 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Situated Awareness in the Real World
Feb 18, 2026A core aspect of human perception is situated awareness, the ability to relate ourselves to the surrounding physical environment and reason over possible actions in context. However, most existing benchmarks for multimodal foundation models (MFMs) emphasize environment-centric spatial relations (relations among objects in a scene), while largely overlooking observer-centric relationships that require reasoning relative to agent's viewpoint, pose, and motion. To bridge this gap, we introduce SAW-Bench (Situated Awareness in the Real World), a novel benchmark for evaluating egocentric situated awareness using real-world videos. SAW-Bench comprises 786 self-recorded videos captured with Ray-Ban Meta (Gen 2) smart glasses spanning diverse indoor and outdoor environments, and over 2,071 human-annotated question-answer pairs. It probes a model's observer-centric understanding with six different awareness tasks. Our comprehensive evaluation reveals a human-model performance gap of 37.66%, even with the best-performing MFM, Gemini 3 Flash. Beyond this gap, our in-depth analysis uncovers several notable findings; for example, while models can exploit partial geometric cues in egocentric videos, they often fail to infer a coherent camera geometry, leading to systematic spatial reasoning errors. We position SAW-Bench as a benchmark for situated spatial intelligence, moving beyond passive observation to understanding physically grounded, observer-centric dynamics.
A Tool Bottleneck Framework for Clinically-Informed and Interpretable Medical Image Understanding
Dec 24, 2025Recent tool-use frameworks powered by vision-language models (VLMs) improve image understanding by grounding model predictions with specialized tools. Broadly, these frameworks leverage VLMs and a pre-specified toolbox to decompose the prediction task into multiple tool calls (often deep learning models) which are composed to make a prediction. The dominant approach to composing tools is using text, via function calls embedded in VLM-generated code or natural language. However, these methods often perform poorly on medical image understanding, where salient information is encoded as spatially-localized features that are difficult to compose or fuse via text alone. To address this, we propose a tool-use framework for medical image understanding called the Tool Bottleneck Framework (TBF), which composes VLM-selected tools using a learned Tool Bottleneck Model (TBM). For a given image and task, TBF leverages an off-the-shelf medical VLM to select tools from a toolbox that each extract clinically-relevant features. Instead of text-based composition, these tools are composed by the TBM, which computes and fuses the tool outputs using a neural network before outputting the final prediction. We propose a simple and effective strategy for TBMs to make predictions with any arbitrary VLM tool selection. Overall, our framework not only improves tool-use in medical imaging contexts, but also yields more interpretable, clinically-grounded predictors. We evaluate TBF on tasks in histopathology and dermatology and find that these advantages enable our framework to perform on par with or better than deep learning-based classifiers, VLMs, and state-of-the-art tool-use frameworks, with particular gains in data-limited regimes. Our code is available at https://github.com/christinaliu2020/tool-bottleneck-framework.
A Matter of Interest: Understanding Interestingness of Math Problems in Humans and Language Models
Nov 11, 2025The evolution of mathematics has been guided in part by interestingness. From researchers choosing which problems to tackle next, to students deciding which ones to engage with, people's choices are often guided by judgments about how interesting or challenging problems are likely to be. As AI systems, such as LLMs, increasingly participate in mathematics with people -- whether for advanced research or education -- it becomes important to understand how well their judgments align with human ones. Our work examines this alignment through two empirical studies of human and LLM assessment of mathematical interestingness and difficulty, spanning a range of mathematical experience. We study two groups: participants from a crowdsourcing platform and International Math Olympiad competitors. We show that while many LLMs appear to broadly agree with human notions of interestingness, they mostly do not capture the distribution observed in human judgments. Moreover, most LLMs only somewhat align with why humans find certain math problems interesting, showing weak correlation with human-selected interestingness rationales. Together, our findings highlight both the promises and limitations of current LLMs in capturing human interestingness judgments for mathematical AI thought partnerships.
Explain Before You Answer: A Survey on Compositional Visual Reasoning
Aug 24, 2025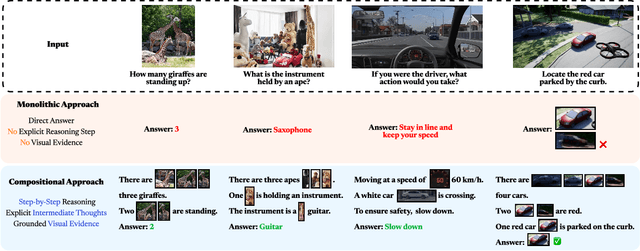
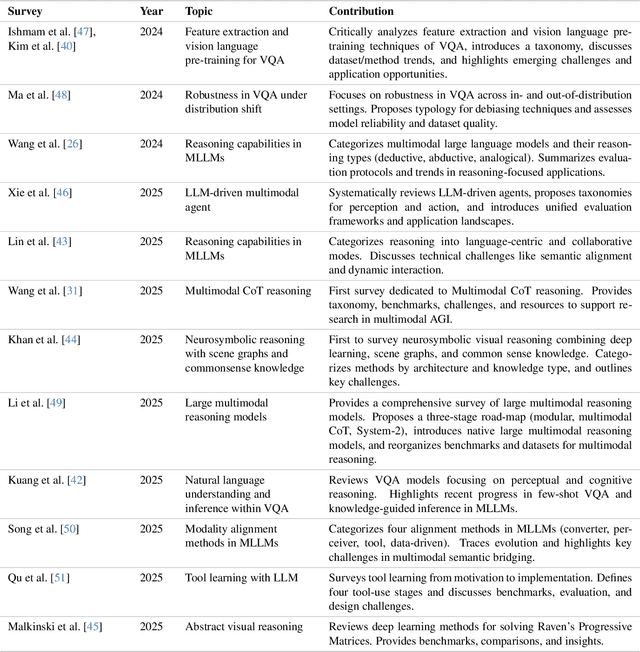
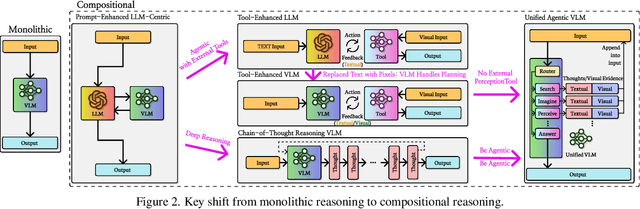
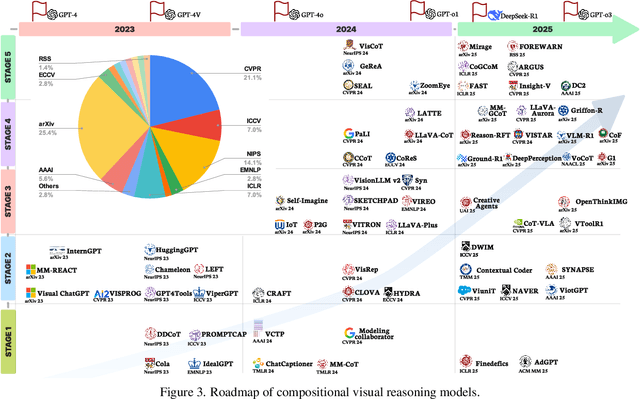
Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
Predicate Hierarchies Improve Few-Shot State Classification
Feb 18, 2025



State classification of objects and their relations is core to many long-horizon tasks, particularly in robot planning and manipulation. However, the combinatorial explosion of possible object-predicate combinations, coupled with the need to adapt to novel real-world environments, makes it a desideratum for state classification models to generalize to novel queries with few examples. To this end, we propose PHIER, which leverages predicate hierarchies to generalize effectively in few-shot scenarios. PHIER uses an object-centric scene encoder, self-supervised losses that infer semantic relations between predicates, and a hyperbolic distance metric that captures hierarchical structure; it learns a structured latent space of image-predicate pairs that guides reasoning over state classification queries. We evaluate PHIER in the CALVIN and BEHAVIOR robotic environments and show that PHIER significantly outperforms existing methods in few-shot, out-of-distribution state classification, and demonstrates strong zero- and few-shot generalization from simulated to real-world tasks. Our results demonstrate that leveraging predicate hierarchies improves performance on state classification tasks with limited data.
What Makes a Maze Look Like a Maze?
Sep 12, 2024A unique aspect of human visual understanding is the ability to flexibly interpret abstract concepts: acquiring lifted rules explaining what they symbolize, grounding them across familiar and unfamiliar contexts, and making predictions or reasoning about them. While off-the-shelf vision-language models excel at making literal interpretations of images (e.g., recognizing object categories such as tree branches), they still struggle to make sense of such visual abstractions (e.g., how an arrangement of tree branches may form the walls of a maze). To address this challenge, we introduce Deep Schema Grounding (DSG), a framework that leverages explicit structured representations of visual abstractions for grounding and reasoning. At the core of DSG are schemas--dependency graph descriptions of abstract concepts that decompose them into more primitive-level symbols. DSG uses large language models to extract schemas, then hierarchically grounds concrete to abstract components of the schema onto images with vision-language models. The grounded schema is used to augment visual abstraction understanding. We systematically evaluate DSG and different methods in reasoning on our new Visual Abstractions Dataset, which consists of diverse, real-world images of abstract concepts and corresponding question-answer pairs labeled by humans. We show that DSG significantly improves the abstract visual reasoning performance of vision-language models, and is a step toward human-aligned understanding of visual abstractions.
Composable Part-Based Manipulation
May 09, 2024



In this paper, we propose composable part-based manipulation (CPM), a novel approach that leverages object-part decomposition and part-part correspondences to improve learning and generalization of robotic manipulation skills. By considering the functional correspondences between object parts, we conceptualize functional actions, such as pouring and constrained placing, as combinations of different correspondence constraints. CPM comprises a collection of composable diffusion models, where each model captures a different inter-object correspondence. These diffusion models can generate parameters for manipulation skills based on the specific object parts. Leveraging part-based correspondences coupled with the task decomposition into distinct constraints enables strong generalization to novel objects and object categories. We validate our approach in both simulated and real-world scenarios, demonstrating its effectiveness in achieving robust and generalized manipulation capabilities.
Learning Planning Abstractions from Language
May 06, 2024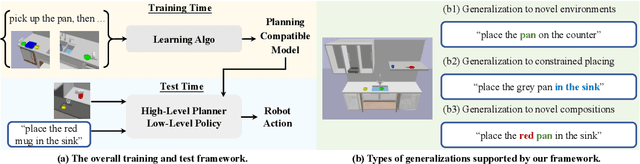
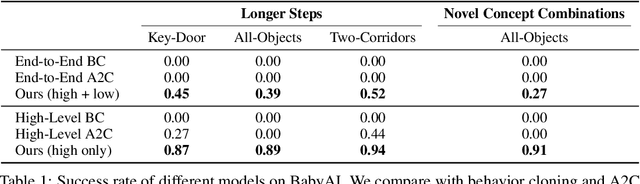


This paper presents a framework for learning state and action abstractions in sequential decision-making domains. Our framework, planning abstraction from language (PARL), utilizes language-annotated demonstrations to automatically discover a symbolic and abstract action space and induce a latent state abstraction based on it. PARL consists of three stages: 1) recovering object-level and action concepts, 2) learning state abstractions, abstract action feasibility, and transition models, and 3) applying low-level policies for abstract actions. During inference, given the task description, PARL first makes abstract action plans using the latent transition and feasibility functions, then refines the high-level plan using low-level policies. PARL generalizes across scenarios involving novel object instances and environments, unseen concept compositions, and tasks that require longer planning horizons than settings it is trained on.
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Apr 30, 2024



3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
Text-Based Reasoning About Vector Graphics
Apr 10, 2024



While large multimodal models excel in broad vision-language benchmarks, they often struggle with tasks requiring precise perception of low-level visual details, such as comparing line lengths or solving simple mazes. In particular, this failure mode persists in question-answering tasks about vector graphics -- images composed purely of 2D objects and shapes. To address this challenge, we propose the Visually Descriptive Language Model (VDLM), which performs text-based reasoning about vector graphics. VDLM leverages Scalable Vector Graphics (SVG) for a more precise visual description and first uses an off-the-shelf raster-to-SVG algorithm for encoding. Since existing language models cannot understand raw SVGs in a zero-shot setting, VDLM then bridges SVG with pretrained language models through a newly introduced intermediate symbolic representation, Primal Visual Description (PVD), comprising primitive attributes (e.g., shape, position, measurement) with their corresponding predicted values. PVD is task-agnostic and represents visual primitives that are universal across all vector graphics. It can be learned with procedurally generated (SVG, PVD) pairs and also enables the direct use of LLMs for generalization to complex reasoning tasks. By casting an image to a text-based representation, we can leverage the power of language models to learn alignment from SVG to visual primitives and generalize to unseen question-answering tasks. Empirical results show that VDLM achieves stronger zero-shot performance compared to state-of-the-art LMMs, such as GPT-4V, in various low-level multimodal perception and reasoning tasks on vector graphics. We additionally present extensive analyses on VDLM's performance, demonstrating that our framework offers better interpretability due to its disentangled perception and reasoning processes. Project page: https://mikewangwzhl.github.io/VDLM/