contextualized Figure Recognition (ConFiguRe). Different from previous token-level or sentence-level counterparts, ConFiguRe aims at extracting a figurative unit from discourse-level context, and classifying the figurative unit into the right figure type. On ConFiguRe, three tasks, i.e., figure extraction, figure type classification and figure recognition, are designed and the state-of-the-art techniques are utilized to implement the benchmarks. We conduct thorough experiments and show that all three tasks are challenging for existing models, thus requiring further research. Our dataset and code are publicly available at https://github.com/pku-tangent/ConFiguRe.
EA$^2$E: Improving Consistency with Event Awareness for Document-Level Argument Extraction
May 30, 2022



Events are inter-related in documents. Motivated by the one-sense-per-discourse theory, we hypothesize that a participant tends to play consistent roles across multiple events in the same document. However recent work on document-level event argument extraction models each individual event in isolation and therefore causes inconsistency among extracted arguments across events, which will further cause discrepancy for downstream applications such as event knowledge base population, question answering, and hypothesis generation. In this work, we formulate event argument consistency as the constraints from event-event relations under the document-level setting. To improve consistency we introduce the Event-Aware Argument Extraction (EA$^2$E) model with augmented context for training and inference. Experiment results on WIKIEVENTS and ACE2005 datasets demonstrate the effectiveness of EA$^2$E compared to baseline methods.