 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatchAct: A Benchmark for Behavior-Grounded Robot Manipulation
Jun 24, 2026A robot working alongside people must reason about what they have done, in what order, and with what intent. Video carries the spatial layouts, object histories, and gestures that language leaves underspecified, yet today's manipulation benchmarks pair an instruction with a single current image, offering no way to evaluate reasoning over observed human behavior. We introduce WatchAct, a benchmark for robot manipulation grounded in observed human behavior. Each instance pairs a real-world human-action video and a language instruction with an aligned simulator scene and an executable LIBERO task, enabling scalable and reproducible evaluation. WatchAct comprises 3,000 long-horizon instances across 14 tasks in four capability domains drawn from the cognitive demands of watching another agent: parsing events (Event Grounding), recovering procedural structure (Procedural Reasoning), inferring unstated intent (Implicit Intent Inference), and tracking how the scene was changed (Episodic Reasoning). We further propose a disentangled evaluation protocol that separately measures (i)~video-to-plan reasoning by vision-language models, (ii)~policy execution under oracle plans, and (iii)~full task completion by integrated planner--policy pipelines. In both simulation and on a Franka Research 3 robot, current systems remain far from solving WatchAct. The best pipeline, Gemini-3.1-Pro with $π_{0.5}$, reaches only 16.3% Success Rate (SR) in simulation and 14.0% on the real robot. Gemini-3.1-Pro attains just 36.8% Plan SR (vs. 97.1% for humans), while $π_{0.5}$ reaches only 21.5% Task SR under oracle plans and drops to 10.6% on out-of-domain scenarios. Dataset and code are available at https://baiqi-li.github.io/watchact_page/.
SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence
May 29, 2026True video intelligence demands more than recognizing what is visible: it requires reasoning about why events unfold, predicting what would change under different conditions, and deciding what to do next. We refer to this progression, from perception through causal reasoning and simulation to strategic planning, as Strategic Video Intelligence (SVI). No existing benchmark evaluates this capability stack: in-the-wild videos lack verifiable ground truth for causal and strategic questions, while synthetic environments sacrifice the complexity of real multi-agent systems. To bridge this gap, we introduce SVI-Bench, a large-scale benchmark that leverages team sports as a dynamic microworld, combining the complexity of real-world multi-agent interaction (10-22 agents making coordinated decisions under adversarial pressure) with the verifiability of explicit rules and definitive outcomes. SVI-Bench comprises approximately 35K hours of broadcast video, 15M annotated actions, 15K hours of expert commentary, 23K game reports, and 103K structured statistical records across basketball, soccer, and hockey, all constructed via a data engine that transforms raw game data into a dense, cross-referenced corpus. We organize evaluation into 9 tasks spanning a progressive four-pillar hierarchy: Dynamic Scene Understanding, Causal Reasoning, Strategic Simulation, and Agentic Synthesis. Evaluating strong multimodal and agentic baselines, we find a capability cliff: models perform competently on perceptual tasks, achieving approximately 73% on fine-grained action QA, but degrade sharply at each successive cognitive level. Agentic tasks prove hardest: the strongest model achieves only 5% accuracy when required to autonomously gather and integrate evidence across a corpus of 1.8M clips.
TeDiO: Temporal Diagonal Optimization for Training-Free Coherent Video Diffusion
May 13, 2026Recent text-to-video diffusion transformers generate visually compelling frames, yet still struggle with temporal coherence, often producing flickering, drifting, or unstable motion. We show that these failures leave a clear imprint inside the model: incoherent videos consistently exhibit irregular, fragmented temporal diagonals in their intermediate self-attention maps, whereas stable motion corresponds to smooth, band-diagonal patterns. Building on this observation, we introduce TeDiO, a training-free, inference-time method that reinforces temporal consistency by regularizing these internal attention patterns. TeDiO estimates diagonal smoothness, identifies unstable regions, and performs lightweight latent updates that promote coherent frame-to-frame dynamics, without modifying model weights or using external motion supervision. Across multiple video diffusion models (e.g., Wan2.1, CogVideoX), TeDiO delivers markedly smoother motion while preserving per-frame visual quality, offering an efficient plug-and-play approach to improving dynamic realism in modern video generation systems.
EgoMemReason: A Memory-Driven Reasoning Benchmark for Long-Horizon Egocentric Video Understanding
May 11, 2026Next-generation visual assistants, such as smart glasses, embodied agents, and always-on life-logging systems, must reason over an entire day or more of continuous visual experience. In ultra-long video settings, relevant information is sparsely distributed across hours or days, making memory a fundamental challenge: models must accumulate information over time, recall prior states, track temporal order, and abstract recurring patterns. However, existing week-long video benchmarks are primarily designed for perception and recognition, such as moment localization or global summarization, rather than reasoning that requires integrating evidence across multiple days. To address this gap, we introduce EgoMemReason, a comprehensive benchmark that systematically evaluates week-long egocentric video understanding through memory-driven reasoning. EgoMemReason evaluates three complementary memory types: entity memory, tracking how object states evolve and change across days; event memory, recalling and ordering activities separated by hours or days; and behavior memory, abstracting recurring patterns from sparse, repeated observations over the whole week period. EgoMemReason comprises 500 questions across three memory types and six core challenges, with an average of 5.1 video segments of evidence per question and 25.9 hours of memory backtracking. We evaluate EgoMemReason on 17 methods across MLLMs and agentic frameworks, revealing that even the best model achieves only 39.6% overall accuracy. Further analysis shows that the three memory types fail for distinct reasons and that performance degrades as evidence spans longer temporal horizons, revealing that long-horizon memory remains far from solved. We believe EgoMemReason establishes a strong foundation for evaluating and advancing long-context, memory-aware multimodal systems.
V2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation
Mar 11, 2026Generating music that temporally aligns with video events is challenging for existing text-to-music models, which lack fine-grained temporal control. We introduce V2M-Zero, a zero-pair video-to-music generation approach that outputs time-aligned music for video. Our method is motivated by a key observation: temporal synchronization requires matching when and how much change occurs, not what changes. While musical and visual events differ semantically, they exhibit shared temporal structure that can be captured independently within each modality. We capture this structure through event curves computed from intra-modal similarity using pretrained music and video encoders. By measuring temporal change within each modality independently, these curves provide comparable representations across modalities. This enables a simple training strategy: fine-tune a text-to-music model on music-event curves, then substitute video-event curves at inference without cross-modal training or paired data. Across OES-Pub, MovieGenBench-Music, and AIST++, V2M-Zero achieves substantial gains over paired-data baselines: 5-21% higher audio quality, 13-15% better semantic alignment, 21-52% improved temporal synchronization, and 28% higher beat alignment on dance videos. We find similar results via a large crowd-source subjective listening test. Overall, our results validate that temporal alignment through within-modality features, rather than paired cross-modal supervision, is effective for video-to-music generation. Results are available at https://genjib.github.io/v2m_zero/
LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
Feb 25, 2026General-purpose robots must master long-horizon manipulation, defined as tasks involving multiple kinematic structure changes (e.g., attaching or detaching objects) in unstructured environments. While Vision-Language-Action (VLA) models offer the potential to master diverse atomic skills, they struggle with the combinatorial complexity of sequencing them and are prone to cascading failures due to environmental sensitivity. To address these challenges, we propose LiLo-VLA (Linked Local VLA), a modular framework capable of zero-shot generalization to novel long-horizon tasks without ever being trained on them. Our approach decouples transport from interaction: a Reaching Module handles global motion, while an Interaction Module employs an object-centric VLA to process isolated objects of interest, ensuring robustness against irrelevant visual features and invariance to spatial configurations. Crucially, this modularity facilitates robust failure recovery through dynamic replanning and skill reuse, effectively mitigating the cascading errors common in end-to-end approaches. We introduce a 21-task simulation benchmark consisting of two challenging suites: LIBERO-Long++ and Ultra-Long. In these simulations, LiLo-VLA achieves a 69% average success rate, outperforming Pi0.5 by 41% and OpenVLA-OFT by 67%. Furthermore, real-world evaluations across 8 long-horizon tasks demonstrate an average success rate of 85%. Project page: https://yy-gx.github.io/LiLo-VLA/.
TimeBlind: A Spatio-Temporal Compositionality Benchmark for Video LLMs
Jan 30, 2026Fine-grained spatio-temporal understanding is essential for video reasoning and embodied AI. Yet, while Multimodal Large Language Models (MLLMs) master static semantics, their grasp of temporal dynamics remains brittle. We present TimeBlind, a diagnostic benchmark for compositional spatio-temporal understanding. Inspired by cognitive science, TimeBlind categorizes fine-grained temporal understanding into three levels: recognizing atomic events, characterizing event properties, and reasoning about event interdependencies. Unlike benchmarks that conflate recognition with temporal reasoning, TimeBlind leverages a minimal-pairs paradigm: video pairs share identical static visual content but differ solely in temporal structure, utilizing complementary questions to neutralize language priors. Evaluating over 20 state-of-the-art MLLMs (e.g., GPT-5, Gemini 3 Pro) on 600 curated instances (2400 video-question pairs), reveals that the Instance Accuracy (correctly distinguishing both videos in a pair) of the best performing MLLM is only 48.2%, far below the human performance (98.2%). These results demonstrate that even frontier models rely heavily on static visual shortcuts rather than genuine temporal logic, positioning TimeBlind as a vital diagnostic tool for next-generation video understanding. Dataset and code are available at https://baiqi-li.github.io/timeblind_project/ .
DocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025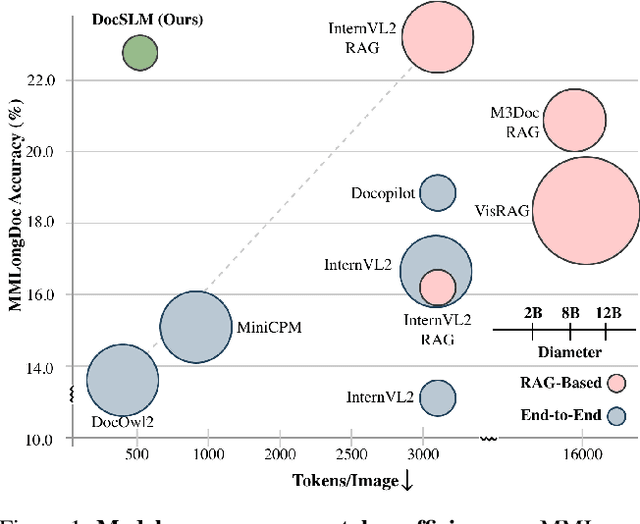

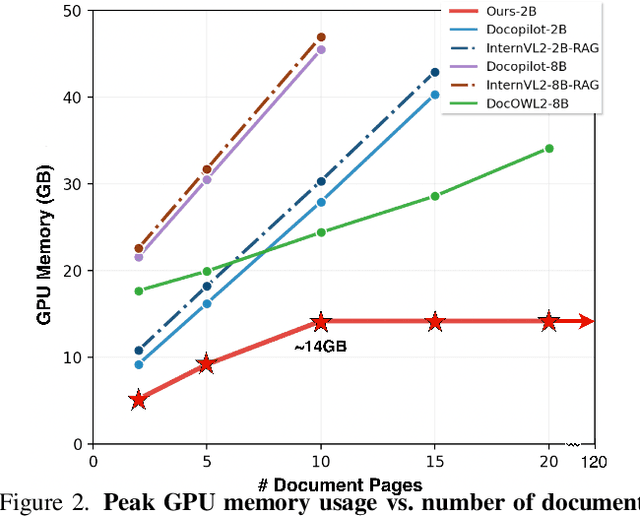
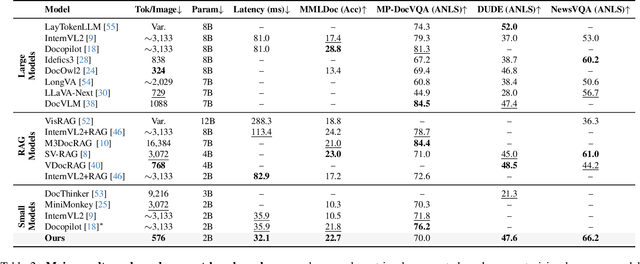
Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
Video-RTS: Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video Reasoning
Jul 09, 2025Despite advances in reinforcement learning (RL)-based video reasoning with large language models (LLMs), data collection and finetuning remain significant challenges. These methods often rely on large-scale supervised fine-tuning (SFT) with extensive video data and long Chain-of-Thought (CoT) annotations, making them costly and hard to scale. To address this, we present Video-RTS, a new approach to improve video reasoning capability with drastically improved data efficiency by combining data-efficient RL with a video-adaptive test-time scaling (TTS) strategy. Based on observations about the data scaling of RL samples, we skip the resource-intensive SFT step and employ efficient pure-RL training with output-based rewards, requiring no additional annotations or extensive fine-tuning. Furthermore, to utilize computational resources more efficiently, we introduce a sparse-to-dense video TTS strategy that improves inference by iteratively adding frames based on output consistency. We validate our approach on multiple video reasoning benchmarks, showing that Video-RTS surpasses existing video reasoning models by an average of 2.4% in accuracy using only 3.6% training samples. For example, Video-RTS achieves a 4.2% improvement on Video-Holmes, a recent and challenging video reasoning benchmark, and a 2.6% improvement on MMVU. Notably, our pure RL training and adaptive video TTS offer complementary strengths, enabling Video-RTS's strong reasoning performance.
ExAct: A Video-Language Benchmark for Expert Action Analysis
Jun 06, 2025We present ExAct, a new video-language benchmark for expert-level understanding of skilled physical human activities. Our new benchmark contains 3521 expert-curated video question-answer pairs spanning 11 physical activities in 6 domains: Sports, Bike Repair, Cooking, Health, Music, and Dance. ExAct requires the correct answer to be selected from five carefully designed candidate options, thus necessitating a nuanced, fine-grained, expert-level understanding of physical human skills. Evaluating the recent state-of-the-art VLMs on ExAct reveals a substantial performance gap relative to human expert performance. Specifically, the best-performing GPT-4o model achieves only 44.70% accuracy, well below the 82.02% attained by trained human specialists/experts. We believe that ExAct will be beneficial for developing and evaluating VLMs capable of precise understanding of human skills in various physical and procedural domains. Dataset and code are available at https://texaser.github.io/exact_project_page/