 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSExpert: Computer-Use Agents Learning Professional Skills via Exploration
Mar 09, 2026General-purpose computer-use agents have shown impressive performance across diverse digital environments. However, our new benchmark, OSExpert-Eval, indicates they remain far less helpful than human experts. Although inference-time scaling enables adaptation, these agents complete complex tasks inefficiently with degraded performance, transfer poorly to unseen UIs, and struggle with fine-grained action sequences. To solve the problem, we introduce a GUI-based depth-first search (GUI-DFS) exploration algorithm to comprehensively explore and verify an environment's unit functions. The agent then exploits compositionality between unit skills to self-construct a curriculum for composite tasks. To support fine-grained actions, we curate a database of action primitives for agents to discover during exploration; these are saved as a skill set once the exploration is complete. We use the learned skills to improve the agent's performance and efficiency by (1) enriching agents with ready-to-use procedural knowledge, allowing them to plan only once for long trajectories and generate accurate actions, and (2) enabling them to end inference-time scaling earlier by realizing their boundary of capabilities. Extensive experiments show that our environment-learned agent takes a meaningful step toward expert-level computer use, achieving a around 20 percent performance gain on OSExpert-Eval and closing the efficiency gap to humans by around 80 percent
Predicting Camera Pose from Perspective Descriptions for Spatial Reasoning
Feb 05, 2026Multi-image spatial reasoning remains challenging for current multimodal large language models (MLLMs). While single-view perception is inherently 2D, reasoning over multiple views requires building a coherent scene understanding across viewpoints. In particular, we study perspective taking, where a model must build a coherent 3D understanding from multi-view observations and use it to reason from a new, language-specified viewpoint. We introduce CAMCUE, a pose-aware multi-image framework that uses camera pose as an explicit geometric anchor for cross-view fusion and novel-view reasoning. CAMCUE injects per-view pose into visual tokens, grounds natural-language viewpoint descriptions to a target camera pose, and synthesizes a pose-conditioned imagined target view to support answering. To support this setting, we curate CAMCUE-DATA with 27,668 training and 508 test instances pairing multi-view images and poses with diverse target-viewpoint descriptions and perspective-shift questions. We also include human-annotated viewpoint descriptions in the test split to evaluate generalization to human language. CAMCUE improves overall accuracy by 9.06% and predicts target poses from natural-language viewpoint descriptions with over 90% rotation accuracy within 20° and translation accuracy within a 0.5 error threshold. This direct grounding avoids expensive test-time search-and-match, reducing inference time from 256.6s to 1.45s per example and enabling fast, interactive use in real-world scenarios.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Multimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
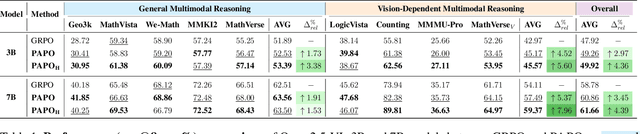
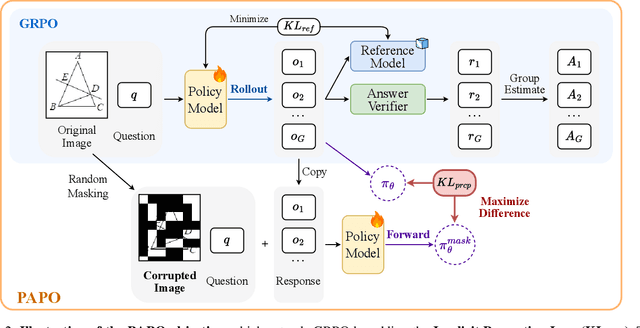
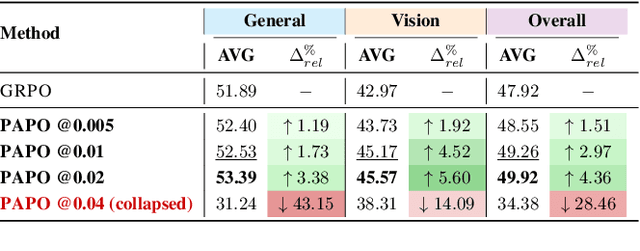
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
DyMU: Dynamic Merging and Virtual Unmerging for Efficient VLMs
Apr 23, 2025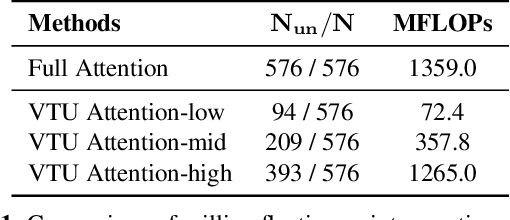
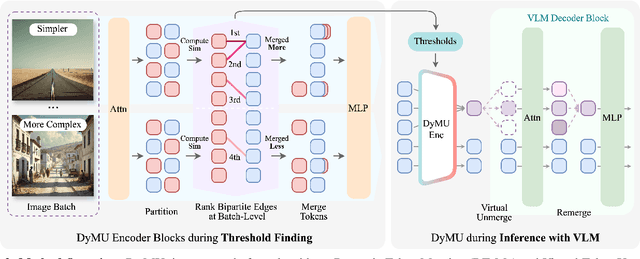
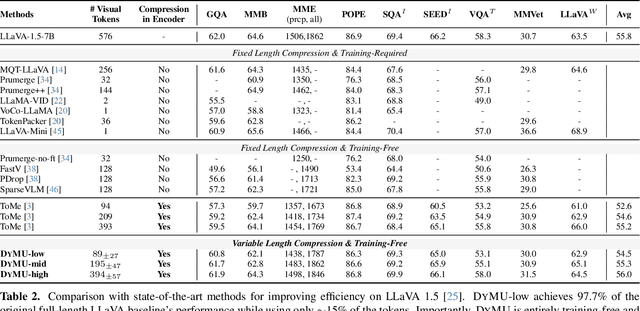
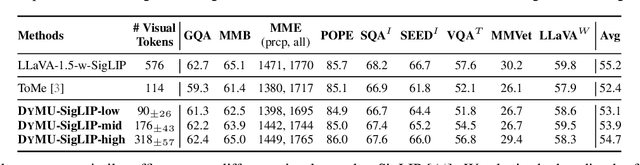
We present DyMU, an efficient, training-free framework that dynamically reduces the computational burden of vision-language models (VLMs) while maintaining high task performance. Our approach comprises two key components. First, Dynamic Token Merging (DToMe) reduces the number of visual token embeddings by merging similar tokens based on image complexity, addressing the inherent inefficiency of fixed-length outputs in vision transformers. Second, Virtual Token Unmerging (VTU) simulates the expected token sequence for large language models (LLMs) by efficiently reconstructing the attention dynamics of a full sequence, thus preserving the downstream performance without additional fine-tuning. Unlike previous approaches, our method dynamically adapts token compression to the content of the image and operates completely training-free, making it readily applicable to most state-of-the-art VLM architectures. Extensive experiments on image and video understanding tasks demonstrate that DyMU can reduce the average visual token count by 32%-85% while achieving comparable performance to full-length models across diverse VLM architectures, including the recently popularized AnyRes-based visual encoders. Furthermore, through qualitative analyses, we demonstrate that DToMe effectively adapts token reduction based on image complexity and, unlike existing systems, provides users more control over computational costs. Project page: https://mikewangwzhl.github.io/dymu/.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Mar 03, 2025Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition. In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators. Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%. Code and datasets are public available at https://github.com/MultiagentBench/MARBLE.
Synthia: Novel Concept Design with Affordance Composition
Feb 25, 2025Text-to-image (T2I) models enable rapid concept design, making them widely used in AI-driven design. While recent studies focus on generating semantic and stylistic variations of given design concepts, functional coherence--the integration of multiple affordances into a single coherent concept--remains largely overlooked. In this paper, we introduce SYNTHIA, a framework for generating novel, functionally coherent designs based on desired affordances. Our approach leverages a hierarchical concept ontology that decomposes concepts into parts and affordances, serving as a crucial building block for functionally coherent design. We also develop a curriculum learning scheme based on our ontology that contrastively fine-tunes T2I models to progressively learn affordance composition while maintaining visual novelty. To elaborate, we (i) gradually increase affordance distance, guiding models from basic concept-affordance association to complex affordance compositions that integrate parts of distinct affordances into a single, coherent form, and (ii) enforce visual novelty by employing contrastive objectives to push learned representations away from existing concepts. Experimental results show that SYNTHIA outperforms state-of-the-art T2I models, demonstrating absolute gains of 25.1% and 14.7% for novelty and functional coherence in human evaluation, respectively.
Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks
Jan 20, 2025



Smartphones have become indispensable in modern life, yet navigating complex tasks on mobile devices often remains frustrating. Recent advancements in large multimodal model (LMM)-based mobile agents have demonstrated the ability to perceive and act in mobile environments. However, current approaches face significant limitations: they fall short in addressing real-world human needs, struggle with reasoning-intensive and long-horizon tasks, and lack mechanisms to learn and improve from prior experiences. To overcome these challenges, we introduce Mobile-Agent-E, a hierarchical multi-agent framework capable of self-evolution through past experience. By hierarchical, we mean an explicit separation of high-level planning and low-level action execution. The framework comprises a Manager, responsible for devising overall plans by breaking down complex tasks into subgoals, and four subordinate agents--Perceptor, Operator, Action Reflector, and Notetaker--which handle fine-grained visual perception, immediate action execution, error verification, and information aggregation, respectively. Mobile-Agent-E also features a novel self-evolution module which maintains a persistent long-term memory comprising Tips and Shortcuts. Tips are general guidance and lessons learned from prior tasks on how to effectively interact with the environment. Shortcuts are reusable, executable sequences of atomic operations tailored for specific subroutines. The inclusion of Tips and Shortcuts facilitates continuous refinement in performance and efficiency. Alongside this framework, we introduce Mobile-Eval-E, a new benchmark featuring complex mobile tasks requiring long-horizon, multi-app interactions. Empirical results show that Mobile-Agent-E achieves a 22% absolute improvement over previous state-of-the-art approaches across three foundation model backbones. Project page: https://x-plug.github.io/MobileAgent.
Infogent: An Agent-Based Framework for Web Information Aggregation
Oct 24, 2024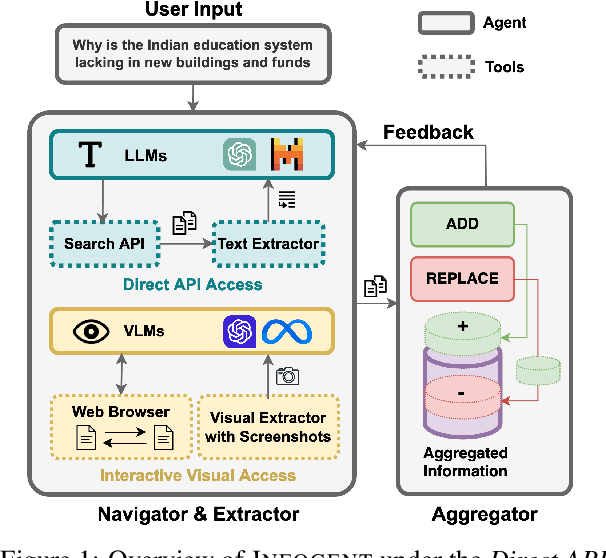

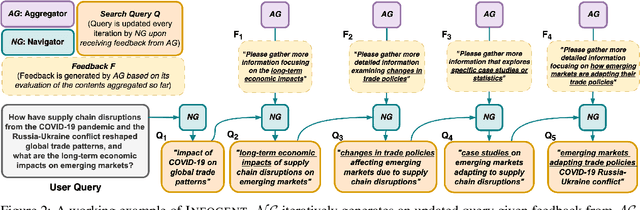
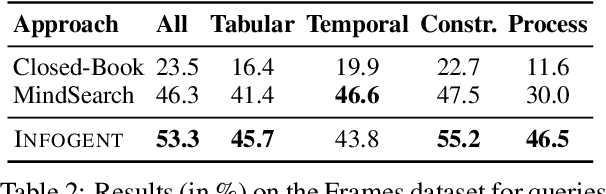
Despite seemingly performant web agents on the task-completion benchmarks, most existing methods evaluate the agents based on a presupposition: the web navigation task consists of linear sequence of actions with an end state that marks task completion. In contrast, our work focuses on web navigation for information aggregation, wherein the agent must explore different websites to gather information for a complex query. We consider web information aggregation from two different perspectives: (i) Direct API-driven Access relies on a text-only view of the Web, leveraging external tools such as Google Search API to navigate the web and a scraper to extract website contents. (ii) Interactive Visual Access uses screenshots of the webpages and requires interaction with the browser to navigate and access information. Motivated by these diverse information access settings, we introduce Infogent, a novel modular framework for web information aggregation involving three distinct components: Navigator, Extractor and Aggregator. Experiments on different information access settings demonstrate Infogent beats an existing SOTA multi-agent search framework by 7% under Direct API-Driven Access on FRAMES, and improves over an existing information-seeking web agent by 4.3% under Interactive Visual Access on AssistantBench.