 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchEvolver: Frontier Task Synthesis via Solution-Centric Evolution
May 31, 2026The rapid progress of frontier large language models has led to widespread benchmark saturation, limiting the ability of existing datasets to differentiate model capabilities or provide useful training signal. For instance, on LiveCodeBench, frontier models achieve over 99% Pass@1 on easy splits and exceed 90% Pass@1 on average across difficulty levels. Constructing new, challenging datasets typically requires substantial human effort, creating a bottleneck for progress. We introduce BenchEvolver, a solution-centric evolutionary framework that automatically transforms existing coding problems into harder variants. Rather than generating problems from scratch, BenchEvolver evolves reference solutions through structured transformations and derives corresponding statements and tests from the evolved solutions. This design grounds generation in executable semantics, enabling scalable construction of high-quality, diverse, and difficult tasks with verifiable correctness. Applying BenchEvolver to LiveCodeBench and SciCode, we obtain evolved tasks that are substantially harder while maintaining validity, reference correctness, and diversity. We further curate LiveCodeBench-Plus, a 91-problem benchmark combining evolved and difficult original LCB-v6 tasks, where frontier-model Pass@1 ranges from 27.5% to 62.6%, restoring clear discrimination among strong coding models. Importantly, evolved tasks remain challenging even for the model that generates them, enabling self-improvement. We further show that RL on evolved LCB tasks improves held-out coding performance: for gpt-oss-20b, seed+evolved training achieves +8.7 and +8.3 Pass@1 gains on LCB v6 Hard and LCB-Pro Easy, exceeding seed-only gains by 70.7% and 34.8%, respectively. Our results show that BenchEvolver can convert saturated benchmarks into frontier-level evaluation suites and reusable training signal.
The Time is Here for Just-in-Time Systems: Challenges and Opportunities
May 22, 2026Core systems like key-value stores have historically taken years to build, and are designed to be general so as to amortize cost across deployments, paying a significant performance cost. We argue that LLM-based coding agents now make a different approach tractable: Just-in-Time Systems, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, and explore its effectiveness in synthesizing key-value stores from spec cards that span different YCSB workloads, deployment constraints (e.g., compute resources), and system properties (e.g., consistency and durability). Jitskit iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x. We discuss the challenges we overcame in building Jitskit and our key takeaways.
Inductive Deductive Synthesis: Enabling AI to Generate Formally Verified Systems
May 22, 2026AI agents increasingly excel at generating, testing, and refining code. However, they fall short on tasks requiring formal guarantees of full coverage that testing alone cannot provide. Distributed systems are a prime example: properties such as consistency between reads and writes must hold under every possible interleaving of events. Mechanized formal verification can guarantee such correctness, but typically demands months to years of expert effort. As evidence, even SOTA coding agents (Codex with GPT-5.4 and Claude Code with Opus 4.6) succeed on only 2/7 distributed key-value-store specifications. In this paper, we present the first effective approach to addressing this gap, Inductive Deductive Synthesis (IDS), which jointly and incrementally synthesizes implementation and proof, and learns from failed attempts to systematically try promising strategies. Built as an agentic LLM system, IDS achieves 7/7 in about 6.8 hours and $106 per spec on average, roughly 200x faster than expert effort and 17% cheaper than SOTA agents. IDS further incorporates performance feedback into the same loop, yielding implementations up to 3x faster than published verified systems.
AdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization
Feb 23, 2026The paradigm of automated program generation is shifting from one-shot generation to inference-time search, where Large Language Models (LLMs) function as semantic mutation operators within evolutionary loops. While effective, these systems are currently governed by static schedules that fail to account for the non-stationary dynamics of the search process. This rigidity results in substantial computational waste, as resources are indiscriminately allocated to stagnating populations while promising frontiers remain under-exploited. We introduce AdaEvolve, a framework that reformulates LLM-driven evolution as a hierarchical adaptive optimization problem. AdaEvolve uses an "accumulated improvement signal" to unify decisions across three levels: Local Adaptation, which dynamically modulates the exploration intensity within a population of solution candidates; Global Adaptation, which routes the global resource budget via bandit-based scheduling across different solution candidate populations; and Meta-Guidance which generates novel solution tactics based on the previously generated solutions and their corresponding improvements when the progress stalls. We demonstrate that AdaEvolve consistently outperforms the open-sourced baselines across 185 different open-ended optimization problems including combinatorial, systems optimization and algorithm design problems.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
COMPASS: A Multi-Turn Benchmark for Tool-Mediated Planning & Preference Optimization
Oct 08, 2025
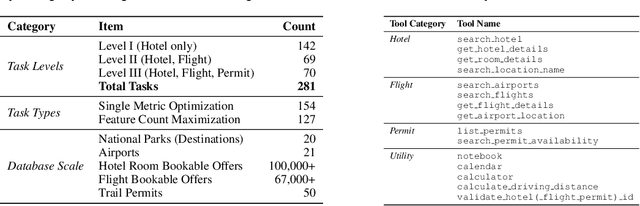
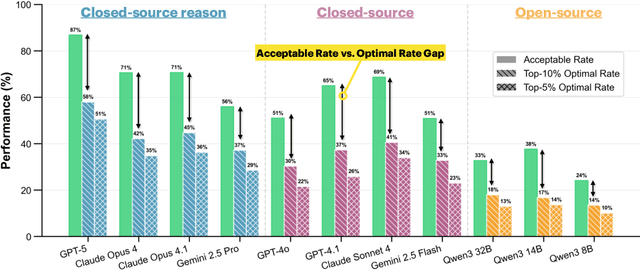

Real-world large language model (LLM) agents must master strategic tool use and user preference optimization through multi-turn interactions to assist users with complex planning tasks. We introduce COMPASS (Constrained Optimization through Multi-turn Planning and Strategic Solutions), a benchmark that evaluates agents on realistic travel-planning scenarios. We cast travel planning as a constrained preference optimization problem, where agents must satisfy hard constraints while simultaneously optimizing soft user preferences. To support this, we build a realistic travel database covering transportation, accommodation, and ticketing for 20 U.S. National Parks, along with a comprehensive tool ecosystem that mirrors commercial booking platforms. Evaluating state-of-the-art models, we uncover two critical gaps: (i) an acceptable-optimal gap, where agents reliably meet constraints but fail to optimize preferences, and (ii) a plan-coordination gap, where performance collapses on multi-service (flight and hotel) coordination tasks, especially for open-source models. By grounding reasoning and planning in a practical, user-facing domain, COMPASS provides a benchmark that directly measures an agent's ability to optimize user preferences in realistic tasks, bridging theoretical advances with real-world impact.
Why Do Multi-Agent LLM Systems Fail?
Mar 17, 2025Despite growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to accomplish tasks, their performance gains across popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the need to analyze the challenges hindering MAS effectiveness. In this paper, we present the first comprehensive study of MAS challenges. We analyze five popular MAS frameworks across over 150 tasks, involving six expert human annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerges iteratively from agreements among three expert annotators per study, achieving a Cohen's Kappa score of 0.88. These fine-grained failure modes are organized into 3 categories, (i) specification and system design failures, (ii) inter-agent misalignment, and (iii) task verification and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge. We also explore if identified failures could be easily prevented by proposing two interventions: improved specification of agent roles and enhanced orchestration strategies. Our findings reveal that identified failures require more complex solutions, highlighting a clear roadmap for future research. We open-source our dataset and LLM annotator.
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning
Jun 14, 2024Training corpuses for vision language models (VLMs) typically lack sufficient amounts of decision-centric data. This renders off-the-shelf VLMs sub-optimal for decision-making tasks such as in-the-wild device control through graphical user interfaces (GUIs). While training with static demonstrations has shown some promise, we show that such methods fall short for controlling real GUIs due to their failure to deal with real-world stochasticity and non-stationarity not captured in static observational data. This paper introduces a novel autonomous RL approach, called DigiRL, for training in-the-wild device control agents through fine-tuning a pre-trained VLM in two stages: offline RL to initialize the model, followed by offline-to-online RL. To do this, we build a scalable and parallelizable Android learning environment equipped with a VLM-based evaluator and develop a simple yet effective RL approach for learning in this domain. Our approach runs advantage-weighted RL with advantage estimators enhanced to account for stochasticity along with an automatic curriculum for deriving maximal learning signal. We demonstrate the effectiveness of DigiRL using the Android-in-the-Wild (AitW) dataset, where our 1.3B VLM trained with RL achieves a 49.5% absolute improvement -- from 17.7 to 67.2% success rate -- over supervised fine-tuning with static human demonstration data. These results significantly surpass not only the prior best agents, including AppAgent with GPT-4V (8.3% success rate) and the 17B CogAgent trained with AitW data (38.5%), but also the prior best autonomous RL approach based on filtered behavior cloning (57.8%), thereby establishing a new state-of-the-art for digital agents for in-the-wild device control.
Discovering Influencers in Opinion Formation over Social Graphs
Nov 23, 2022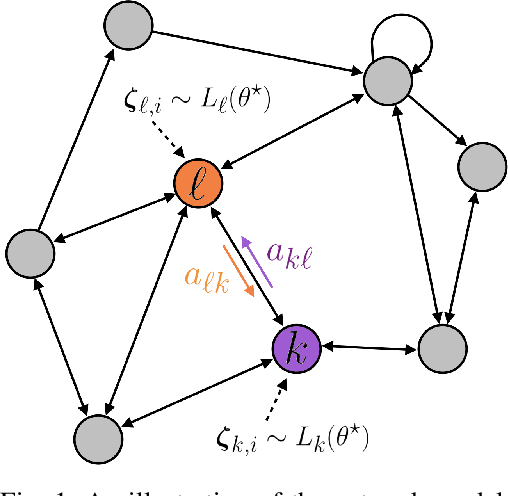
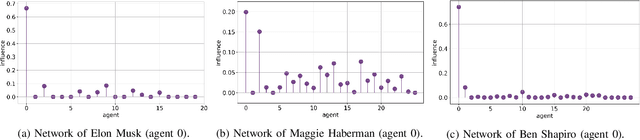
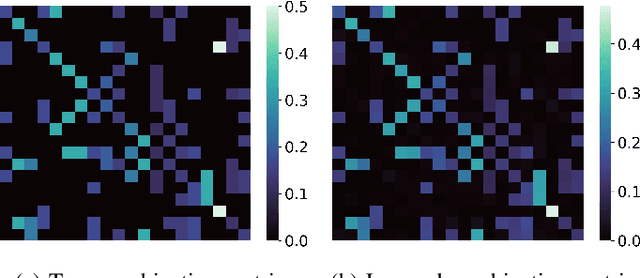
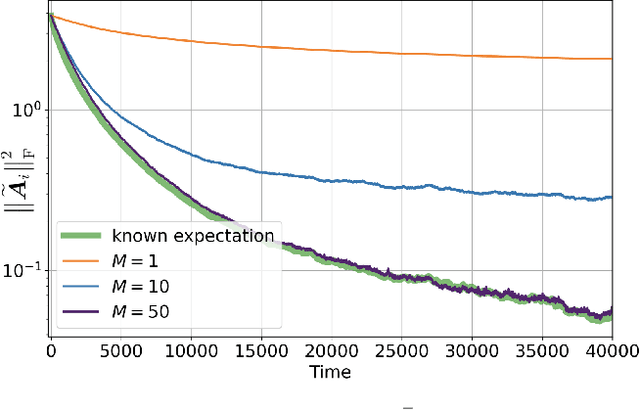
The adaptive social learning paradigm helps model how networked agents are able to form opinions on a state of nature and track its drifts in a changing environment. In this framework, the agents repeatedly update their beliefs based on private observations and exchange the beliefs with their neighbors. In this work, it is shown how the sequence of publicly exchanged beliefs over time allows users to discover rich information about the underlying network topology and about the flow of information over graph. In particular, it is shown that it is possible (i) to identify the influence of each individual agent to the objective of truth learning, (ii) to discover how well informed each agent is, (iii) to quantify the pairwise influences between agents, and (iv) to learn the underlying network topology. The algorithm derived herein is also able to work under non-stationary environments where either the true state of nature or the network topology are allowed to drift over time. We apply the proposed algorithm to different subnetworks of Twitter users, and identify the most influential and central agents merely by using their public tweets (posts).
Unsupervised Simplification of Legal Texts
Sep 01, 2022
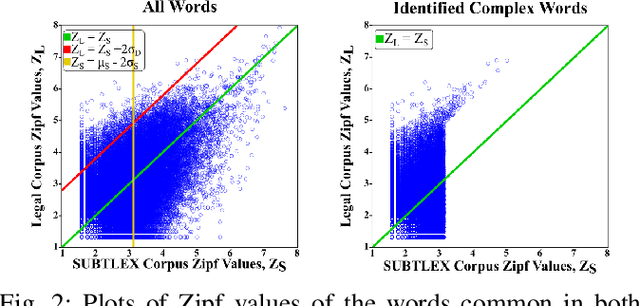
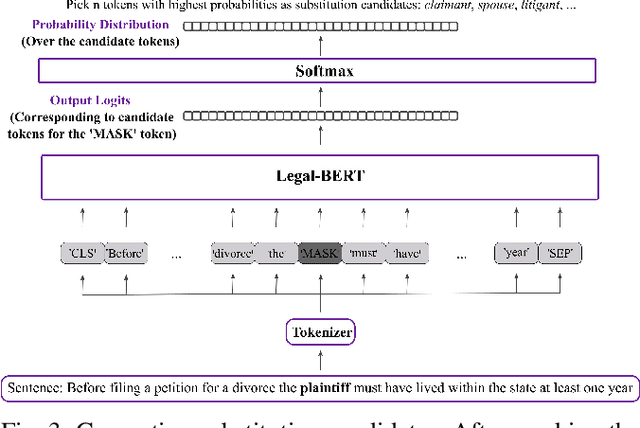

The processing of legal texts has been developing as an emerging field in natural language processing (NLP). Legal texts contain unique jargon and complex linguistic attributes in vocabulary, semantics, syntax, and morphology. Therefore, the development of text simplification (TS) methods specific to the legal domain is of paramount importance for facilitating comprehension of legal text by ordinary people and providing inputs to high-level models for mainstream legal NLP applications. While a recent study proposed a rule-based TS method for legal text, learning-based TS in the legal domain has not been considered previously. Here we introduce an unsupervised simplification method for legal texts (USLT). USLT performs domain-specific TS by replacing complex words and splitting long sentences. To this end, USLT detects complex words in a sentence, generates candidates via a masked-transformer model, and selects a candidate for substitution based on a rank score. Afterward, USLT recursively decomposes long sentences into a hierarchy of shorter core and context sentences while preserving semantic meaning. We demonstrate that USLT outperforms state-of-the-art domain-general TS methods in text simplicity while keeping the semantics intact.