 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Feedback for Handheld Tool Guidance: Combining Wrist-Based Haptics with Augmented Reality
Jan 17, 2026We investigate how vibrotactile wrist feedback can enhance spatial guidance for handheld tool movement in optical see-through augmented reality (AR). While AR overlays are widely used to support surgical tasks, visual occlusion, lighting conditions, and interface ambiguity can compromise precision and confidence. To address these challenges, we designed a multimodal system combining AR visuals with a custom wrist-worn haptic device delivering directional and state-based cues. A formative study with experienced surgeons and residents identified key tool maneuvers and preferences for reference mappings, guiding our cue design. In a cue identification experiment (N=21), participants accurately recognized five vibration patterns under visual load, with higher recognition for full-actuator states than spatial direction cues. In a guidance task (N=27), participants using both AR and haptics achieved significantly higher spatial precision (5.8 mm) and usability (SUS = 88.1) than those using either modality alone, despite having modest increases in task time. Participants reported that haptic cues provided reassuring confirmation and reduced cognitive effort during alignment. Our results highlight the promise of integrating wrist-based haptics into AR systems for high-precision, visually complex tasks such as surgical guidance. We discuss design implications for multimodal interfaces supporting confident, efficient tool manipulation.
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
Safe-FedLLM: Delving into the Safety of Federated Large Language Models
Jan 12, 2026Federated learning (FL) addresses data privacy and silo issues in large language models (LLMs). Most prior work focuses on improving the training efficiency of federated LLMs. However, security in open environments is overlooked, particularly defenses against malicious clients. To investigate the safety of LLMs during FL, we conduct preliminary experiments to analyze potential attack surfaces and defensible characteristics from the perspective of Low-Rank Adaptation (LoRA) weights. We find two key properties of FL: 1) LLMs are vulnerable to attacks from malicious clients in FL, and 2) LoRA weights exhibit distinct behavioral patterns that can be filtered through simple classifiers. Based on these properties, we propose Safe-FedLLM, a probe-based defense framework for federated LLMs, constructing defenses across three dimensions: Step-Level, Client-Level, and Shadow-Level. The core concept of Safe-FedLLM is to perform probe-based discrimination on the LoRA weights locally trained by each client during FL, treating them as high-dimensional behavioral features and using lightweight classification models to determine whether they possess malicious attributes. Extensive experiments demonstrate that Safe-FedLLM effectively enhances the defense capability of federated LLMs without compromising performance on benign data. Notably, our method effectively suppresses malicious data impact without significant impact on training speed, and remains effective even with many malicious clients. Our code is available at: https://github.com/dmqx/Safe-FedLLM.
Milestones over Outcome: Unlocking Geometric Reasoning with Sub-Goal Verifiable Reward
Jan 08, 2026Multimodal Large Language Models (MLLMs) struggle with complex geometric reasoning, largely because "black box" outcome-based supervision fails to distinguish between lucky guesses and rigorous deduction. To address this, we introduce a paradigm shift towards subgoal-level evaluation and learning. We first construct GeoGoal, a benchmark synthesized via a rigorous formal verification data engine, which converts abstract proofs into verifiable numeric subgoals. This structure reveals a critical divergence between reasoning quality and outcome accuracy. Leveraging this, we propose the Sub-Goal Verifiable Reward (SGVR) framework, which replaces sparse signals with dense rewards based on the Skeleton Rate. Experiments demonstrate that SGVR not only enhances geometric performance (+9.7%) but also exhibits strong generalization, transferring gains to general math (+8.0%) and other general reasoning tasks (+2.8%), demonstrating broad applicability across diverse domains.
GeoBench: Rethinking Multimodal Geometric Problem-Solving via Hierarchical Evaluation
Dec 30, 2025Geometric problem solving constitutes a critical branch of mathematical reasoning, requiring precise analysis of shapes and spatial relationships. Current evaluations of geometric reasoning in vision-language models (VLMs) face limitations, including the risk of test data contamination from textbook-based benchmarks, overemphasis on final answers over reasoning processes, and insufficient diagnostic granularity. To address these issues, we present GeoBench, a hierarchical benchmark featuring four reasoning levels in geometric problem-solving: Visual Perception, Goal-Oriented Planning, Rigorous Theorem Application, and Self-Reflective Backtracking. Through six formally verified tasks generated via TrustGeoGen, we systematically assess capabilities ranging from attribute extraction to logical error correction. Experiments reveal that while reasoning models like OpenAI-o3 outperform general MLLMs, performance declines significantly with increasing task complexity. Key findings demonstrate that sub-goal decomposition and irrelevant premise filtering critically influence final problem-solving accuracy, whereas Chain-of-Thought prompting unexpectedly degrades performance in some tasks. These findings establish GeoBench as a comprehensive benchmark while offering actionable guidelines for developing geometric problem-solving systems.
CFD-copilot: leveraging domain-adapted large language model and model context protocol to enhance simulation automation
Dec 08, 2025

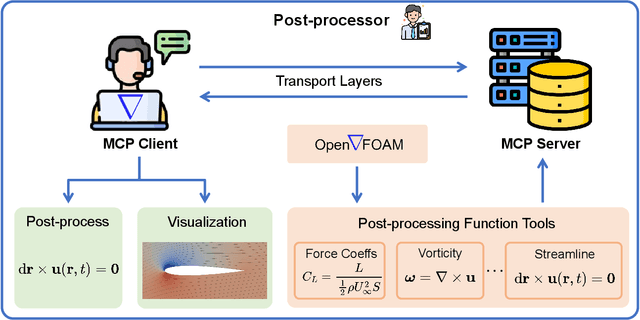

Configuring computational fluid dynamics (CFD) simulations requires significant expertise in physics modeling and numerical methods, posing a barrier to non-specialists. Although automating scientific tasks with large language models (LLMs) has attracted attention, applying them to the complete, end-to-end CFD workflow remains a challenge due to its stringent domain-specific requirements. We introduce CFD-copilot, a domain-specialized LLM framework designed to facilitate natural language-driven CFD simulation from setup to post-processing. The framework employs a fine-tuned LLM to directly translate user descriptions into executable CFD setups. A multi-agent system integrates the LLM with simulation execution, automatic error correction, and result analysis. For post-processing, the framework utilizes the model context protocol (MCP), an open standard that decouples LLM reasoning from external tool execution. This modular design allows the LLM to interact with numerous specialized post-processing functions through a unified and scalable interface, improving the automation of data extraction and analysis. The framework was evaluated on benchmarks including the NACA~0012 airfoil and the three-element 30P-30N airfoil. The results indicate that domain-specific adaptation and the incorporation of the MCP jointly enhance the reliability and efficiency of LLM-driven engineering workflows.
One Request, Multiple Experts: LLM Orchestrates Domain Specific Models via Adaptive Task Routing
Nov 16, 2025With the integration of massive distributed energy resources and the widespread participation of novel market entities, the operation of active distribution networks (ADNs) is progressively evolving into a complex multi-scenario, multi-objective problem. Although expert engineers have developed numerous domain specific models (DSMs) to address distinct technical problems, mastering, integrating, and orchestrating these heterogeneous DSMs still entail considerable overhead for ADN operators. Therefore, an intelligent approach is urgently required to unify these DSMs and enable efficient coordination. To address this challenge, this paper proposes the ADN-Agent architecture, which leverages a general large language model (LLM) to coordinate multiple DSMs, enabling adaptive intent recognition, task decomposition, and DSM invocation. Within the ADN-Agent, we design a novel communication mechanism that provides a unified and flexible interface for diverse heterogeneous DSMs. Finally, for some language-intensive subtasks, we propose an automated training pipeline for fine-tuning small language models, thereby effectively enhancing the overall problem-solving capability of the system. Comprehensive comparisons and ablation experiments validate the efficacy of the proposed method and demonstrate that the ADN-Agent architecture outperforms existing LLM application paradigms.
Data-driven quantum Koopman method for simulating nonlinear dynamics
Jul 29, 2025



Quantum computation offers potential exponential speedups for simulating certain physical systems, but its application to nonlinear dynamics is inherently constrained by the requirement of unitary evolution. We propose the quantum Koopman method (QKM), a data-driven framework that bridges this gap through transforming nonlinear dynamics into linear unitary evolution in higher-dimensional observable spaces. Leveraging the Koopman operator theory to achieve a global linearization, our approach maps system states into a hierarchy of Hilbert spaces using a deep autoencoder. Within the linearized embedding spaces, the state representation is decomposed into modulus and phase components, and the evolution is governed by a set of unitary Koopman operators that act exclusively on the phase. These operators are constructed from diagonal Hamiltonians with coefficients learned from data, a structure designed for efficient implementation on quantum hardware. This architecture enables direct multi-step prediction, and the operator's computational complexity scales logarithmically with the observable space dimension. The QKM is validated across diverse nonlinear systems. Its predictions maintain relative errors below 6% for reaction-diffusion systems and shear flows, and capture key statistics in 2D turbulence. This work establishes a practical pathway for quantum-accelerated simulation of nonlinear phenomena, exploring a framework built on the synergy between deep learning for global linearization and quantum algorithms for unitary dynamics evolution.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Fine-tuning a Large Language Model for Automating Computational Fluid Dynamics Simulations
Apr 21, 2025



Configuring computational fluid dynamics (CFD) simulations typically demands extensive domain expertise, limiting broader access. Although large language models (LLMs) have advanced scientific computing, their use in automating CFD workflows is underdeveloped. We introduce a novel approach centered on domain-specific LLM adaptation. By fine-tuning Qwen2.5-7B-Instruct on NL2FOAM, our custom dataset of 28716 natural language-to-OpenFOAM configuration pairs with chain-of-thought (CoT) annotations, we enable direct translation from natural language descriptions to executable CFD setups. A multi-agent framework orchestrates the process, autonomously verifying inputs, generating configurations, running simulations, and correcting errors. Evaluation on a benchmark of 21 diverse flow cases demonstrates state-of-the-art performance, achieving 88.7% solution accuracy and 82.6% first-attempt success rate. This significantly outperforms larger general-purpose models like Qwen2.5-72B-Instruct, DeepSeek-R1, and Llama3.3-70B-Instruct, while also requiring fewer correction iterations and maintaining high computational efficiency. The results highlight the critical role of domain-specific adaptation in deploying LLM assistants for complex engineering workflows. Our code and fine-tuned model have been deposited at https://github.com/YYgroup/AutoCFD.