 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathDoc: Benchmarking Structured Extraction and Active Refusal on Noisy Mathematics Exam Papers
Jan 15, 2026The automated extraction of structured questions from paper-based mathematics exams is fundamental to intelligent education, yet remains challenging in real-world settings due to severe visual noise. Existing benchmarks mainly focus on clean documents or generic layout analysis, overlooking both the structural integrity of mathematical problems and the ability of models to actively reject incomplete inputs. We introduce MathDoc, the first benchmark for document-level information extraction from authentic high school mathematics exam papers. MathDoc contains \textbf{3,609} carefully curated questions with real-world artifacts and explicitly includes unrecognizable samples to evaluate active refusal behavior. We propose a multi-dimensional evaluation framework covering stem accuracy, visual similarity, and refusal capability. Experiments on SOTA MLLMs, including Qwen3-VL and Gemini-2.5-Pro, show that although end-to-end models achieve strong extraction performance, they consistently fail to refuse illegible inputs, instead producing confident but invalid outputs. These results highlight a critical gap in current MLLMs and establish MathDoc as a benchmark for assessing model reliability under degraded document conditions. Our project repository is available at \href{https://github.com/winnk123/papers/tree/master}{GitHub repository}
Geometric Prior-Guided Federated Prompt Calibration
Dec 08, 2025Federated Prompt Learning (FPL) offers a parameter-efficient solution for collaboratively training large models, but its performance is severely hindered by data heterogeneity, which causes locally trained prompts to become biased. Existing methods, focusing on aggregation or regularization, fail to address this root cause of local training bias. To this end, we propose Geometry-Guided Text Prompt Calibration (GGTPC), a novel framework that directly corrects this bias by providing clients with a global geometric prior. This prior, representing the shape of the global data distribution derived from the covariance matrix, is reconstructed on the server in a privacy-preserving manner. Clients then use a novel Geometry-Prior Calibration Layer (GPCL) to align their local feature distributions with this global prior during training. Extensive experiments show GGTPC's effectiveness. On the label-skewed CIFAR-100 dataset ($β$=0.1), it outperforms the state-of-the-art by 2.15\%. Under extreme skew ($β$=0.01), it improves upon the baseline by 9.17\%. Furthermore, as a plug-and-play module on the domain-skewed Office-Home dataset, it boosts FedAvg's performance by 4.60\%. These results demonstrate that GGTPC effectively mitigates data heterogeneity by correcting the fundamental local training bias, serving as a versatile module to enhance various FL algorithms.
DeformCL: Learning Deformable Centerline Representation for Vessel Extraction in 3D Medical Image
Jun 06, 2025In the field of 3D medical imaging, accurately extracting and representing the blood vessels with curvilinear structures holds paramount importance for clinical diagnosis. Previous methods have commonly relied on discrete representation like mask, often resulting in local fractures or scattered fragments due to the inherent limitations of the per-pixel classification paradigm. In this work, we introduce DeformCL, a new continuous representation based on Deformable Centerlines, where centerline points act as nodes connected by edges that capture spatial relationships. Compared with previous representations, DeformCL offers three key advantages: natural connectivity, noise robustness, and interaction facility. We present a comprehensive training pipeline structured in a cascaded manner to fully exploit these favorable properties of DeformCL. Extensive experiments on four 3D vessel segmentation datasets demonstrate the effectiveness and superiority of our method. Furthermore, the visualization of curved planar reformation images validates the clinical significance of the proposed framework. We release the code in https://github.com/barry664/DeformCL
LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
Mar 05, 2025
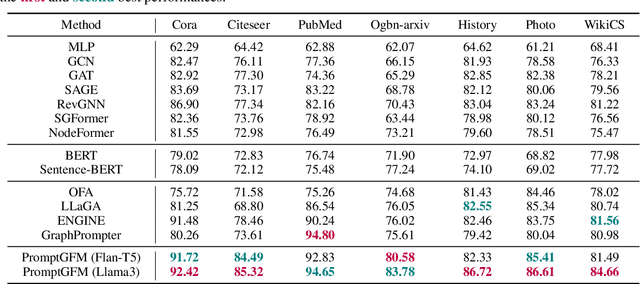
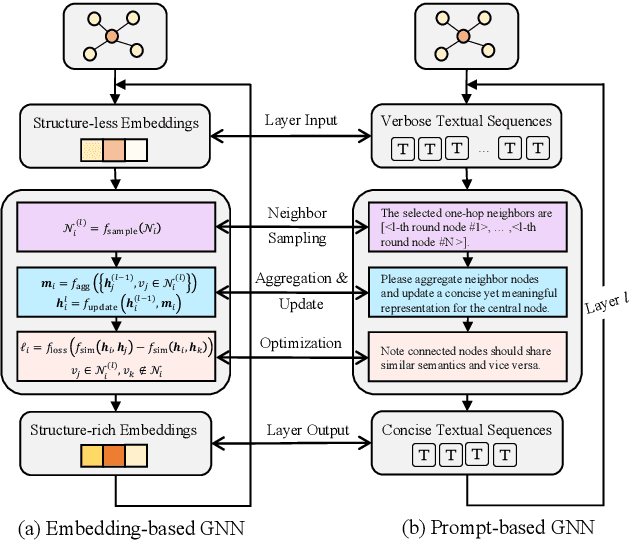
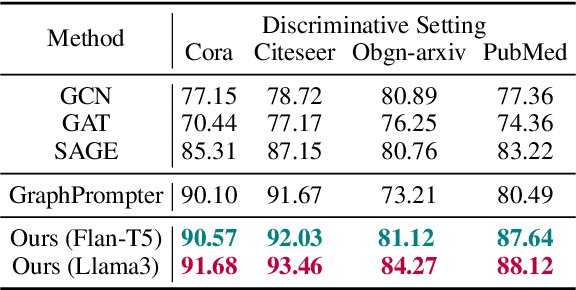
Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: https://github.com/agiresearch/PromptGFM.
GraphMorph: Tubular Structure Extraction by Morphing Predicted Graphs
Feb 17, 2025



Accurately restoring topology is both challenging and crucial in tubular structure extraction tasks, such as blood vessel segmentation and road network extraction. Diverging from traditional approaches based on pixel-level classification, our proposed method, named GraphMorph, focuses on branch-level features of tubular structures to achieve more topologically accurate predictions. GraphMorph comprises two main components: a Graph Decoder and a Morph Module. Utilizing multi-scale features extracted from an image patch by the segmentation network, the Graph Decoder facilitates the learning of branch-level features and generates a graph that accurately represents the tubular structure in this patch. The Morph Module processes two primary inputs: the graph and the centerline probability map, provided by the Graph Decoder and the segmentation network, respectively. Employing a novel SkeletonDijkstra algorithm, the Morph Module produces a centerline mask that aligns with the predicted graph. Furthermore, we observe that employing centerline masks predicted by GraphMorph significantly reduces false positives in the segmentation task, which is achieved by a simple yet effective post-processing strategy. The efficacy of our method in the centerline extraction and segmentation tasks has been substantiated through experimental evaluations across various datasets. Source code will be released soon.
LarvSeg: Exploring Image Classification Data For Large Vocabulary Semantic Segmentation via Category-wise Attentive Classifier
Jan 12, 2025



Scaling up the vocabulary of semantic segmentation models is extremely challenging because annotating large-scale mask labels is labour-intensive and time-consuming. Recently, language-guided segmentation models have been proposed to address this challenge. However, their performance drops significantly when applied to out-of-distribution categories. In this paper, we propose a new large vocabulary semantic segmentation framework, called LarvSeg. Different from previous works, LarvSeg leverages image classification data to scale the vocabulary of semantic segmentation models as large-vocabulary classification datasets usually contain balanced categories and are much easier to obtain. However, for classification tasks, the category is image-level, while for segmentation we need to predict the label at pixel level. To address this issue, we first propose a general baseline framework to incorporate image-level supervision into the training process of a pixel-level segmentation model, making the trained network perform semantic segmentation on newly introduced categories in the classification data. We then observe that a model trained on segmentation data can group pixel features of categories beyond the training vocabulary. Inspired by this finding, we design a category-wise attentive classifier to apply supervision to the precise regions of corresponding categories to improve the model performance. Extensive experiments demonstrate that LarvSeg significantly improves the large vocabulary semantic segmentation performance, especially in the categories without mask labels. For the first time, we provide a 21K-category semantic segmentation model with the help of ImageNet21K. The code is available at https://github.com/HaojunYu1998/large_voc_seg.
A Foundational Generative Model for Breast Ultrasound Image Analysis
Jan 12, 2025



Foundational models have emerged as powerful tools for addressing various tasks in clinical settings. However, their potential development to breast ultrasound analysis remains untapped. In this paper, we present BUSGen, the first foundational generative model specifically designed for breast ultrasound image analysis. Pretrained on over 3.5 million breast ultrasound images, BUSGen has acquired extensive knowledge of breast structures, pathological features, and clinical variations. With few-shot adaptation, BUSGen can generate repositories of realistic and informative task-specific data, facilitating the development of models for a wide range of downstream tasks. Extensive experiments highlight BUSGen's exceptional adaptability, significantly exceeding real-data-trained foundational models in breast cancer screening, diagnosis, and prognosis. In breast cancer early diagnosis, our approach outperformed all board-certified radiologists (n=9), achieving an average sensitivity improvement of 16.5% (P-value<0.0001). Additionally, we characterized the scaling effect of using generated data which was as effective as the collected real-world data for training diagnostic models. Moreover, extensive experiments demonstrated that our approach improved the generalization ability of downstream models. Importantly, BUSGen protected patient privacy by enabling fully de-identified data sharing, making progress forward in secure medical data utilization. An online demo of BUSGen is available at https://aibus.bio.
Case-Enhanced Vision Transformer: Improving Explanations of Image Similarity with a ViT-based Similarity Metric
Jul 24, 2024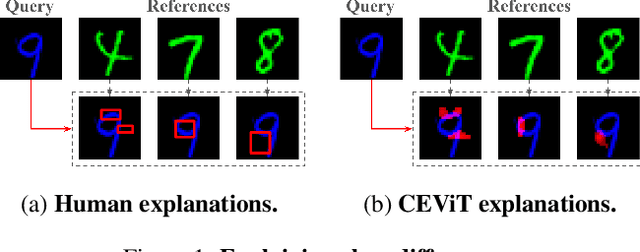



This short paper presents preliminary research on the Case-Enhanced Vision Transformer (CEViT), a similarity measurement method aimed at improving the explainability of similarity assessments for image data. Initial experimental results suggest that integrating CEViT into k-Nearest Neighbor (k-NN) classification yields classification accuracy comparable to state-of-the-art computer vision models, while adding capabilities for illustrating differences between classes. CEViT explanations can be influenced by prior cases, to illustrate aspects of similarity relevant to those cases.
Knowledge-driven AI-generated data for accurate and interpretable breast ultrasound diagnoses
Jul 23, 2024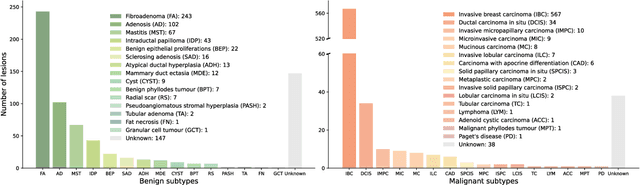
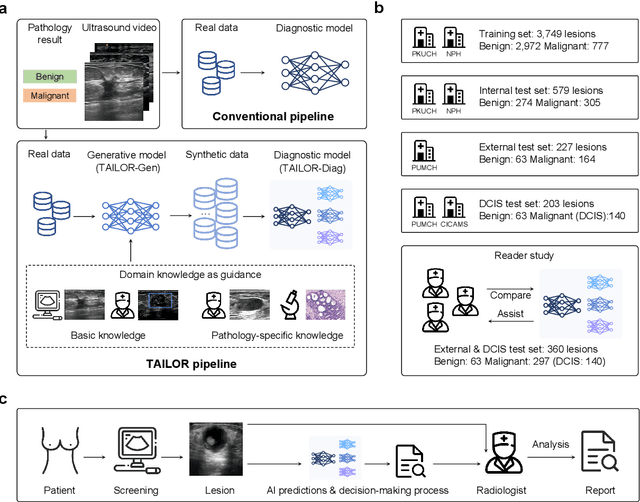
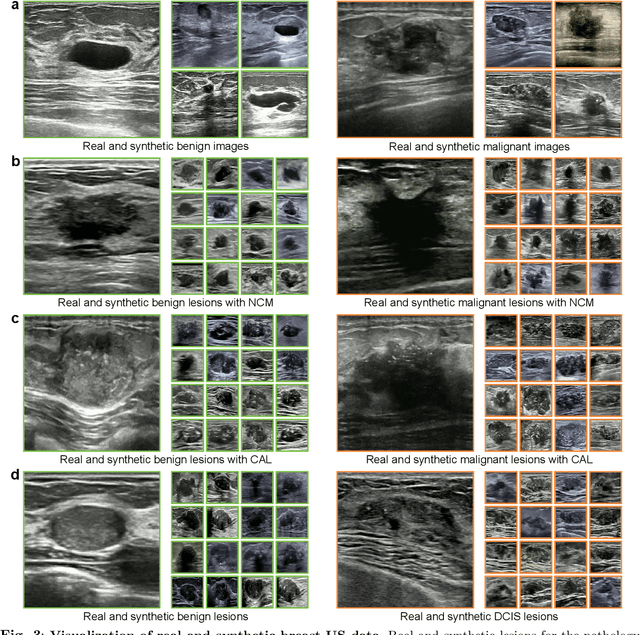
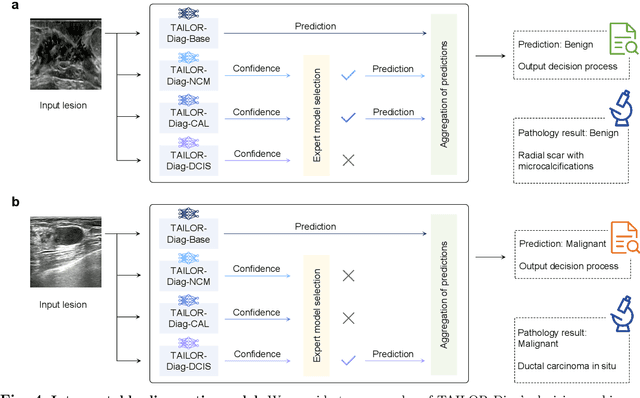
Data-driven deep learning models have shown great capabilities to assist radiologists in breast ultrasound (US) diagnoses. However, their effectiveness is limited by the long-tail distribution of training data, which leads to inaccuracies in rare cases. In this study, we address a long-standing challenge of improving the diagnostic model performance on rare cases using long-tailed data. Specifically, we introduce a pipeline, TAILOR, that builds a knowledge-driven generative model to produce tailored synthetic data. The generative model, using 3,749 lesions as source data, can generate millions of breast-US images, especially for error-prone rare cases. The generated data can be further used to build a diagnostic model for accurate and interpretable diagnoses. In the prospective external evaluation, our diagnostic model outperforms the average performance of nine radiologists by 33.5% in specificity with the same sensitivity, improving their performance by providing predictions with an interpretable decision-making process. Moreover, on ductal carcinoma in situ (DCIS), our diagnostic model outperforms all radiologists by a large margin, with only 34 DCIS lesions in the source data. We believe that TAILOR can potentially be extended to various diseases and imaging modalities.
When Box Meets Graph Neural Network in Tag-aware Recommendation
Jun 17, 2024



Last year has witnessed the re-flourishment of tag-aware recommender systems supported by the LLM-enriched tags. Unfortunately, though large efforts have been made, current solutions may fail to describe the diversity and uncertainty inherent in user preferences with only tag-driven profiles. Recently, with the development of geometry-based techniques, e.g., box embedding, diversity of user preferences now could be fully modeled as the range within a box in high dimension space. However, defect still exists as these approaches are incapable of capturing high-order neighbor signals, i.e., semantic-rich multi-hop relations within the user-tag-item tripartite graph, which severely limits the effectiveness of user modeling. To deal with this challenge, in this paper, we propose a novel algorithm, called BoxGNN, to perform the message aggregation via combination of logical operations, thereby incorporating high-order signals. Specifically, we first embed users, items, and tags as hyper-boxes rather than simple points in the representation space, and define two logical operations to facilitate the subsequent process. Next, we perform the message aggregation mechanism via the combination of logical operations, to obtain the corresponding high-order box representations. Finally, we adopt a volume-based learning objective with Gumbel smoothing techniques to refine the representation of boxes. Extensive experiments on two publicly available datasets and one LLM-enhanced e-commerce dataset have validated the superiority of BoxGNN compared with various state-of-the-art baselines. The code is released online