 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Environments for LLM Agents in the Era of Learning from Interaction: A Survey
Nov 12, 2025LLM-based agents can autonomously accomplish complex tasks across various domains. However, to further cultivate capabilities such as adaptive behavior and long-term decision-making, training on static datasets built from human-level knowledge is insufficient. These datasets are costly to construct and lack both dynamism and realism. A growing consensus is that agents should instead interact directly with environments and learn from experience through reinforcement learning. We formalize this iterative process as the Generation-Execution-Feedback (GEF) loop, where environments generate tasks to challenge agents, return observations in response to agents' actions during task execution, and provide evaluative feedback on rollouts for subsequent learning. Under this paradigm, environments function as indispensable producers of experiential data, highlighting the need to scale them toward greater complexity, realism, and interactivity. In this survey, we systematically review representative methods for environment scaling from a pioneering environment-centric perspective and organize them along the stages of the GEF loop, namely task generation, task execution, and feedback. We further analyze benchmarks, implementation strategies, and applications, consolidating fragmented advances and outlining future research directions for agent intelligence.
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025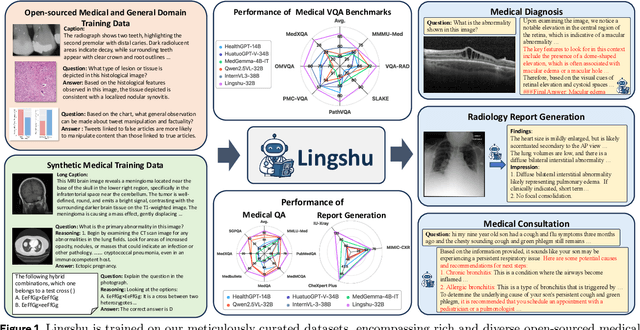
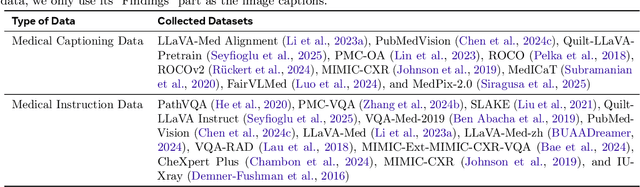
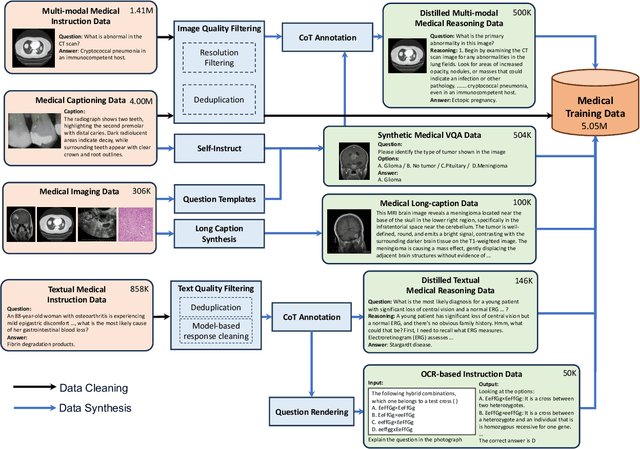

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
Analyzing LLMs' Knowledge Boundary Cognition Across Languages Through the Lens of Internal Representations
Apr 18, 2025While understanding the knowledge boundaries of LLMs is crucial to prevent hallucination, research on knowledge boundaries of LLMs has predominantly focused on English. In this work, we present the first study to analyze how LLMs recognize knowledge boundaries across different languages by probing their internal representations when processing known and unknown questions in multiple languages. Our empirical studies reveal three key findings: 1) LLMs' perceptions of knowledge boundaries are encoded in the middle to middle-upper layers across different languages. 2) Language differences in knowledge boundary perception follow a linear structure, which motivates our proposal of a training-free alignment method that effectively transfers knowledge boundary perception ability across languages, thereby helping reduce hallucination risk in low-resource languages; 3) Fine-tuning on bilingual question pair translation further enhances LLMs' recognition of knowledge boundaries across languages. Given the absence of standard testbeds for cross-lingual knowledge boundary analysis, we construct a multilingual evaluation suite comprising three representative types of knowledge boundary data. Our code and datasets are publicly available at https://github.com/DAMO-NLP-SG/LLM-Multilingual-Knowledge-Boundaries.
FINEREASON: Evaluating and Improving LLMs' Deliberate Reasoning through Reflective Puzzle Solving
Feb 27, 2025



Many challenging reasoning tasks require not just rapid, intuitive responses, but a more deliberate, multi-step approach. Recent progress in large language models (LLMs) highlights an important shift from the "System 1" way of quick reactions to the "System 2" style of reflection-and-correction problem solving. However, current benchmarks heavily rely on the final-answer accuracy, leaving much of a model's intermediate reasoning steps unexamined. This fails to assess the model's ability to reflect and rectify mistakes within the reasoning process. To bridge this gap, we introduce FINEREASON, a logic-puzzle benchmark for fine-grained evaluation of LLMs' reasoning capabilities. Each puzzle can be decomposed into atomic steps, making it ideal for rigorous validation of intermediate correctness. Building on this, we introduce two tasks: state checking, and state transition, for a comprehensive evaluation of how models assess the current situation and plan the next move. To support broader research, we also provide a puzzle training set aimed at enhancing performance on general mathematical tasks. We show that models trained on our state checking and transition data demonstrate gains in math reasoning by up to 5.1% on GSM8K.
M-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework
Nov 09, 2024
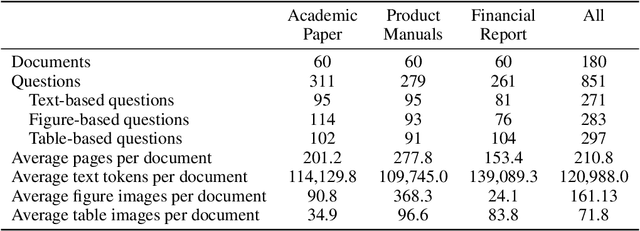
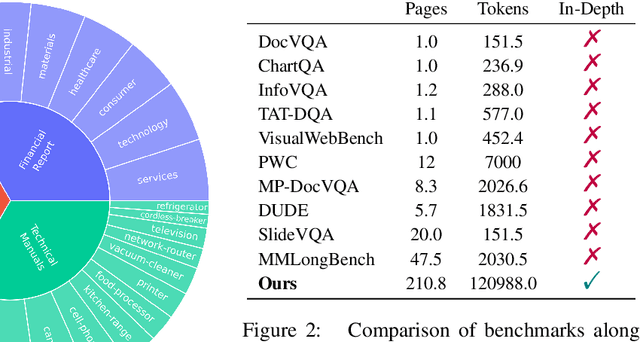
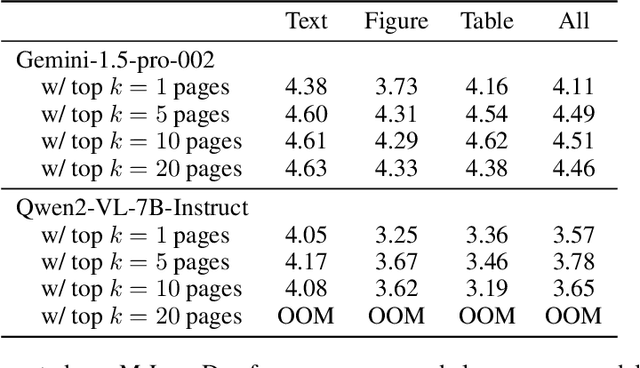
The ability to understand and answer questions over documents can be useful in many business and practical applications. However, documents often contain lengthy and diverse multimodal contents such as texts, figures, and tables, which are very time-consuming for humans to read thoroughly. Hence, there is an urgent need to develop effective and automated methods to aid humans in this task. In this work, we introduce M-LongDoc, a benchmark of 851 samples, and an automated framework to evaluate the performance of large multimodal models. We further propose a retrieval-aware tuning approach for efficient and effective multimodal document reading. Compared to existing works, our benchmark consists of more recent and lengthy documents with hundreds of pages, while also requiring open-ended solutions and not just extractive answers. To our knowledge, our training framework is the first to directly address the retrieval setting for multimodal long documents. To enable tuning open-source models, we construct a training corpus in a fully automatic manner for the question-answering task over such documents. Experiments show that our tuning approach achieves a relative improvement of 4.6% for the correctness of model responses, compared to the baseline open-source models. Our data, code, and models are available at https://multimodal-documents.github.io.
VisAidMath: Benchmarking Visual-Aided Mathematical Reasoning
Oct 30, 2024



Although previous research on large language models (LLMs) and large multi-modal models (LMMs) has systematically explored mathematical problem-solving (MPS) within visual contexts, the analysis of how these models process visual information during problem-solving remains insufficient. To address this gap, we present VisAidMath, a benchmark for evaluating the MPS process related to visual information. We follow a rigorous data curation pipeline involving both automated processes and manual annotations to ensure data quality and reliability. Consequently, this benchmark includes 1,200 challenging problems from various mathematical branches, vision-aid formulations, and difficulty levels, collected from diverse sources such as textbooks, examination papers, and Olympiad problems. Based on the proposed benchmark, we conduct comprehensive evaluations on ten mainstream LLMs and LMMs, highlighting deficiencies in the visual-aided reasoning process. For example, GPT-4V only achieves 45.33% accuracy in the visual-aided reasoning task, even with a drop of 2 points when provided with golden visual aids. In-depth analysis reveals that the main cause of deficiencies lies in hallucination regarding the implicit visual reasoning process, shedding light on future research directions in the visual-aided MPS process.
SeaLLMs 3: Open Foundation and Chat Multilingual Large Language Models for Southeast Asian Languages
Jul 29, 2024
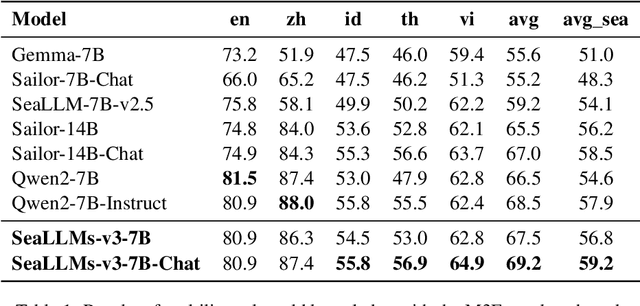
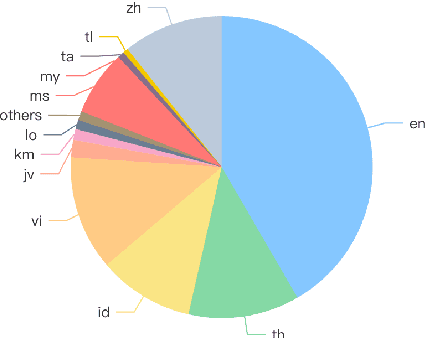
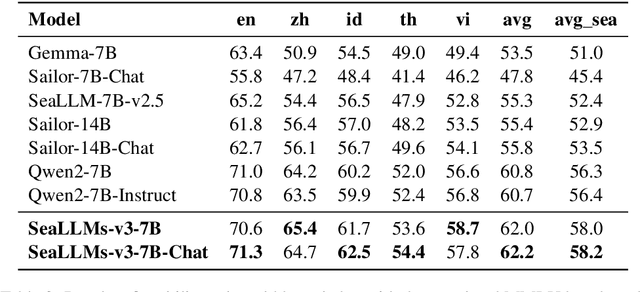
Large Language Models (LLMs) have shown remarkable abilities across various tasks, yet their development has predominantly centered on high-resource languages like English and Chinese, leaving low-resource languages underserved. To address this disparity, we present SeaLLMs 3, the latest iteration of the SeaLLMs model family, tailored for Southeast Asian languages. This region, characterized by its rich linguistic diversity, has lacked adequate language technology support. SeaLLMs 3 aims to bridge this gap by covering a comprehensive range of languages spoken in this region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese. Leveraging efficient language enhancement techniques and a specially constructed instruction tuning dataset, SeaLLMs 3 significantly reduces training costs while maintaining high performance and versatility. Our model excels in tasks such as world knowledge, mathematical reasoning, translation, and instruction following, achieving state-of-the-art performance among similarly sized models. Additionally, we prioritized safety and reliability by addressing both general and culture-specific considerations and incorporated mechanisms to reduce hallucinations. This work underscores the importance of inclusive AI, showing that advanced LLM capabilities can benefit underserved linguistic and cultural communities.
Unlocking Varied Perspectives: A Persona-Based Multi-Agent Framework with Debate-Driven Text Planning for Argument Generation
Jun 28, 2024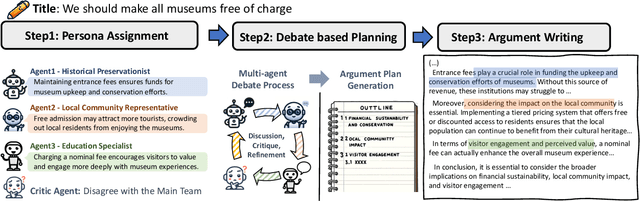
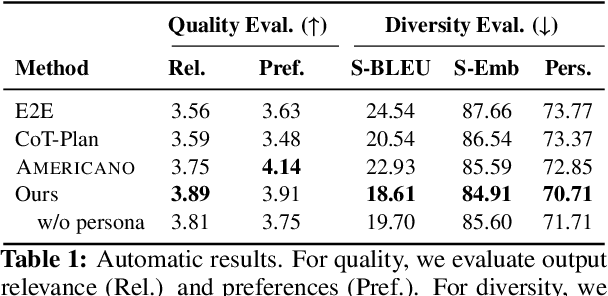
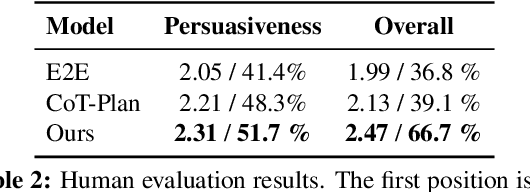
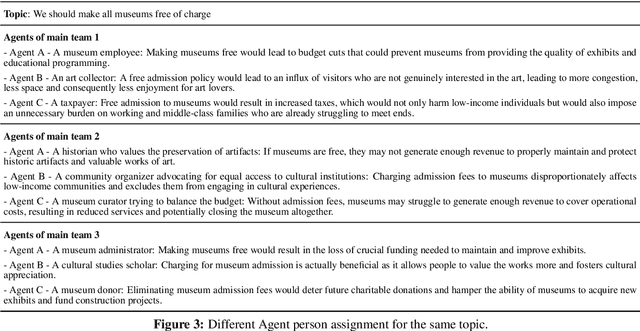
Writing persuasive arguments is a challenging task for both humans and machines. It entails incorporating high-level beliefs from various perspectives on the topic, along with deliberate reasoning and planning to construct a coherent narrative. Current language models often generate surface tokens autoregressively, lacking explicit integration of these underlying controls, resulting in limited output diversity and coherence. In this work, we propose a persona-based multi-agent framework for argument writing. Inspired by the human debate, we first assign each agent a persona representing its high-level beliefs from a unique perspective, and then design an agent interaction process so that the agents can collaboratively debate and discuss the idea to form an overall plan for argument writing. Such debate process enables fluid and nonlinear development of ideas. We evaluate our framework on argumentative essay writing. The results show that our framework can generate more diverse and persuasive arguments through both automatic and human evaluations.
From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
Mar 25, 2024Data visualization in the form of charts plays a pivotal role in data analysis, offering critical insights and aiding in informed decision-making. Automatic chart understanding has witnessed significant advancements with the rise of large foundation models in recent years. Foundation models, such as large language models, have revolutionized various natural language processing tasks and are increasingly being applied to chart understanding tasks. This survey paper provides a comprehensive overview of the recent developments, challenges, and future directions in chart understanding within the context of these foundation models. We review fundamental building blocks crucial for studying chart understanding tasks. Additionally, we explore various tasks and their evaluation metrics and sources of both charts and textual inputs. Various modeling strategies are then examined, encompassing both classification-based and generation-based approaches, along with tool augmentation techniques that enhance chart understanding performance. Furthermore, we discuss the state-of-the-art performance of each task and discuss how we can improve the performance. Challenges and future directions are addressed, highlighting the importance of several topics, such as domain-specific charts, lack of efforts in developing evaluation metrics, and agent-oriented settings. This survey paper serves as a comprehensive resource for researchers and practitioners in the fields of natural language processing, computer vision, and data analysis, providing valuable insights and directions for future research in chart understanding leveraging large foundation models. The studies mentioned in this paper, along with emerging new research, will be continually updated at: https://github.com/khuangaf/Awesome-Chart-Understanding.