 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Software Engineering Through Closed-Loop Memory Optimization
Jun 04, 2026Large language models (LLMs) have enabled powerful software engineering (SE) agents capable of navigating complex codebases and resolving real-world issues. However, these agents remain fundamentally episodic: they fail to retain, refine, and reuse experiences across tasks, repeatedly reconstructing context from scratch and reproducing similar mistakes. Even with memory support, they offer no remedy for the absence of a principled, task-agnostic \textit{memory utility}, making them difficult to evaluate rigorously or generalize across agents and settings. To tackle these limitations, we introduce \ours, a closed-loop framework for memory augmentation in SE agents. \ours grounds memory utility in \textit{validated downstream impact}, establishing utility as both a task-agnostic \textbf{evaluation benchmark} and an annotation-free \textbf{optimization signal}. Through complementary evaluation on \textit{single-episode} and \textit{cross-episode} memory augmentation, results demonstrate that \ours consistently improves SE agents across settings, achieving absolute gains of up to $\uparrow5.25\%$ in success rate and $\uparrow4.63\%$ in resolve efficiency, while substantially reducing computational cost by $\geq9.79\%$. Our project page: \href{https://xhguo7.github.io/MemOp/}{https://xhguo7.github.io/MemOp/}.
BAGEN: Are LLM Agents Budget-Aware?
May 29, 2026While agents are increasingly spending more resources, today agent cost is mostly measured only after execution. A Budget-Aware Agent (BAGEN) should treat budget as an active control signal, rather than a passive cost metric. We first systematically define budget estimation as internal budgets (from agent computation) and external budgets (from agent actions). We then formalize budget-awareness as progressive interval estimation: at each step of a plan, an agent should predict an upper and lower bound on remaining budget, and alert when completion is unlikely. Scoring with a rollout-replay protocol, we find consistent failure patterns on four environments and five frontier agents: (1) strong agents do not necessarily have strong budget-awareness, with correlation r=0.35. (2) frontier models are consistently over-optimistic, continue spending on tasks that are unlikely to succeed, instead of alerting the user early. (3) budget-aware signal is actionable and trainable. Early stop saves 28-64% tokens on failed trajectories, and SFT+RL strengthens early stop and alert behavior. (4) precise interval calibration remains challenging, with interval coverage capping at 47% after SFT+RL. Project page: https://ragen-ai.github.io/bagen/
How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks
Apr 24, 2026The wide adoption of AI agents in complex human workflows is driving rapid growth in LLM token consumption. When agents are deployed on tasks that require a significant amount of tokens, three questions naturally arise: (1) Where do AI agents spend the tokens? (2) Which models are more token-efficient? and (3) Can agents predict their token usage before task execution? In this paper, we present the first systematic study of token consumption patterns in agentic coding tasks. We analyze trajectories from eight frontier LLMs on SWE-bench Verified and evaluate models' ability to predict their own token costs before task execution. We find that: (1) agentic tasks are uniquely expensive, consuming 1000x more tokens than code reasoning and code chat, with input tokens rather than output tokens driving the overall cost; (2) token usage is highly variable and inherently stochastic: runs on the same task can differ by up to 30x in total tokens, and higher token usage does not translate into higher accuracy; instead, accuracy often peaks at intermediate cost and saturates at higher costs; (3) models vary substantially in token efficiency: on the same tasks, Kimi-K2 and Claude-Sonnet-4.5, on average, consume over 1.5 million more tokens than GPT-5; (4) task difficulty rated by human experts only weakly aligns with actual token costs, revealing a fundamental gap between human-perceived complexity and the computational effort agents actually expend; and (5) frontier models fail to accurately predict their own token usage (with weak-to-moderate correlations, up to 0.39) and systematically underestimate real token costs. Our study offers new insights into the economics of AI agents and can inspire future research in this direction.
EvoClaw: Evaluating AI Agents on Continuous Software Evolution
Mar 13, 2026With AI agents increasingly deployed as long-running systems, it becomes essential to autonomously construct and continuously evolve customized software to enable interaction within dynamic environments. Yet, existing benchmarks evaluate agents on isolated, one-off coding tasks, neglecting the temporal dependencies and technical debt inherent in real-world software evolution. To bridge this gap, we introduce DeepCommit, an agentic pipeline that reconstructs verifiable Milestone DAGs from noisy commit logs, where milestones are defined as semantically cohesive development goals. These executable sequences enable EvoClaw, a novel benchmark that requires agents to sustain system integrity and limit error accumulation, dimensions of long-term software evolution largely missing from current benchmarks. Our evaluation of 12 frontier models across 4 agent frameworks reveals a critical vulnerability: overall performance scores drop significantly from $>$80% on isolated tasks to at most 38% in continuous settings, exposing agents' profound struggle with long-term maintenance and error propagation.
A Rubric-Supervised Critic from Sparse Real-World Outcomes
Mar 04, 2026Academic benchmarks for coding agents tend to reward autonomous task completion, measured by verifiable rewards such as unit-test success. In contrast, real-world coding agents operate with humans in the loop, where success signals are typically noisy, delayed, and sparse. How can we bridge this gap? In this paper, we propose a process to learn a "critic" model from sparse and noisy interaction data, which can then be used both as a reward model for either RL-based training or inference-time scaling. Specifically, we introduce Critic Rubrics, a rubric-based supervision framework with 24 behavioral features that can be derived from human-agent interaction traces alone. Using a semi-supervised objective, we can then jointly predict these rubrics and sparse human feedback (when present). In experiments, we demonstrate that, despite being trained primarily from trace-observable rubrics and sparse real-world outcome proxies, these critics improve best-of-N reranking on SWE-bench (Best@8 +15.9 over Random@8 over the rerankable subset of trajectories), enable early stopping (+17.7 with 83% fewer attempts), and support training-time data curation via critic-selected trajectories.
Continuous Telemonitoring of Heart Failure using Personalised Speech Dynamics
Feb 25, 2026Remote monitoring of heart failure (HF) via speech signals provides a non-invasive and cost-effective solution for long-term patient management. However, substantial inter-individual heterogeneity in vocal characteristics often limits the accuracy of traditional cross-sectional classification models. To address this, we propose a Longitudinal Intra-Patient Tracking (LIPT) scheme designed to capture the trajectory of relative symptomatic changes within individuals. Central to this framework is a Personalised Sequential Encoder (PSE), which transforms longitudinal speech recordings into context-aware latent representations. By incorporating historical data at each timestamp, the PSE facilitates a holistic assessment of the clinical trajectory rather than modelling discrete visits independently. Experimental results from a cohort of 225 patients demonstrate that the LIPT paradigm significantly outperforms the classic cross-sectional approaches, achieving a recognition accuracy of 99.7% for clinical status transitions. The model's high sensitivity was further corroborated by additional follow-up data, confirming its efficacy in predicting HF deterioration and its potential to secure patient safety in remote, home-based settings. Furthermore, this work addresses the gap in existing literature by providing a comprehensive analysis of different speech task designs and acoustic features. Taken together, the superior performance of the LIPT framework and PSE architecture validates their readiness for integration into long-term telemonitoring systems, offering a scalable solution for remote heart failure management.
Hybrid-Gym: Training Coding Agents to Generalize Across Tasks
Feb 18, 2026When assessing the quality of coding agents, predominant benchmarks focus on solving single issues on GitHub, such as SWE-Bench. In contrast, in real use, these agents solve more various and complex tasks that involve other skills such as exploring codebases, testing software, and designing architecture. In this paper, we first characterize some transferable skills that are shared across diverse tasks by decomposing trajectories into fine-grained components, and derive a set of principles for designing auxiliary training tasks to teach language models these skills. Guided by these principles, we propose a training environment, Hybrid-Gym, consisting of a set of scalable synthetic tasks, such as function localization and dependency search. Experiments show that agents trained on our synthetic tasks effectively generalize to diverse real-world tasks that are not present in training, improving a base model by 25.4% absolute gain on SWE-Bench Verified, 7.9% on SWT-Bench Verified, and 5.1% on Commit-0 Lite. Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9% on SWT-Bench Verified). Code available at: https://github.com/yiqingxyq/Hybrid-Gym.
Cross-Linguistic Persona-Driven Data Synthesis for Robust Multimodal Cognitive Decline Detection
Feb 08, 2026Speech-based digital biomarkers represent a scalable, non-invasive frontier for the early identification of Mild Cognitive Impairment (MCI). However, the development of robust diagnostic models remains impeded by acute clinical data scarcity and a lack of interpretable reasoning. Current solutions frequently struggle with cross-lingual generalization and fail to provide the transparent rationales essential for clinical trust. To address these barriers, we introduce SynCog, a novel framework integrating controllable zero-shot multimodal data synthesis with Chain-of-Thought (CoT) deduction fine-tuning. Specifically, SynCog simulates diverse virtual subjects with varying cognitive profiles to effectively alleviate clinical data scarcity. This generative paradigm enables the rapid, zero-shot expansion of clinical corpora across diverse languages, effectively bypassing data bottlenecks in low-resource settings and bolstering the diagnostic performance of Multimodal Large Language Models (MLLMs). Leveraging this synthesized dataset, we fine-tune a foundational multimodal backbone using a CoT deduction strategy, empowering the model to explicitly articulate diagnostic thought processes rather than relying on black-box predictions. Extensive experiments on the ADReSS and ADReSSo benchmarks demonstrate that augmenting limited clinical data with synthetic phenotypes yields competitive diagnostic performance, achieving Macro-F1 scores of 80.67% and 78.46%, respectively, outperforming current baseline models. Furthermore, evaluation on an independent real-world Mandarin cohort (CIR-E) demonstrates robust cross-linguistic generalization, attaining a Macro-F1 of 48.71%. These findings constitute a critical step toward providing clinically trustworthy and linguistically inclusive cognitive assessment tools for global healthcare.
The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents
Nov 05, 2025


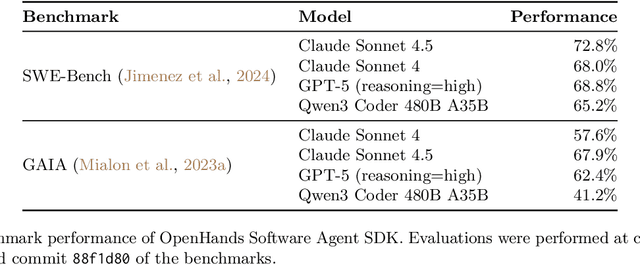
Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.