 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynSplit-KV: Dynamic Semantic Splitting for KVCache Compression in Efficient Long-Context LLM Inference
Feb 03, 2026Although Key-Value (KV) Cache is essential for efficient large language models (LLMs) inference, its growing memory footprint in long-context scenarios poses a significant bottleneck, making KVCache compression crucial. Current compression methods rely on rigid splitting strategies, such as fixed intervals or pre-defined delimiters. We observe that rigid splitting suffers from significant accuracy degradation (ranging from 5.5% to 55.1%) across different scenarios, owing to the scenario-dependent nature of the semantic boundaries. This highlights the necessity of dynamic semantic splitting to match semantics. To achieve this, we face two challenges. (1) Improper delimiter selection misaligns semantics with the KVCache, resulting in 28.6% accuracy loss. (2) Variable-length blocks after splitting introduce over 73.1% additional inference overhead. To address the above challenges, we propose DynSplit-KV, a KVCache compression method that dynamically identifies delimiters for splitting. We propose: (1) a dynamic importance-aware delimiter selection strategy, improving accuracy by 49.9%. (2) A uniform mapping strategy that transforms variable-length semantic blocks into a fixed-length format, reducing inference overhead by 4.9x. Experiments show that DynSplit-KV achieves the highest accuracy, 2.2x speedup compared with FlashAttention and 2.6x peak memory reduction in long-context scenarios.
SpecDiff: Accelerating Diffusion Model Inference with Self-Speculation
Sep 17, 2025

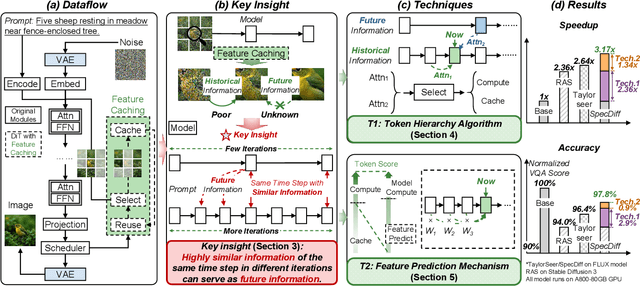

Feature caching has recently emerged as a promising method for diffusion model acceleration. It effectively alleviates the inefficiency problem caused by high computational requirements by caching similar features in the inference process of the diffusion model. In this paper, we analyze existing feature caching methods from the perspective of information utilization, and point out that relying solely on historical information will lead to constrained accuracy and speed performance. And we propose a novel paradigm that introduces future information via self-speculation based on the information similarity at the same time step across different iteration times. Based on this paradigm, we present \textit{SpecDiff}, a training-free multi-level feature caching strategy including a cached feature selection algorithm and a multi-level feature classification algorithm. (1) Feature selection algorithm based on self-speculative information. \textit{SpecDiff} determines a dynamic importance score for each token based on self-speculative information and historical information, and performs cached feature selection through the importance score. (2) Multi-level feature classification algorithm based on feature importance scores. \textit{SpecDiff} classifies tokens by leveraging the differences in feature importance scores and introduces a multi-level feature calculation strategy. Extensive experiments show that \textit{SpecDiff} achieves average 2.80 \times, 2.74 \times , and 3.17\times speedup with negligible quality loss in Stable Diffusion 3, 3.5, and FLUX compared to RFlow on NVIDIA A800-80GB GPU. By merging speculative and historical information, \textit{SpecDiff} overcomes the speedup-accuracy trade-off bottleneck, pushing the Pareto frontier of speedup and accuracy in the efficient diffusion model inference.
Search Arena: Analyzing Search-Augmented LLMs
Jun 05, 2025Search-augmented language models combine web search with Large Language Models (LLMs) to improve response groundedness and freshness. However, analyzing these systems remains challenging: existing datasets are limited in scale and narrow in scope, often constrained to static, single-turn, fact-checking questions. In this work, we introduce Search Arena, a crowd-sourced, large-scale, human-preference dataset of over 24,000 paired multi-turn user interactions with search-augmented LLMs. The dataset spans diverse intents and languages, and contains full system traces with around 12,000 human preference votes. Our analysis reveals that user preferences are influenced by the number of citations, even when the cited content does not directly support the attributed claims, uncovering a gap between perceived and actual credibility. Furthermore, user preferences vary across cited sources, revealing that community-driven platforms are generally preferred and static encyclopedic sources are not always appropriate and reliable. To assess performance across different settings, we conduct cross-arena analyses by testing search-augmented LLMs in a general-purpose chat environment and conventional LLMs in search-intensive settings. We find that web search does not degrade and may even improve performance in non-search settings; however, the quality in search settings is significantly affected if solely relying on the model's parametric knowledge. We open-sourced the dataset to support future research in this direction. Our dataset and code are available at: https://github.com/lmarena/search-arena.
Learning Adaptive Parallel Reasoning with Language Models
Apr 21, 2025Scaling inference-time computation has substantially improved the reasoning capabilities of language models. However, existing methods have significant limitations: serialized chain-of-thought approaches generate overly long outputs, leading to increased latency and exhausted context windows, while parallel methods such as self-consistency suffer from insufficient coordination, resulting in redundant computations and limited performance gains. To address these shortcomings, we propose Adaptive Parallel Reasoning (APR), a novel reasoning framework that enables language models to orchestrate both serialized and parallel computations end-to-end. APR generalizes existing reasoning methods by enabling adaptive multi-threaded inference using spawn() and join() operations. A key innovation is our end-to-end reinforcement learning strategy, optimizing both parent and child inference threads to enhance task success rate without requiring predefined reasoning structures. Experiments on the Countdown reasoning task demonstrate significant benefits of APR: (1) higher performance within the same context window (83.4% vs. 60.0% at 4k context); (2) superior scalability with increased computation (80.1% vs. 66.6% at 20k total tokens); (3) improved accuracy at equivalent latency (75.2% vs. 57.3% at approximately 5,000ms). APR represents a step towards enabling language models to autonomously optimize their reasoning processes through adaptive allocation of computation.
SpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting
Apr 11, 2025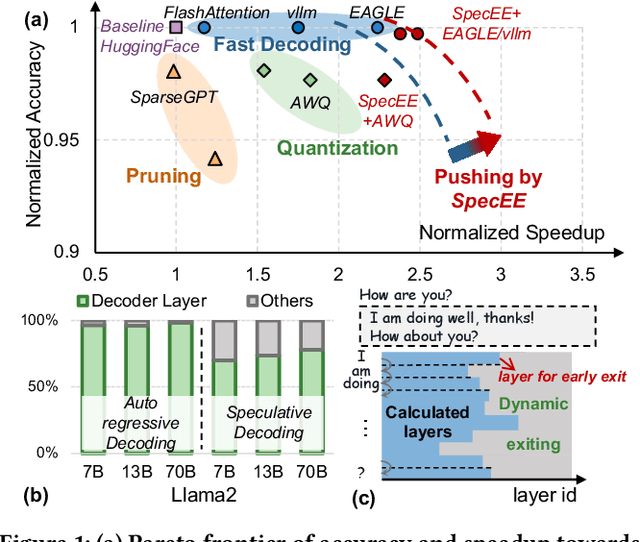
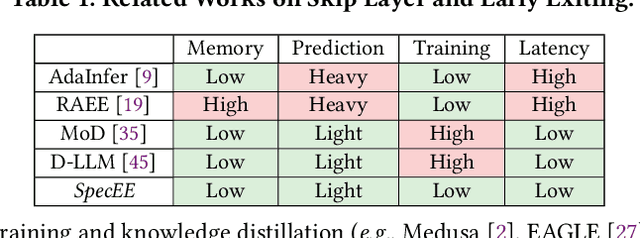
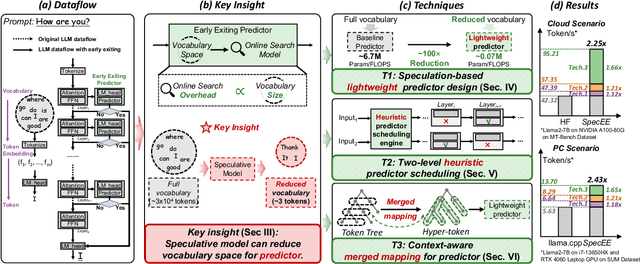
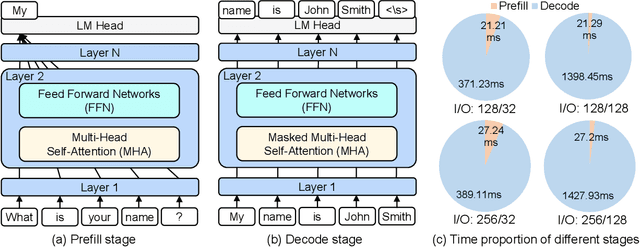
Early exiting has recently emerged as a promising technique for accelerating large language models (LLMs) by effectively reducing the hardware computation and memory access. In this paper, we present SpecEE, a fast LLM inference engine with speculative early exiting. (1) At the algorithm level, we propose the speculation-based lightweight predictor design by exploiting the probabilistic correlation between the speculative tokens and the correct results and high parallelism of GPUs. (2) At the system level, we point out that not all layers need a predictor and design the two-level heuristic predictor scheduling engine based on skewed distribution and contextual similarity. (3) At the mapping level, we point out that different decoding methods share the same essential characteristics, and propose the context-aware merged mapping for predictor with efficient GPU implementations to support speculative decoding, and form a framework for various existing orthogonal acceleration techniques (e.g., quantization and sparse activation) on cloud and personal computer (PC) scenarios, successfully pushing the Pareto frontier of accuracy and speedup. It is worth noting that SpecEE can be applied to any LLM by negligible training overhead in advance without affecting the model original parameters. Extensive experiments show that SpecEE achieves 2.25x and 2.43x speedup with Llama2-7B on cloud and PC scenarios respectively.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Training Software Engineering Agents and Verifiers with SWE-Gym
Dec 30, 2024



We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language. We use SWE-Gym to train language model based SWE agents , achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym. When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.
Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective
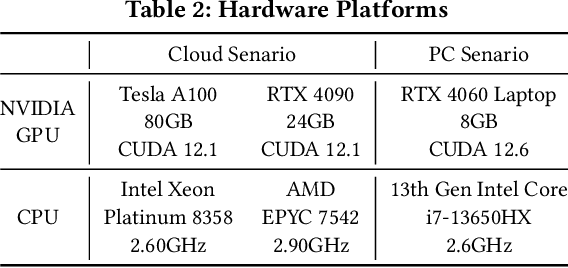
Oct 06, 2024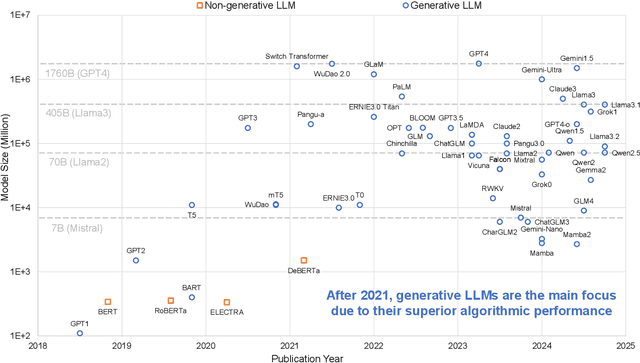
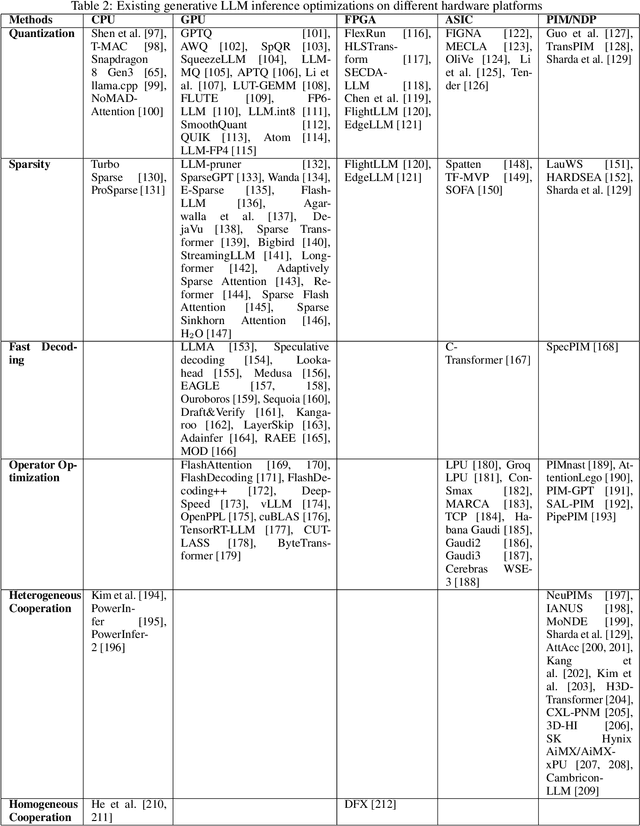
Large Language Models (LLMs) have demonstrated remarkable capabilities across various fields, from natural language understanding to text generation. Compared to non-generative LLMs like BERT and DeBERTa, generative LLMs like GPT series and Llama series are currently the main focus due to their superior algorithmic performance. The advancements in generative LLMs are closely intertwined with the development of hardware capabilities. Various hardware platforms exhibit distinct hardware characteristics, which can help improve LLM inference performance. Therefore, this paper comprehensively surveys efficient generative LLM inference on different hardware platforms. First, we provide an overview of the algorithm architecture of mainstream generative LLMs and delve into the inference process. Then, we summarize different optimization methods for different platforms such as CPU, GPU, FPGA, ASIC, and PIM/NDP, and provide inference results for generative LLMs. Furthermore, we perform a qualitative and quantitative comparison of inference performance with batch sizes 1 and 8 on different hardware platforms by considering hardware power consumption, absolute inference speed (tokens/s), and energy efficiency (tokens/J). We compare the performance of the same optimization methods across different hardware platforms, the performance across different hardware platforms, and the performance of different methods on the same hardware platform. This provides a systematic and comprehensive summary of existing inference acceleration work by integrating software optimization methods and hardware platforms, which can point to the future trends and potential developments of generative LLMs and hardware technology for edge-side scenarios.
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Jul 23, 2024



Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks. Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., SWE-Bench) and web browsing (e.g., WebArena), among others. Released under the permissive MIT license, OpenDevin is a community project spanning academia and industry with more than 1.3K contributions from over 160 contributors and will improve going forward.
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning
Jun 14, 2024Training corpuses for vision language models (VLMs) typically lack sufficient amounts of decision-centric data. This renders off-the-shelf VLMs sub-optimal for decision-making tasks such as in-the-wild device control through graphical user interfaces (GUIs). While training with static demonstrations has shown some promise, we show that such methods fall short for controlling real GUIs due to their failure to deal with real-world stochasticity and non-stationarity not captured in static observational data. This paper introduces a novel autonomous RL approach, called DigiRL, for training in-the-wild device control agents through fine-tuning a pre-trained VLM in two stages: offline RL to initialize the model, followed by offline-to-online RL. To do this, we build a scalable and parallelizable Android learning environment equipped with a VLM-based evaluator and develop a simple yet effective RL approach for learning in this domain. Our approach runs advantage-weighted RL with advantage estimators enhanced to account for stochasticity along with an automatic curriculum for deriving maximal learning signal. We demonstrate the effectiveness of DigiRL using the Android-in-the-Wild (AitW) dataset, where our 1.3B VLM trained with RL achieves a 49.5% absolute improvement -- from 17.7 to 67.2% success rate -- over supervised fine-tuning with static human demonstration data. These results significantly surpass not only the prior best agents, including AppAgent with GPT-4V (8.3% success rate) and the 17B CogAgent trained with AitW data (38.5%), but also the prior best autonomous RL approach based on filtered behavior cloning (57.8%), thereby establishing a new state-of-the-art for digital agents for in-the-wild device control.