 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrective Diffusion Language Models
Dec 17, 2025
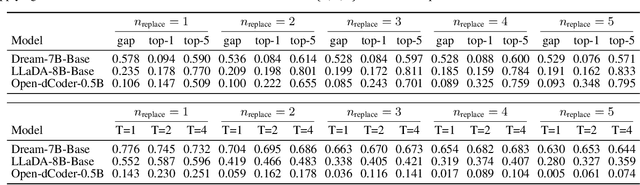
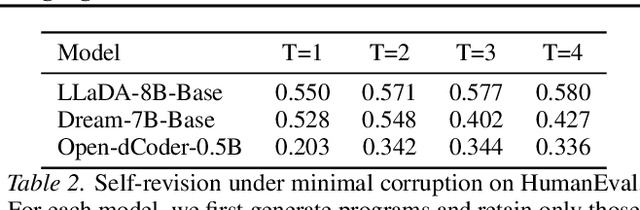
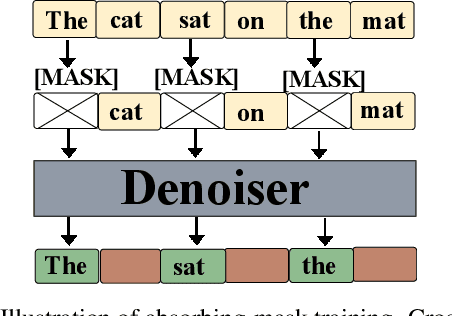
Diffusion language models are structurally well-suited for iterative error correction, as their non-causal denoising dynamics allow arbitrary positions in a sequence to be revised. However, standard masked diffusion language model (MDLM) training fails to reliably induce this behavior, as models often cannot identify unreliable tokens in a complete input, rendering confidence-guided refinement ineffective. We study corrective behavior in diffusion language models, defined as the ability to assign lower confidence to incorrect tokens and iteratively refine them while preserving correct content. We show that this capability is not induced by conventional masked diffusion objectives and propose a correction-oriented post-training principle that explicitly supervises visible incorrect tokens, enabling error-aware confidence and targeted refinement. To evaluate corrective behavior, we introduce the Code Revision Benchmark (CRB), a controllable and executable benchmark for assessing error localization and in-place correction. Experiments on code revision tasks and controlled settings demonstrate that models trained with our approach substantially outperform standard MDLMs in correction scenarios, while also improving pure completion performance. Our code is publicly available at https://github.com/zhangshuibai/CDLM.
ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs
Oct 06, 2025While most autoregressive LLMs are constrained to one-by-one decoding, diffusion LLMs (dLLMs) have attracted growing interest for their potential to dramatically accelerate inference through parallel decoding. Despite this promise, the conditional independence assumption in dLLMs causes parallel decoding to ignore token dependencies, inevitably degrading generation quality when these dependencies are strong. However, existing works largely overlook these inherent challenges, and evaluations on standard benchmarks (e.g., math and coding) are not sufficient to capture the quality degradation caused by parallel decoding. To address this gap, we first provide an information-theoretic analysis of parallel decoding. We then conduct case studies on analytically tractable synthetic list operations from both data distribution and decoding strategy perspectives, offering quantitative insights that highlight the fundamental limitations of parallel decoding. Building on these insights, we propose ParallelBench, the first benchmark specifically designed for dLLMs, featuring realistic tasks that are trivial for humans and autoregressive LLMs yet exceptionally challenging for dLLMs under parallel decoding. Using ParallelBench, we systematically analyze both dLLMs and autoregressive LLMs, revealing that: (i) dLLMs under parallel decoding can suffer dramatic quality degradation in real-world scenarios, and (ii) current parallel decoding strategies struggle to adapt their degree of parallelism based on task difficulty, thus failing to achieve meaningful speedup without compromising quality. Our findings underscore the pressing need for innovative decoding methods that can overcome the current speed-quality trade-off. We release our benchmark to help accelerate the development of truly efficient dLLMs.
VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
Feb 10, 2025



Process Reward Models (PRMs) have proven effective at enhancing mathematical reasoning for Large Language Models (LLMs) by leveraging increased inference-time computation. However, they are predominantly trained on mathematical data and their generalizability to non-mathematical domains has not been rigorously studied. In response, this work first shows that current PRMs have poor performance in other domains. To address this limitation, we introduce VersaPRM, a multi-domain PRM trained on synthetic reasoning data generated using our novel data generation and annotation method. VersaPRM achieves consistent performance gains across diverse domains. For instance, in the MMLU-Pro category of Law, VersaPRM via weighted majority voting, achieves a 7.9% performance gain over the majority voting baseline -- surpassing Qwen2.5-Math-PRM's gain of 1.3%. We further contribute to the community by open-sourcing all data, code and models for VersaPRM.
Dynamic Multimodal Evaluation with Flexible Complexity by Vision-Language Bootstrapping
Oct 11, 2024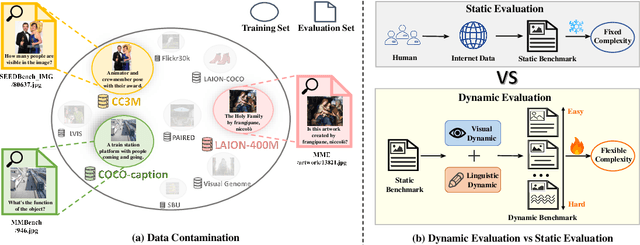

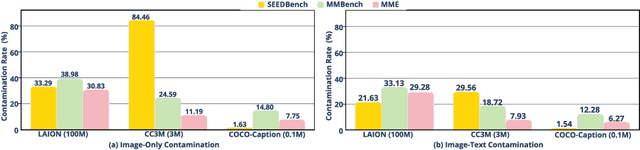

Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across multimodal tasks such as visual perception and reasoning, leading to good performance on various multimodal evaluation benchmarks. However, these benchmarks keep a static nature and overlap with the pre-training data, resulting in fixed complexity constraints and data contamination issues. This raises the concern regarding the validity of the evaluation. To address these two challenges, we introduce a dynamic multimodal evaluation protocol called Vision-Language Bootstrapping (VLB). VLB provides a robust and comprehensive assessment for LVLMs with reduced data contamination and flexible complexity. To this end, VLB dynamically generates new visual question-answering samples through a multimodal bootstrapping module that modifies both images and language, while ensuring that newly generated samples remain consistent with the original ones by a judge module. By composing various bootstrapping strategies, VLB offers dynamic variants of existing benchmarks with diverse complexities, enabling the evaluation to co-evolve with the ever-evolving capabilities of LVLMs. Extensive experimental results across multiple benchmarks, including SEEDBench, MMBench, and MME, show that VLB significantly reduces data contamination and exposes performance limitations of LVLMs.
Supervised Knowledge Makes Large Language Models Better In-context Learners
Dec 26, 2023



Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective
Nov 15, 2022
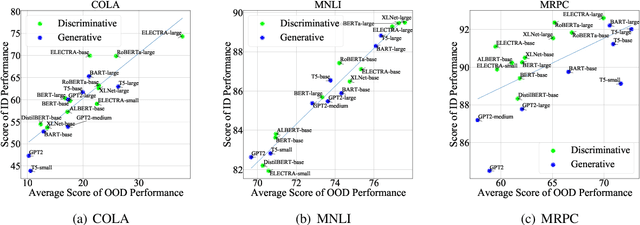


Pre-trained language models (PLMs) improve the model generalization by leveraging massive data as the training corpus in the pre-training phase. However, currently, the out-of-distribution (OOD) generalization becomes a generally ill-posed problem, even for the large-scale PLMs in natural language understanding tasks, which prevents the deployment of NLP methods in the real world. To facilitate the research in this direction, this paper makes the first attempt to establish a unified benchmark named GLUE-X, highlighting the importance of OOD robustness and providing insights on how to measure the robustness of a model and how to improve it. To this end, we collect 13 publicly available datasets as OOD test data, and conduct evaluations on 8 classic NLP tasks over \emph{18} popularly used models. Our findings confirm that the OOD accuracy in NLP tasks needs to be paid more attention to since the significant performance decay compared to ID accuracy has been found in all settings.