 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
LoCoNet: Long-Short Context Network for Active Speaker Detection
Jan 19, 2023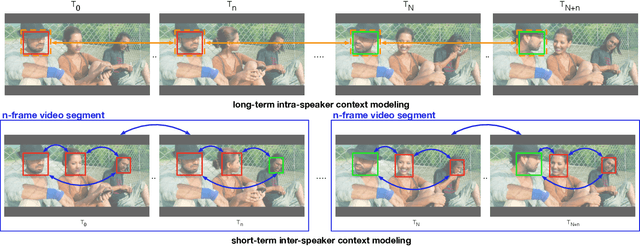
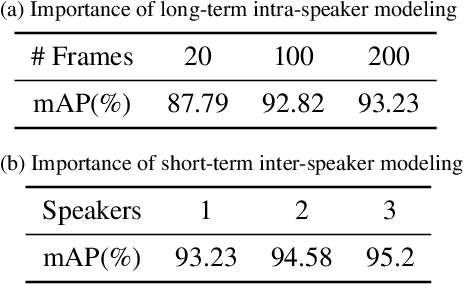
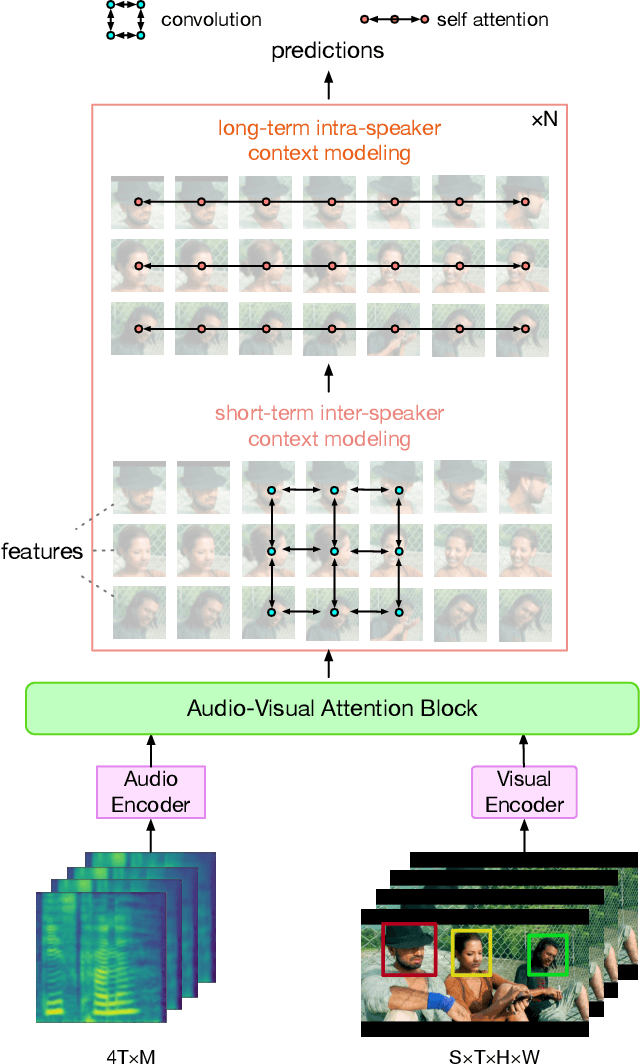

Active Speaker Detection (ASD) aims to identify who is speaking in each frame of a video. ASD reasons from audio and visual information from two contexts: long-term intra-speaker context and short-term inter-speaker context. Long-term intra-speaker context models the temporal dependencies of the same speaker, while short-term inter-speaker context models the interactions of speakers in the same scene. These two contexts are complementary to each other and can help infer the active speaker. Motivated by these observations, we propose LoCoNet, a simple yet effective Long-Short Context Network that models the long-term intra-speaker context and short-term inter-speaker context. We use self-attention to model long-term intra-speaker context due to its effectiveness in modeling long-range dependencies, and convolutional blocks that capture local patterns to model short-term inter-speaker context. Extensive experiments show that LoCoNet achieves state-of-the-art performance on multiple datasets, achieving an mAP of 95.2%(+1.1%) on AVA-ActiveSpeaker, 68.1%(+22%) on Columbia dataset, 97.2%(+2.8%) on Talkies dataset and 59.7%(+8.0%) on Ego4D dataset. Moreover, in challenging cases where multiple speakers are present, or face of active speaker is much smaller than other faces in the same scene, LoCoNet outperforms previous state-of-the-art methods by 3.4% on the AVA-ActiveSpeaker dataset. The code will be released at https://github.com/SJTUwxz/LoCoNet_ASD.
VindLU: A Recipe for Effective Video-and-Language Pretraining
Dec 09, 2022



The last several years have witnessed remarkable progress in video-and-language (VidL) understanding. However, most modern VidL approaches use complex and specialized model architectures and sophisticated pretraining protocols, making the reproducibility, analysis and comparisons of these frameworks difficult. Hence, instead of proposing yet another new VidL model, this paper conducts a thorough empirical study demystifying the most important factors in the VidL model design. Among the factors that we investigate are (i) the spatiotemporal architecture design, (ii) the multimodal fusion schemes, (iii) the pretraining objectives, (iv) the choice of pretraining data, (v) pretraining and finetuning protocols, and (vi) dataset and model scaling. Our empirical study reveals that the most important design factors include: temporal modeling, video-to-text multimodal fusion, masked modeling objectives, and joint training on images and videos. Using these empirical insights, we then develop a step-by-step recipe, dubbed VindLU, for effective VidL pretraining. Our final model trained using our recipe achieves comparable or better than state-of-the-art results on several VidL tasks without relying on external CLIP pretraining. In particular, on the text-to-video retrieval task, our approach obtains 61.2% on DiDeMo, and 55.0% on ActivityNet, outperforming current SOTA by 7.8% and 6.1% respectively. Furthermore, our model also obtains state-of-the-art video question-answering results on ActivityNet-QA, MSRVTT-QA, MSRVTT-MC and TVQA. Our code and pretrained models are publicly available at: https://github.com/klauscc/VindLU.
Action Recognition based on Cross-Situational Action-object Statistics
Aug 15, 2022

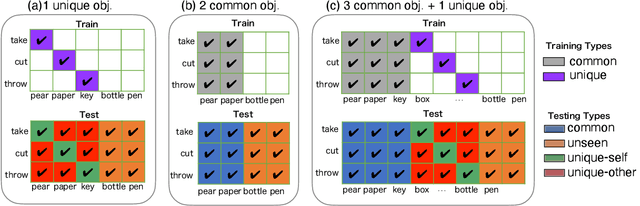
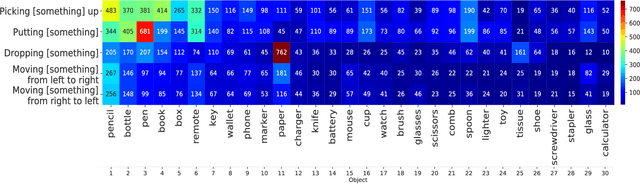
Machine learning models of visual action recognition are typically trained and tested on data from specific situations where actions are associated with certain objects. It is an open question how action-object associations in the training set influence a model's ability to generalize beyond trained situations. We set out to identify properties of training data that lead to action recognition models with greater generalization ability. To do this, we take inspiration from a cognitive mechanism called cross-situational learning, which states that human learners extract the meaning of concepts by observing instances of the same concept across different situations. We perform controlled experiments with various types of action-object associations, and identify key properties of action-object co-occurrence in training data that lead to better classifiers. Given that these properties are missing in the datasets that are typically used to train action classifiers in the computer vision literature, our work provides useful insights on how we should best construct datasets for efficiently training for better generalization.
Applying the Case Difference Heuristic to Learn Adaptations from Deep Network Features
Jul 15, 2021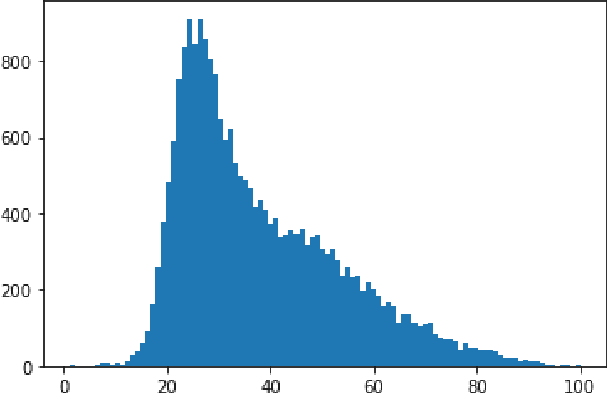
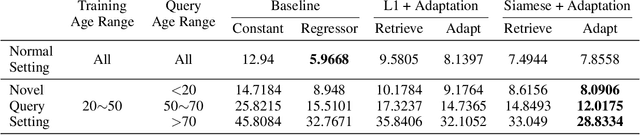
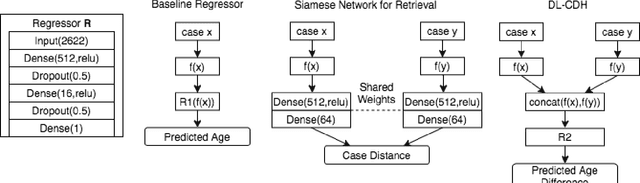
The case difference heuristic (CDH) approach is a knowledge-light method for learning case adaptation knowledge from the case base of a case-based reasoning system. Given a pair of cases, the CDH approach attributes the difference in their solutions to the difference in the problems they solve, and generates adaptation rules to adjust solutions accordingly when a retrieved case and new query have similar problem differences. As an alternative to learning adaptation rules, several researchers have applied neural networks to learn to predict solution differences from problem differences. Previous work on such approaches has assumed that the feature set describing problems is predefined. This paper investigates a two-phase process combining deep learning for feature extraction and neural network based adaptation learning from extracted features. Its performance is demonstrated in a regression task on an image data: predicting age given the image of a face. Results show that the combined process can successfully learn adaptation knowledge applicable to nonsymbolic differences in cases. The CBR system achieves slightly lower performance overall than a baseline deep network regressor, but better performance than the baseline on novel queries.
When, Where, and What? A New Dataset for Anomaly Detection in Driving Videos
Apr 06, 2020

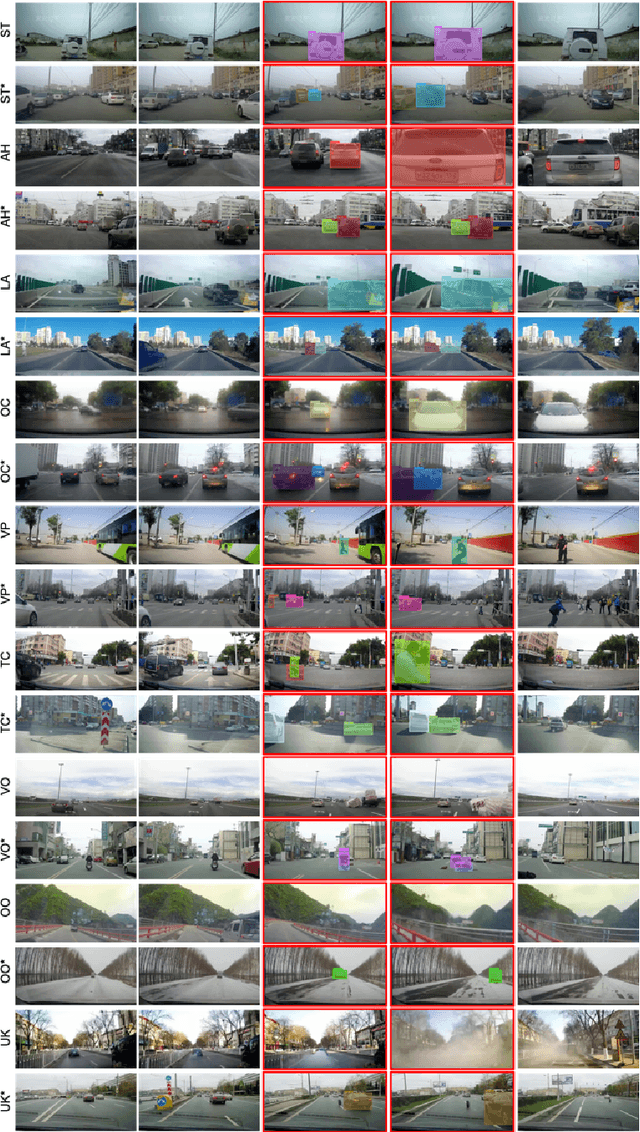
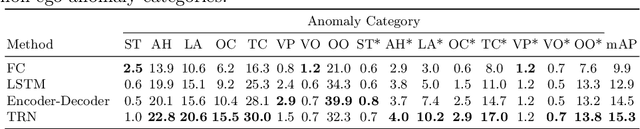
Video anomaly detection (VAD) has been extensively studied. However, research on egocentric traffic videos with dynamic scenes lacks large-scale benchmark datasets as well as effective evaluation metrics. This paper proposes traffic anomaly detection with a \textit{when-where-what} pipeline to detect, localize, and recognize anomalous events from egocentric videos. We introduce a new dataset called Detection of Traffic Anomaly (DoTA) containing 4,677 videos with temporal, spatial, and categorical annotations. A new spatial-temporal area under curve (STAUC) evaluation metric is proposed and used with DoTA. State-of-the-art methods are benchmarked for two VAD-related tasks.Experimental results show STAUC is an effective VAD metric. To our knowledge, DoTA is the largest traffic anomaly dataset to-date and is the first supporting traffic anomaly studies across when-where-what perspectives. Our code and dataset can be found in: https://github.com/MoonBlvd/Detection-of-Traffic-Anomaly