 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Anytime-Valid Statistical Watermarking
Feb 19, 2026The proliferation of Large Language Models (LLMs) necessitates efficient mechanisms to distinguish machine-generated content from human text. While statistical watermarking has emerged as a promising solution, existing methods suffer from two critical limitations: the lack of a principled approach for selecting sampling distributions and the reliance on fixed-horizon hypothesis testing, which precludes valid early stopping. In this paper, we bridge this gap by developing the first e-value-based watermarking framework, Anchored E-Watermarking, that unifies optimal sampling with anytime-valid inference. Unlike traditional approaches where optional stopping invalidates Type-I error guarantees, our framework enables valid, anytime-inference by constructing a test supermartingale for the detection process. By leveraging an anchor distribution to approximate the target model, we characterize the optimal e-value with respect to the worst-case log-growth rate and derive the optimal expected stopping time. Our theoretical claims are substantiated by simulations and evaluations on established benchmarks, showing that our framework can significantly enhance sample efficiency, reducing the average token budget required for detection by 13-15% relative to state-of-the-art baselines.
Adaptive Sparse Möbius Transforms for Learning Polynomials
Feb 05, 2026We consider the problem of exactly learning an $s$-sparse real-valued Boolean polynomial of degree $d$ of the form $f:\{ 0,1\}^n \rightarrow \mathbb{R}$. This problem corresponds to decomposing functions in the AND basis and is known as taking a Möbius transform. While the analogous problem for the parity basis (Fourier transform) $f: \{-1,1 \}^n \rightarrow \mathbb{R}$ is well-understood, the AND basis presents a unique challenge: the basis vectors are coherent, precluding standard compressed sensing methods. We overcome this challenge by identifying that we can exploit adaptive group testing to provide a constructive, query-efficient implementation of the Möbius transform (also known as Möbius inversion) for sparse functions. We present two algorithms based on this insight. The Fully-Adaptive Sparse Möbius Transform (FASMT) uses $O(sd \log(n/d))$ adaptive queries in $O((sd + n) sd \log(n/d))$ time, which we show is near-optimal in query complexity. Furthermore, we also present the Partially-Adaptive Sparse Möbius Transform (PASMT), which uses $O(sd^2\log(n/d))$ queries, trading a factor of $d$ to reduce the number of adaptive rounds to $O(d^2\log(n/d))$, with no dependence on $s$. When applied to hypergraph reconstruction from edge-count queries, our results improve upon baselines by avoiding the combinatorial explosion in the rank $d$. We demonstrate the practical utility of our method for hypergraph reconstruction by applying it to learning real hypergraphs in simulations.
A Positive Case for Faithfulness: LLM Self-Explanations Help Predict Model Behavior
Feb 02, 2026LLM self-explanations are often presented as a promising tool for AI oversight, yet their faithfulness to the model's true reasoning process is poorly understood. Existing faithfulness metrics have critical limitations, typically relying on identifying unfaithfulness via adversarial prompting or detecting reasoning errors. These methods overlook the predictive value of explanations. We introduce Normalized Simulatability Gain (NSG), a general and scalable metric based on the idea that a faithful explanation should allow an observer to learn a model's decision-making criteria, and thus better predict its behavior on related inputs. We evaluate 18 frontier proprietary and open-weight models, e.g., Gemini 3, GPT-5.2, and Claude 4.5, on 7,000 counterfactuals from popular datasets covering health, business, and ethics. We find self-explanations substantially improve prediction of model behavior (11-37% NSG). Self-explanations also provide more predictive information than explanations generated by external models, even when those models are stronger. This implies an advantage from self-knowledge that external explanation methods cannot replicate. Our approach also reveals that, across models, 5-15% of self-explanations are egregiously misleading. Despite their imperfections, we show a positive case for self-explanations: they encode information that helps predict model behavior.
An Odd Estimator for Shapley Values
Feb 01, 2026The Shapley value is a ubiquitous framework for attribution in machine learning, encompassing feature importance, data valuation, and causal inference. However, its exact computation is generally intractable, necessitating efficient approximation methods. While the most effective and popular estimators leverage the paired sampling heuristic to reduce estimation error, the theoretical mechanism driving this improvement has remained opaque. In this work, we provide an elegant and fundamental justification for paired sampling: we prove that the Shapley value depends exclusively on the odd component of the set function, and that paired sampling orthogonalizes the regression objective to filter out the irrelevant even component. Leveraging this insight, we propose OddSHAP, a novel consistent estimator that performs polynomial regression solely on the odd subspace. By utilizing the Fourier basis to isolate this subspace and employing a proxy model to identify high-impact interactions, OddSHAP overcomes the combinatorial explosion of higher-order approximations. Through an extensive benchmark evaluation, we find that OddSHAP achieves state-of-the-art estimation accuracy.
Sample Complexity and Representation Ability of Test-time Scaling Paradigms
Jun 05, 2025Test-time scaling paradigms have significantly advanced the capabilities of large language models (LLMs) on complex tasks. Despite their empirical success, theoretical understanding of the sample efficiency of various test-time strategies -- such as self-consistency, best-of-$n$, and self-correction -- remains limited. In this work, we first establish a separation result between two repeated sampling strategies: self-consistency requires $\Theta(1/\Delta^2)$ samples to produce the correct answer, while best-of-$n$ only needs $\Theta(1/\Delta)$, where $\Delta < 1$ denotes the probability gap between the correct and second most likely answers. Next, we present an expressiveness result for the self-correction approach with verifier feedback: it enables Transformers to simulate online learning over a pool of experts at test time. Therefore, a single Transformer architecture can provably solve multiple tasks without prior knowledge of the specific task associated with a user query, extending the representation theory of Transformers from single-task to multi-task settings. Finally, we empirically validate our theoretical results, demonstrating the practical effectiveness of self-correction methods.
ProxySPEX: Inference-Efficient Interpretability via Sparse Feature Interactions in LLMs
May 23, 2025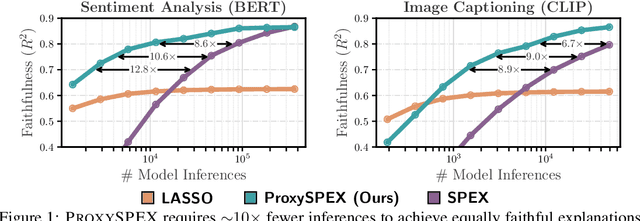

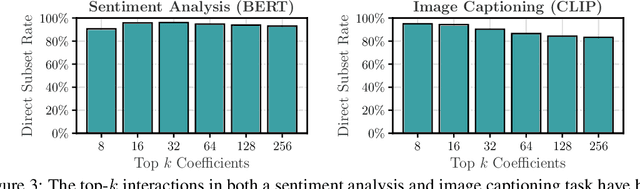
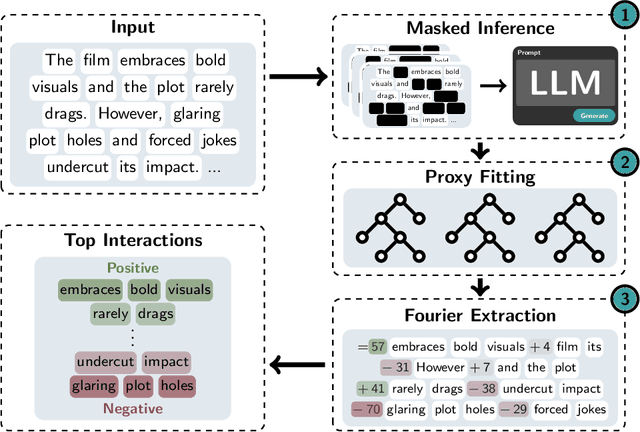
Large Language Models (LLMs) have achieved remarkable performance by capturing complex interactions between input features. To identify these interactions, most existing approaches require enumerating all possible combinations of features up to a given order, causing them to scale poorly with the number of inputs $n$. Recently, Kang et al. (2025) proposed SPEX, an information-theoretic approach that uses interaction sparsity to scale to $n \approx 10^3$ features. SPEX greatly improves upon prior methods but requires tens of thousands of model inferences, which can be prohibitive for large models. In this paper, we observe that LLM feature interactions are often hierarchical -- higher-order interactions are accompanied by their lower-order subsets -- which enables more efficient discovery. To exploit this hierarchy, we propose ProxySPEX, an interaction attribution algorithm that first fits gradient boosted trees to masked LLM outputs and then extracts the important interactions. Experiments across four challenging high-dimensional datasets show that ProxySPEX more faithfully reconstructs LLM outputs by 20% over marginal attribution approaches while using $10\times$ fewer inferences than SPEX. By accounting for interactions, ProxySPEX identifies features that influence model output over 20% more than those selected by marginal approaches. Further, we apply ProxySPEX to two interpretability tasks. Data attribution, where we identify interactions among CIFAR-10 training samples that influence test predictions, and mechanistic interpretability, where we uncover interactions between attention heads, both within and across layers, on a question-answering task. ProxySPEX identifies interactions that enable more aggressive pruning of heads than marginal approaches.
Double Blind Imaging with Generative Modeling
Mar 27, 2025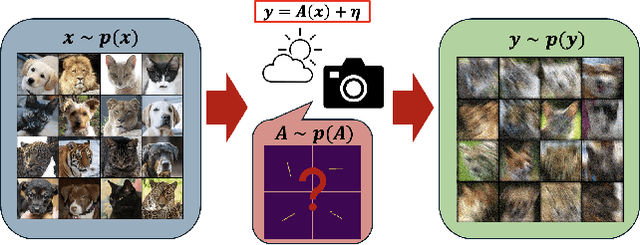
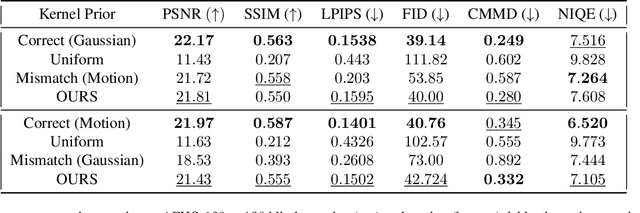
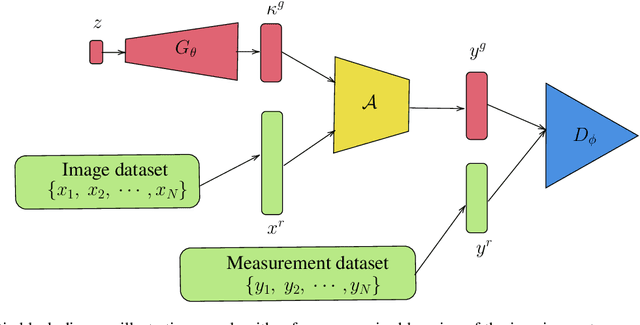
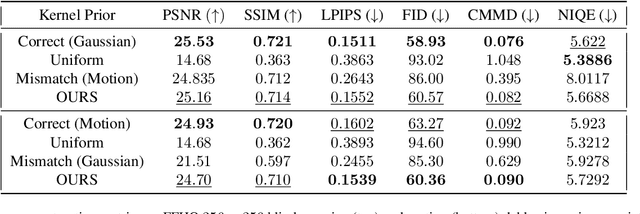
Blind inverse problems in imaging arise from uncertainties in the system used to collect (noisy) measurements of images. Recovering clean images from these measurements typically requires identifying the imaging system, either implicitly or explicitly. A common solution leverages generative models as priors for both the images and the imaging system parameters (e.g., a class of point spread functions). To learn these priors in a straightforward manner requires access to a dataset of clean images as well as samples of the imaging system. We propose an AmbientGAN-based generative technique to identify the distribution of parameters in unknown imaging systems, using only unpaired clean images and corrupted measurements. This learned distribution can then be used in model-based recovery algorithms to solve blind inverse problems such as blind deconvolution. We successfully demonstrate our technique for learning Gaussian blur and motion blur priors from noisy measurements and show their utility in solving blind deconvolution with diffusion posterior sampling.
Why Do Multi-Agent LLM Systems Fail?
Mar 17, 2025Despite growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to accomplish tasks, their performance gains across popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the need to analyze the challenges hindering MAS effectiveness. In this paper, we present the first comprehensive study of MAS challenges. We analyze five popular MAS frameworks across over 150 tasks, involving six expert human annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerges iteratively from agreements among three expert annotators per study, achieving a Cohen's Kappa score of 0.88. These fine-grained failure modes are organized into 3 categories, (i) specification and system design failures, (ii) inter-agent misalignment, and (iii) task verification and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge. We also explore if identified failures could be easily prevented by proposing two interventions: improved specification of agent roles and enhanced orchestration strategies. Our findings reveal that identified failures require more complex solutions, highlighting a clear roadmap for future research. We open-source our dataset and LLM annotator.
Online Assortment and Price Optimization Under Contextual Choice Models
Mar 14, 2025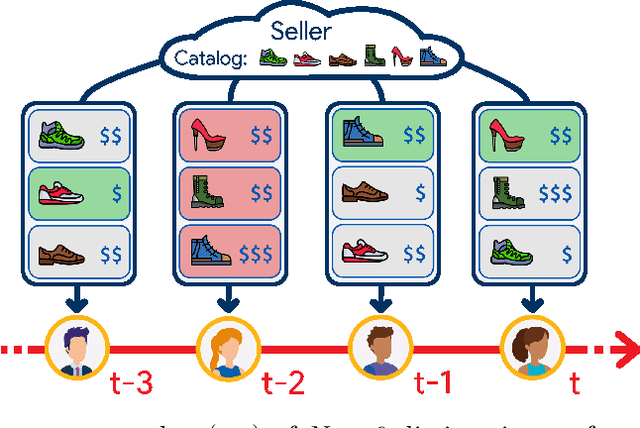

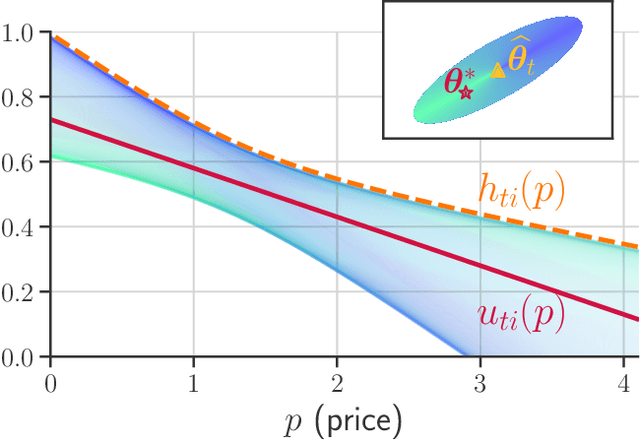
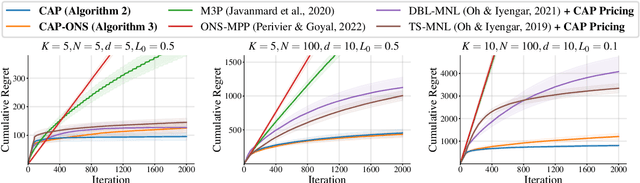
We consider an assortment selection and pricing problem in which a seller has $N$ different items available for sale. In each round, the seller observes a $d$-dimensional contextual preference information vector for the user, and offers to the user an assortment of $K$ items at prices chosen by the seller. The user selects at most one of the products from the offered assortment according to a multinomial logit choice model whose parameters are unknown. The seller observes which, if any, item is chosen at the end of each round, with the goal of maximizing cumulative revenue over a selling horizon of length $T$. For this problem, we propose an algorithm that learns from user feedback and achieves a revenue regret of order $\widetilde{O}(d \sqrt{K T} / L_0 )$ where $L_0$ is the minimum price sensitivity parameter. We also obtain a lower bound of order $\Omega(d \sqrt{T}/ L_0)$ for the regret achievable by any algorithm.
SPEX: Scaling Feature Interaction Explanations for LLMs
Feb 19, 2025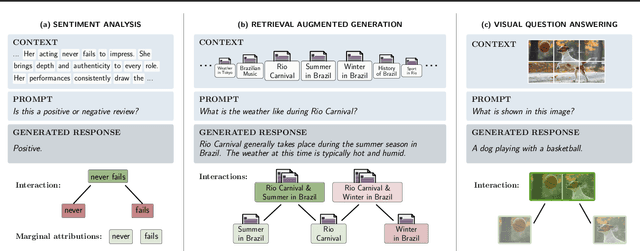

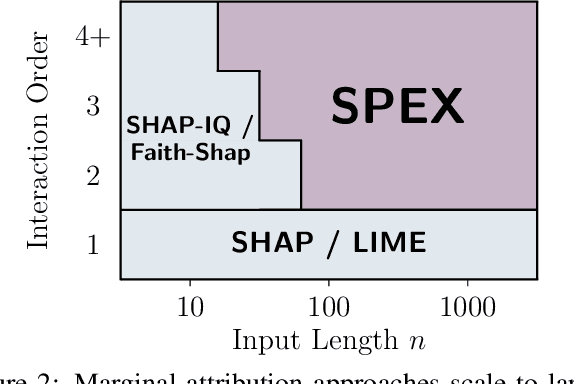
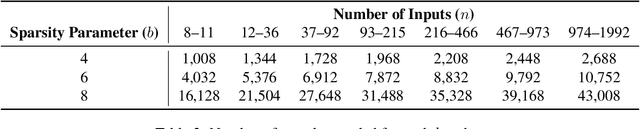
Large language models (LLMs) have revolutionized machine learning due to their ability to capture complex interactions between input features. Popular post-hoc explanation methods like SHAP provide marginal feature attributions, while their extensions to interaction importances only scale to small input lengths ($\approx 20$). We propose Spectral Explainer (SPEX), a model-agnostic interaction attribution algorithm that efficiently scales to large input lengths ($\approx 1000)$. SPEX exploits underlying natural sparsity among interactions -- common in real-world data -- and applies a sparse Fourier transform using a channel decoding algorithm to efficiently identify important interactions. We perform experiments across three difficult long-context datasets that require LLMs to utilize interactions between inputs to complete the task. For large inputs, SPEX outperforms marginal attribution methods by up to 20% in terms of faithfully reconstructing LLM outputs. Further, SPEX successfully identifies key features and interactions that strongly influence model output. For one of our datasets, HotpotQA, SPEX provides interactions that align with human annotations. Finally, we use our model-agnostic approach to generate explanations to demonstrate abstract reasoning in closed-source LLMs (GPT-4o mini) and compositional reasoning in vision-language models.