 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Apr 06, 2026With the rapid advancement of video understanding, existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model capabilities. To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding. To systematically evaluate model capabilities, we design a \textbf{progressive tri-level hierarchy} that incrementally increases the complexity of video comprehension, ranging from multi-point visual information aggregation, to temporal dynamics modeling, and ultimately to complex multimodal reasoning. Besides, in contrast to conventional per-question accuracy, we propose a \textbf{group-based non-linear evaluation} strategy that enforces both consistency across related queries and coherence in multi-step reasoning. It penalizes fragmented or guess-based correctness and assigns credit only to answers supported by valid reasoning. To guarantee data quality, Video-MME-v2 is constructed through a rigorously controlled human annotation pipeline, involving 12 annotators and 50 independent reviewers. Backed by \textbf{3,300 human-hours} and up to \textbf{5 rounds} of quality assurance, Video-MME-v2 aims to serve as one of the most authoritative video benchmarks. Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and temporal modeling propagate to limit high-level reasoning. We further find that thinking-based reasoning is highly dependent on textual cues, improving performance with subtitles but sometimes degrading it in purely visual settings. By exposing these limitations, Video-MME-v2 establishes a demanding new testbed for the development of next-generation video MLLMs.
Stop Wandering: Efficient Vision-Language Navigation via Metacognitive Reasoning
Apr 02, 2026Training-free Vision-Language Navigation (VLN) agents powered by foundation models can follow instructions and explore 3D environments. However, existing approaches rely on greedy frontier selection and passive spatial memory, leading to inefficient behaviors such as local oscillation and redundant revisiting. We argue that this stems from a lack of metacognitive capabilities: the agent cannot monitor its exploration progress, diagnose strategy failures, or adapt accordingly. To address this, we propose MetaNav, a metacognitive navigation agent integrating spatial memory, history-aware planning, and reflective correction. Spatial memory builds a persistent 3D semantic map. History-aware planning penalizes revisiting to improve efficiency. Reflective correction detects stagnation and uses an LLM to generate corrective rules that guide future frontier selection. Experiments on GOAT-Bench, HM3D-OVON, and A-EQA show that MetaNav achieves state-of-the-art performance while reducing VLM queries by 20.7%, demonstrating that metacognitive reasoning significantly improves robustness and efficiency.
PhoStream: Benchmarking Real-World Streaming for Omnimodal Assistants in Mobile Scenarios
Jan 30, 2026Multimodal Large Language Models excel at offline audio-visual understanding, but their ability to serve as mobile assistants in continuous real-world streams remains underexplored. In daily phone use, mobile assistants must track streaming audio-visual inputs and respond at the right time, yet existing benchmarks are often restricted to multiple-choice questions or use shorter videos. In this paper, we introduce PhoStream, the first mobile-centric streaming benchmark that unifies on-screen and off-screen scenarios to evaluate video, audio, and temporal reasoning. PhoStream contains 5,572 open-ended QA pairs from 578 videos across 4 scenarios and 10 capabilities. We build it with an Automated Generative Pipeline backed by rigorous human verification, and evaluate models using a realistic Online Inference Pipeline and LLM-as-a-Judge evaluation for open-ended responses. Experiments reveal a temporal asymmetry in LLM-judged scores (0-100): models perform well on Instant and Backward tasks (Gemini 3 Pro exceeds 80), but drop sharply on Forward tasks (16.40), largely due to early responses before the required visual and audio cues appear. This highlights a fundamental limitation: current MLLMs struggle to decide when to speak, not just what to say. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/PhoStream.
Visionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
Dec 09, 2025Neural rendering, particularly 3D Gaussian Splatting (3DGS), has evolved rapidly and become a key component for building world models. However, existing viewer solutions remain fragmented, heavy, or constrained by legacy pipelines, resulting in high deployment friction and limited support for dynamic content and generative models. In this work, we present Visionary, an open, web-native platform for real-time various Gaussian Splatting and meshes rendering. Built on an efficient WebGPU renderer with per-frame ONNX inference, Visionary enables dynamic neural processing while maintaining a lightweight, "click-to-run" browser experience. It introduces a standardized Gaussian Generator contract, which not only supports standard 3DGS rendering but also allows plug-and-play algorithms to generate or update Gaussians each frame. Such inference also enables us to apply feedforward generative post-processing. The platform further offers a plug in three.js library with a concise TypeScript API for seamless integration into existing web applications. Experiments show that, under identical 3DGS assets, Visionary achieves superior rendering efficiency compared to current Web viewers due to GPU-based primitive sorting. It already supports multiple variants, including MLP-based 3DGS, 4DGS, neural avatars, and style transformation or enhancement networks. By unifying inference and rendering directly in the browser, Visionary significantly lowers the barrier to reproduction, comparison, and deployment of 3DGS-family methods, serving as a unified World Model Carrier for both reconstructive and generative paradigms.
When Box Meets Graph Neural Network in Tag-aware Recommendation
Jun 17, 2024



Last year has witnessed the re-flourishment of tag-aware recommender systems supported by the LLM-enriched tags. Unfortunately, though large efforts have been made, current solutions may fail to describe the diversity and uncertainty inherent in user preferences with only tag-driven profiles. Recently, with the development of geometry-based techniques, e.g., box embedding, diversity of user preferences now could be fully modeled as the range within a box in high dimension space. However, defect still exists as these approaches are incapable of capturing high-order neighbor signals, i.e., semantic-rich multi-hop relations within the user-tag-item tripartite graph, which severely limits the effectiveness of user modeling. To deal with this challenge, in this paper, we propose a novel algorithm, called BoxGNN, to perform the message aggregation via combination of logical operations, thereby incorporating high-order signals. Specifically, we first embed users, items, and tags as hyper-boxes rather than simple points in the representation space, and define two logical operations to facilitate the subsequent process. Next, we perform the message aggregation mechanism via the combination of logical operations, to obtain the corresponding high-order box representations. Finally, we adopt a volume-based learning objective with Gumbel smoothing techniques to refine the representation of boxes. Extensive experiments on two publicly available datasets and one LLM-enhanced e-commerce dataset have validated the superiority of BoxGNN compared with various state-of-the-art baselines. The code is released online
Knowledge Graph Pruning for Recommendation
May 19, 2024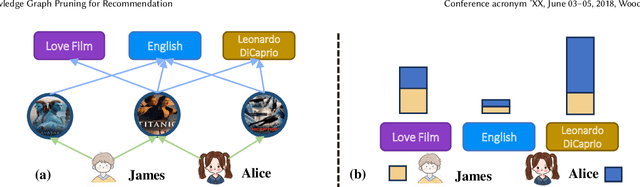
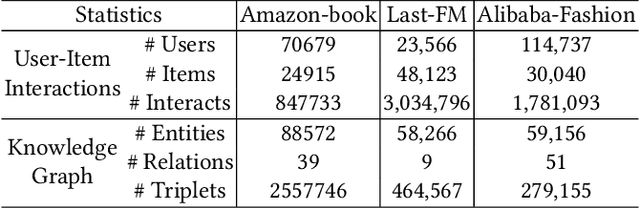
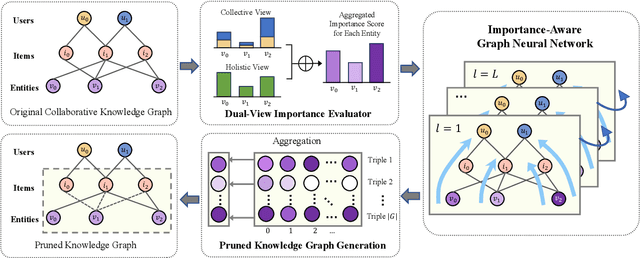
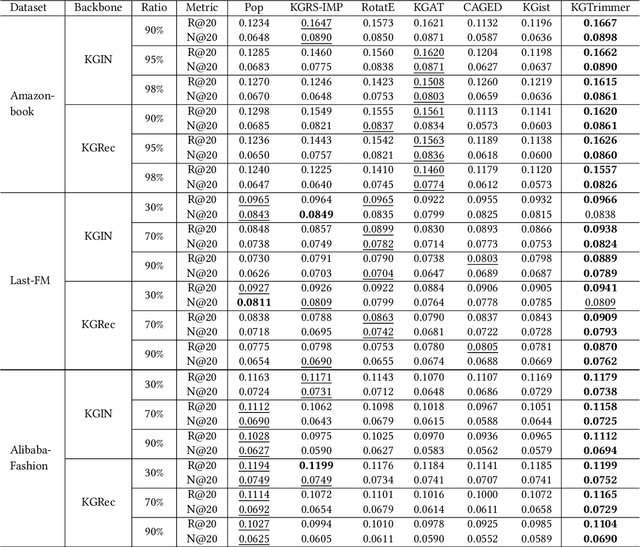
Recent years have witnessed the prosperity of knowledge graph based recommendation system (KGRS), which enriches the representation of users, items, and entities by structural knowledge with striking improvement. Nevertheless, its unaffordable computational cost still limits researchers from exploring more sophisticated models. We observe that the bottleneck for training efficiency arises from the knowledge graph, which is plagued by the well-known issue of knowledge explosion. Recently, some works have attempted to slim the inflated KG via summarization techniques. However, these summarized nodes may ignore the collaborative signals and deviate from the facts that nodes in knowledge graph represent symbolic abstractions of entities from the real-world. To this end, in this paper, we propose a novel approach called KGTrimmer for knowledge graph pruning tailored for recommendation, to remove the unessential nodes while minimizing performance degradation. Specifically, we design an importance evaluator from a dual-view perspective. For the collective view, we embrace the idea of collective intelligence by extracting community consensus based on abundant collaborative signals, i.e. nodes are considered important if they attract attention of numerous users. For the holistic view, we learn a global mask to identify the valueless nodes from their inherent properties or overall popularity. Next, we build an end-to-end importance-aware graph neural network, which injects filtered knowledge to enhance the distillation of valuable user-item collaborative signals. Ultimately, we generate a pruned knowledge graph with lightweight, stable, and robust properties to facilitate the following-up recommendation task. Extensive experiments are conducted on three publicly available datasets to prove the effectiveness and generalization ability of KGTrimmer.
DynLLM: When Large Language Models Meet Dynamic Graph Recommendation
May 13, 2024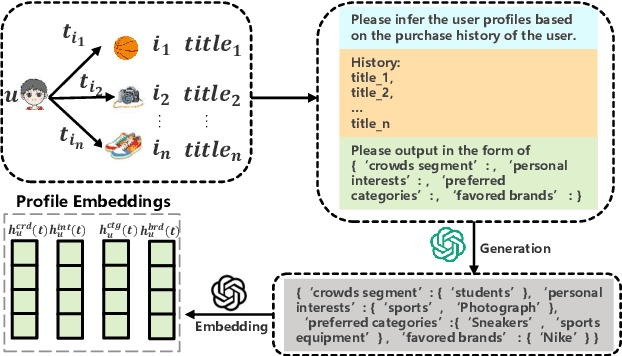

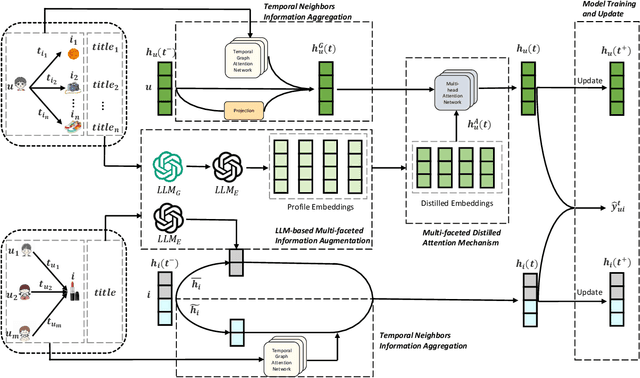
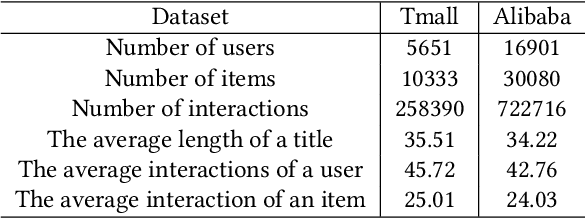
Last year has witnessed the considerable interest of Large Language Models (LLMs) for their potential applications in recommender systems, which may mitigate the persistent issue of data sparsity. Though large efforts have been made for user-item graph augmentation with better graph-based recommendation performance, they may fail to deal with the dynamic graph recommendation task, which involves both structural and temporal graph dynamics with inherent complexity in processing time-evolving data. To bridge this gap, in this paper, we propose a novel framework, called DynLLM, to deal with the dynamic graph recommendation task with LLMs. Specifically, DynLLM harnesses the power of LLMs to generate multi-faceted user profiles based on the rich textual features of historical purchase records, including crowd segments, personal interests, preferred categories, and favored brands, which in turn supplement and enrich the underlying relationships between users and items. Along this line, to fuse the multi-faceted profiles with temporal graph embedding, we engage LLMs to derive corresponding profile embeddings, and further employ a distilled attention mechanism to refine the LLM-generated profile embeddings for alleviating noisy signals, while also assessing and adjusting the relevance of each distilled facet embedding for seamless integration with temporal graph embedding from continuous time dynamic graphs (CTDGs). Extensive experiments on two real e-commerce datasets have validated the superior improvements of DynLLM over a wide range of state-of-the-art baseline methods.
Practical Parallel Algorithms for Non-Monotone Submodular Maximization
Aug 21, 2023
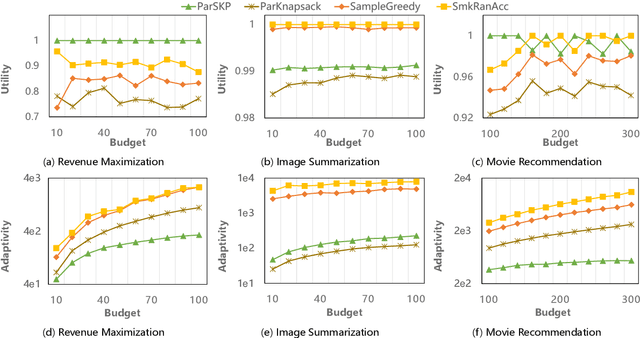
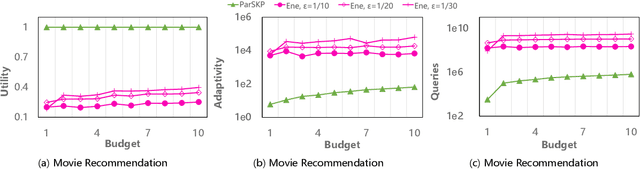
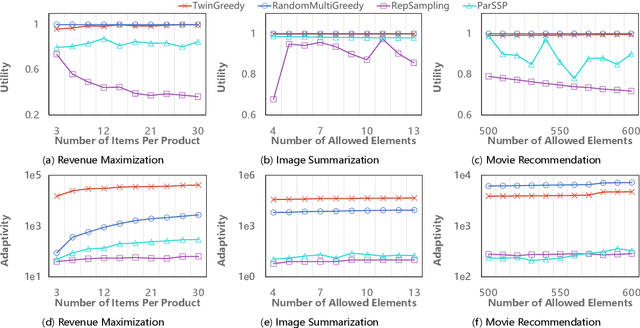
Submodular maximization has found extensive applications in various domains within the field of artificial intelligence, including but not limited to machine learning, computer vision, and natural language processing. With the increasing size of datasets in these domains, there is a pressing need to develop efficient and parallelizable algorithms for submodular maximization. One measure of the parallelizability of a submodular maximization algorithm is its adaptive complexity, which indicates the number of sequential rounds where a polynomial number of queries to the objective function can be executed in parallel. In this paper, we study the problem of non-monotone submodular maximization subject to a knapsack constraint, and propose the first combinatorial algorithm achieving an $(8+\epsilon)$-approximation under $\mathcal{O}(\log n)$ adaptive complexity, which is \textit{optimal} up to a factor of $\mathcal{O}(\log\log n)$. Moreover, we also propose the first algorithm with both provable approximation ratio and sublinear adaptive complexity for the problem of non-monotone submodular maximization subject to a $k$-system constraint. As a by-product, we show that our two algorithms can also be applied to the special case of submodular maximization subject to a cardinality constraint, and achieve performance bounds comparable with those of state-of-the-art algorithms. Finally, the effectiveness of our approach is demonstrated by extensive experiments on real-world applications.
A Smart Recycling Bin Using Waste Image Classification At The Edge
Oct 02, 2022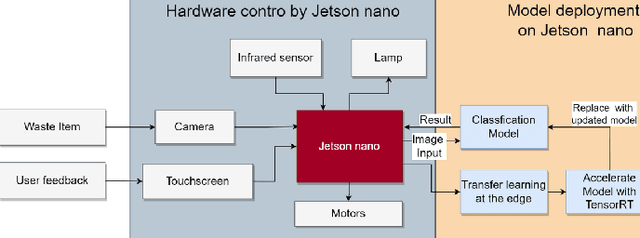
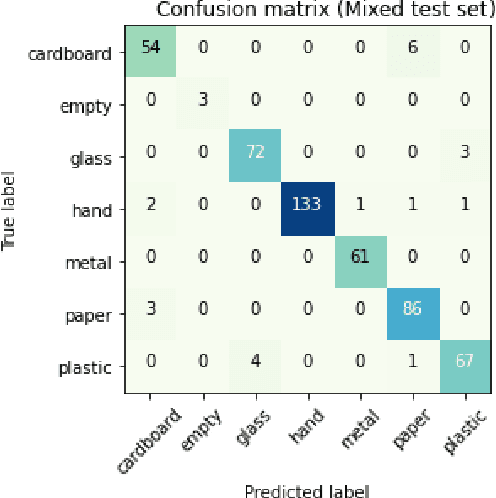
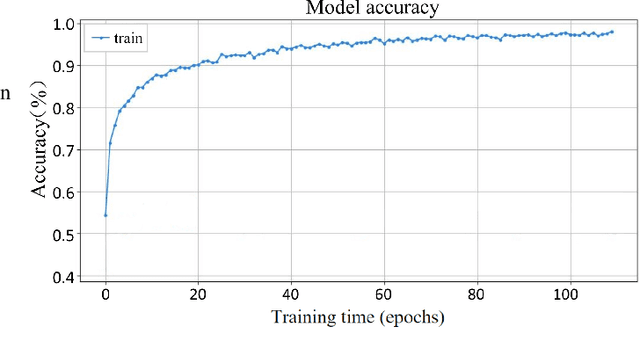
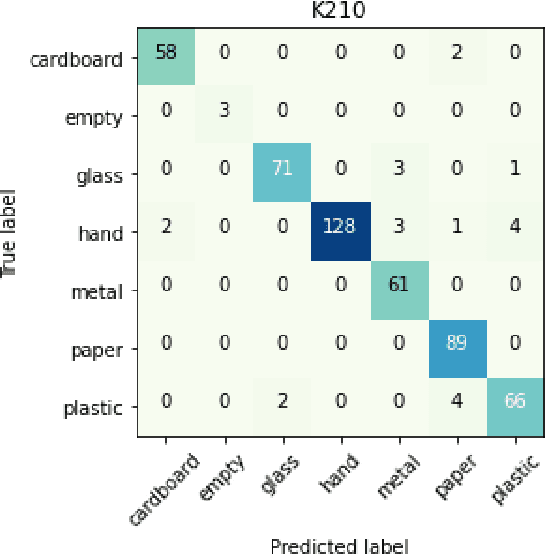
Rapid economic growth gives rise to the urgent demand for a more efficient waste recycling system. This work thereby developed an innovative recycling bin that automatically separates urban waste to increase the recycling rate. We collected 1800 recycling waste images and combined them with an existing public dataset to train classification models for two embedded systems, Jetson Nano and K210, targeting different markets. The model reached an accuracy of 95.98% on Jetson Nano and 96.64% on K210. A bin program was designed to collect feedback from users. On Jetson Nano, the overall power consumption of the application was reduced by 30% from the previous work to 4.7 W, while the second system, K210, only needed 0.89 W of power to operate. In summary, our work demonstrated a fully functional prototype of an energy-saving, high-accuracy smart recycling bin, which can be commercialized in the future to improve urban waste recycling.
Interpretable performance analysis towards offline reinforcement learning: A dataset perspective
May 12, 2021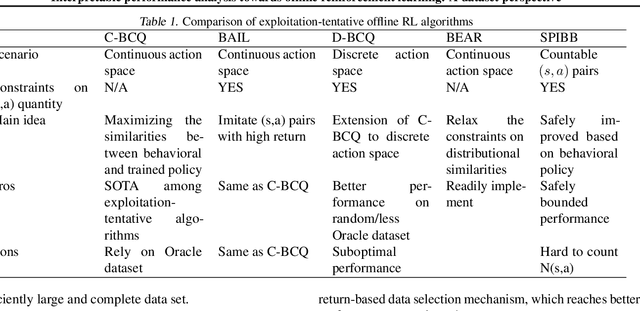
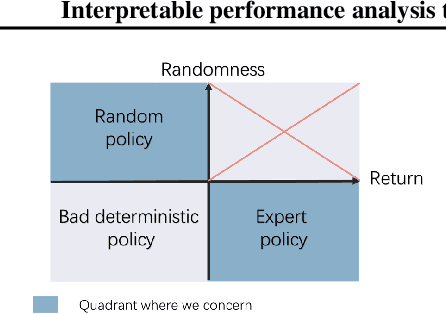

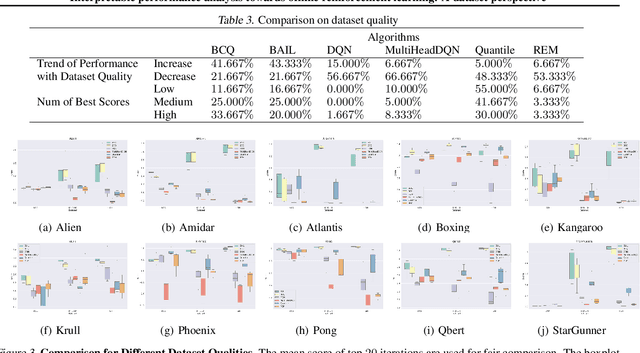
Offline reinforcement learning (RL) has increasingly become the focus of the artificial intelligent research due to its wide real-world applications where the collection of data may be difficult, time-consuming, or costly. In this paper, we first propose a two-fold taxonomy for existing offline RL algorithms from the perspective of exploration and exploitation tendency. Secondly, we derive the explicit expression of the upper bound of extrapolation error and explore the correlation between the performance of different types of algorithms and the distribution of actions under states. Specifically, we relax the strict assumption on the sufficiently large amount of state-action tuples. Accordingly, we provably explain why batch constrained Q-learning (BCQ) performs better than other existing techniques. Thirdly, after identifying the weakness of BCQ on dataset of low mean episode returns, we propose a modified variant based on top return selection mechanism, which is proved to be able to gain state-of-the-art performance on various datasets. Lastly, we create a benchmark platform on the Atari domain, entitled RL easy go (RLEG), at an estimated cost of more than 0.3 million dollars. We make it open-source for fair and comprehensive competitions between offline RL algorithms with complete datasets and checkpoints being provided.