 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavThinker: Action-Conditioned World Models for Coupled Prediction and Planning in Social Navigation
Mar 16, 2026Social navigation requires robots to act safely in dynamic human environments. Effective behavior demands thinking ahead: reasoning about how the scene and pedestrians evolve under different robot actions rather than reacting to current observations alone. This creates a coupled prediction-planning challenge, where robot actions and human motion mutually influence each other. To address this challenge, we propose NavThinker, a future-aware framework that couples an action-conditioned world model with on-policy reinforcement learning. The world model operates in the Depth Anything V2 patch feature space and performs autoregressive prediction of future scene geometry and human motion; multi-head decoders then produce future depth maps and human trajectories, yielding a future-aware state aligned with traversability and interaction risk. Crucially, we train the policy with DD-PPO while injecting world-model think-ahead signals via: (i) action-conditioned future features fused into the current observation embedding and (ii) social reward shaping from predicted human trajectories. Experiments on single- and multi-robot Social-HM3D show state-of-the-art navigation success, with zero-shot transfer to Social-MP3D and real-world deployment on a Unitree Go2, validating generalization and practical applicability. Webpage: https://github.com/hutslib/NavThinker.
Atlas-Assisted Segment Anything Model for Fetal Brain MRI (FeTal-SAM)
Jan 22, 2026This paper presents FeTal-SAM, a novel adaptation of the Segment Anything Model (SAM) tailored for fetal brain MRI segmentation. Traditional deep learning methods often require large annotated datasets for a fixed set of labels, making them inflexible when clinical or research needs change. By integrating atlas-based prompts and foundation-model principles, FeTal-SAM addresses two key limitations in fetal brain MRI segmentation: (1) the need to retrain models for varying label definitions, and (2) the lack of insight into whether segmentations are driven by genuine image contrast or by learned spatial priors. We leverage multi-atlas registration to generate spatially aligned label templates that serve as dense prompts, alongside a bounding-box prompt, for SAM's segmentation decoder. This strategy enables binary segmentation on a per-structure basis, which is subsequently fused to reconstruct the full 3D segmentation volumes. Evaluations on two datasets, the dHCP dataset and an in-house dataset demonstrate FeTal-SAM's robust performance across gestational ages. Notably, it achieves Dice scores comparable to state-of-the-art baselines which were trained for each dataset and label definition for well-contrasted structures like cortical plate and cerebellum, while maintaining the flexibility to segment any user-specified anatomy. Although slightly lower accuracy is observed for subtle, low-contrast structures (e.g., hippocampus, amygdala), our results highlight FeTal-SAM's potential to serve as a general-purpose segmentation model without exhaustive retraining. This method thus constitutes a promising step toward clinically adaptable fetal brain MRI analysis tools.
Explicit Temporal-Semantic Modeling for Dense Video Captioning via Context-Aware Cross-Modal Interaction
Nov 13, 2025Dense video captioning jointly localizes and captions salient events in untrimmed videos. Recent methods primarily focus on leveraging additional prior knowledge and advanced multi-task architectures to achieve competitive performance. However, these pipelines rely on implicit modeling that uses frame-level or fragmented video features, failing to capture the temporal coherence across event sequences and comprehensive semantics within visual contexts. To address this, we propose an explicit temporal-semantic modeling framework called Context-Aware Cross-Modal Interaction (CACMI), which leverages both latent temporal characteristics within videos and linguistic semantics from text corpus. Specifically, our model consists of two core components: Cross-modal Frame Aggregation aggregates relevant frames to extract temporally coherent, event-aligned textual features through cross-modal retrieval; and Context-aware Feature Enhancement utilizes query-guided attention to integrate visual dynamics with pseudo-event semantics. Extensive experiments on the ActivityNet Captions and YouCook2 datasets demonstrate that CACMI achieves the state-of-the-art performance on dense video captioning task.
Efficient Forward-Only Data Valuation for Pretrained LLMs and VLMs
Aug 13, 2025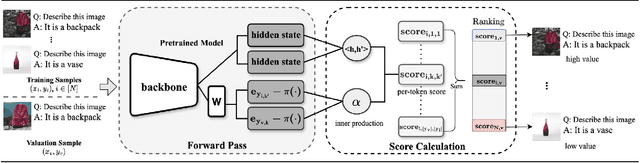
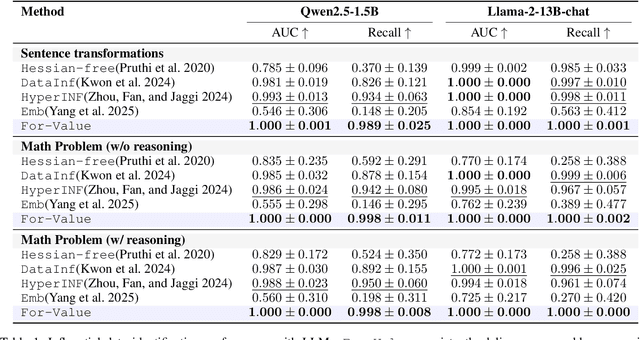
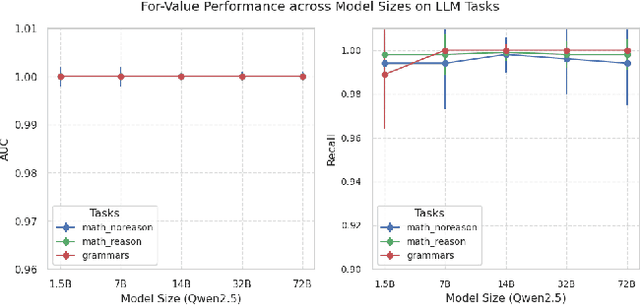
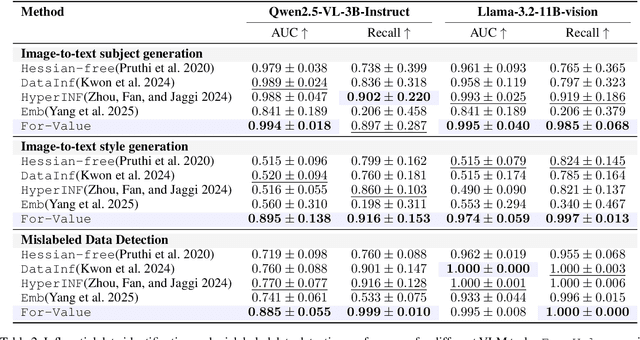
Quantifying the influence of individual training samples is essential for enhancing the transparency and accountability of large language models (LLMs) and vision-language models (VLMs). However, existing data valuation methods often rely on Hessian information or model retraining, making them computationally prohibitive for billion-parameter models. In this work, we introduce For-Value, a forward-only data valuation framework that enables scalable and efficient influence estimation for both LLMs and VLMs. By leveraging the rich representations of modern foundation models, For-Value computes influence scores using a simple closed-form expression based solely on a single forward pass, thereby eliminating the need for costly gradient computations. Our theoretical analysis demonstrates that For-Value accurately estimates per-sample influence by capturing alignment in hidden representations and prediction errors between training and validation samples. Extensive experiments show that For-Value matches or outperforms gradient-based baselines in identifying impactful fine-tuning examples and effectively detecting mislabeled data.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025



Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
FetDTIAlign: A Deep Learning Framework for Affine and Deformable Registration of Fetal Brain dMRI
Feb 03, 2025Diffusion MRI (dMRI) provides unique insights into fetal brain microstructure in utero. Longitudinal and cross-sectional fetal dMRI studies can reveal crucial neurodevelopmental changes but require precise spatial alignment across scans and subjects. This is challenging due to low data quality, rapid brain development, and limited anatomical landmarks. Existing registration methods, designed for high-quality adult data, struggle with these complexities. To address this, we introduce FetDTIAlign, a deep learning approach for fetal brain dMRI registration, enabling accurate affine and deformable alignment. FetDTIAlign features a dual-encoder architecture and iterative feature-based inference, reducing the impact of noise and low resolution. It optimizes network configurations and domain-specific features at each registration stage, enhancing both robustness and accuracy. We validated FetDTIAlign on data from 23 to 36 weeks gestation, covering 60 white matter tracts. It consistently outperformed two classical optimization-based methods and a deep learning pipeline, achieving superior anatomical correspondence. Further validation on external data from the Developing Human Connectome Project confirmed its generalizability across acquisition protocols. Our results demonstrate the feasibility of deep learning for fetal brain dMRI registration, providing a more accurate and reliable alternative to classical techniques. By enabling precise cross-subject and tract-specific analyses, FetDTIAlign supports new discoveries in early brain development.
GAD-Generative Learning for HD Map-Free Autonomous Driving
May 01, 2024



Deep-learning-based techniques have been widely adopted for autonomous driving software stacks for mass production in recent years, focusing primarily on perception modules, with some work extending this method to prediction modules. However, the downstream planning and control modules are still designed with hefty handcrafted rules, dominated by optimization-based methods such as quadratic programming or model predictive control. This results in a performance bottleneck for autonomous driving systems in that corner cases simply cannot be solved by enumerating hand-crafted rules. We present a deep-learning-based approach that brings prediction, decision, and planning modules together with the attempt to overcome the rule-based methods' deficiency in real-world applications of autonomous driving, especially for urban scenes. The DNN model we proposed is solely trained with 10 hours of human driver data, and it supports all mass-production ADAS features available on the market to date. This method is deployed onto a Jiyue test car with no modification to its factory-ready sensor set and compute platform. the feasibility, usability, and commercial potential are demonstrated in this article.
C-PMI: Conditional Pointwise Mutual Information for Turn-level Dialogue Evaluation
Jun 27, 2023
Existing reference-free turn-level evaluation metrics for chatbots inadequately capture the interaction between the user and the system. Consequently, they often correlate poorly with human evaluations. To address this issue, we propose a novel model-agnostic approach that leverages Conditional Pointwise Mutual Information (C-PMI) to measure the turn-level interaction between the system and the user based on a given evaluation dimension. Experimental results on the widely used FED dialogue evaluation dataset demonstrate that our approach significantly improves the correlation with human judgment compared with existing evaluation systems. By replacing the negative log-likelihood-based scorer with our proposed C-PMI scorer, we achieve a relative 60.5% higher Spearman correlation on average for the FED evaluation metric. Our code is publicly available at https://github.com/renll/C-PMI.
Towards Fairness in Personalized Ads Using Impression Variance Aware Reinforcement Learning
Jun 08, 2023



Variances in ad impression outcomes across demographic groups are increasingly considered to be potentially indicative of algorithmic bias in personalized ads systems. While there are many definitions of fairness that could be applicable in the context of personalized systems, we present a framework which we call the Variance Reduction System (VRS) for achieving more equitable outcomes in Meta's ads systems. VRS seeks to achieve a distribution of impressions with respect to selected protected class (PC) attributes that more closely aligns the demographics of an ad's eligible audience (a function of advertiser targeting criteria) with the audience who sees that ad, in a privacy-preserving manner. We first define metrics to quantify fairness gaps in terms of ad impression variances with respect to PC attributes including gender and estimated race. We then present the VRS for re-ranking ads in an impression variance-aware manner. We evaluate VRS via extensive simulations over different parameter choices and study the effect of the VRS on the chosen fairness metric. We finally present online A/B testing results from applying VRS to Meta's ads systems, concluding with a discussion of future work. We have deployed the VRS to all users in the US for housing ads, resulting in significant improvement in our fairness metric. VRS is the first large-scale deployed framework for pursuing fairness for multiple PC attributes in online advertising.
Meta-review Generation with Checklist-guided Iterative Introspection
May 24, 2023Opinions in the scientific domain can be divergent, leading to controversy or consensus among reviewers. However, current opinion summarization datasets mostly focus on product review domains, which do not account for this variability under the assumption that the input opinions are non-controversial. To address this gap, we propose the task of scientific opinion summarization, where research paper reviews are synthesized into meta-reviews. To facilitate this task, we introduce a new ORSUM dataset covering 10,989 paper meta-reviews and 40,903 paper reviews from 39 conferences. Furthermore, we propose the Checklist-guided Iterative Introspection (CGI$^2$) approach, which breaks down the task into several stages and iteratively refines the summary under the guidance of questions from a checklist. We conclude that (1) human-written summaries are not always reliable since many do not follow the guideline, and (2) the combination of task decomposition and iterative self-refinement shows promising discussion involvement ability and can be applied to other complex text generation using black-box LLM.