 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Box Meets Graph Neural Network in Tag-aware Recommendation
Jun 17, 2024



Last year has witnessed the re-flourishment of tag-aware recommender systems supported by the LLM-enriched tags. Unfortunately, though large efforts have been made, current solutions may fail to describe the diversity and uncertainty inherent in user preferences with only tag-driven profiles. Recently, with the development of geometry-based techniques, e.g., box embedding, diversity of user preferences now could be fully modeled as the range within a box in high dimension space. However, defect still exists as these approaches are incapable of capturing high-order neighbor signals, i.e., semantic-rich multi-hop relations within the user-tag-item tripartite graph, which severely limits the effectiveness of user modeling. To deal with this challenge, in this paper, we propose a novel algorithm, called BoxGNN, to perform the message aggregation via combination of logical operations, thereby incorporating high-order signals. Specifically, we first embed users, items, and tags as hyper-boxes rather than simple points in the representation space, and define two logical operations to facilitate the subsequent process. Next, we perform the message aggregation mechanism via the combination of logical operations, to obtain the corresponding high-order box representations. Finally, we adopt a volume-based learning objective with Gumbel smoothing techniques to refine the representation of boxes. Extensive experiments on two publicly available datasets and one LLM-enhanced e-commerce dataset have validated the superiority of BoxGNN compared with various state-of-the-art baselines. The code is released online
Dataset Regeneration for Sequential Recommendation
May 28, 2024The sequential recommender (SR) system is a crucial component of modern recommender systems, as it aims to capture the evolving preferences of users. Significant efforts have been made to enhance the capabilities of SR systems. These methods typically follow the \textbf{model-centric} paradigm, which involves developing effective models based on fixed datasets. However, this approach often overlooks potential quality issues and flaws inherent in the data. Driven by the potential of \textbf{data-centric} AI, we propose a novel data-centric paradigm for developing an ideal training dataset using a model-agnostic dataset regeneration framework called DR4SR. This framework enables the regeneration of a dataset with exceptional cross-architecture generalizability. Additionally, we introduce the DR4SR+ framework, which incorporates a model-aware dataset personalizer to tailor the regenerated dataset specifically for a target model. To demonstrate the effectiveness of the data-centric paradigm, we integrate our framework with various model-centric methods and observe significant performance improvements across four widely adopted datasets. Furthermore, we conduct in-depth analyses to explore the potential of the data-centric paradigm and provide valuable insights. The code can be found at \textcolor{blue}{\url{https://anonymous.4open.science/r/KDD2024-86EA/}}
A Unified Framework for Adaptive Representation Enhancement and Inversed Learning in Cross-Domain Recommendation
Mar 30, 2024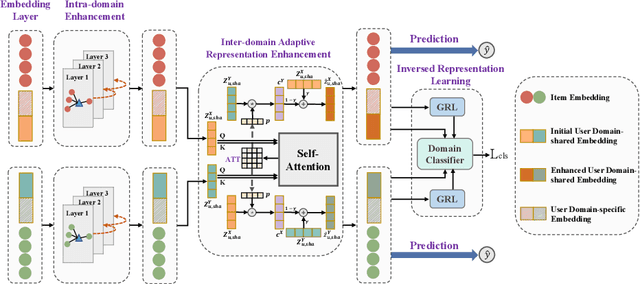
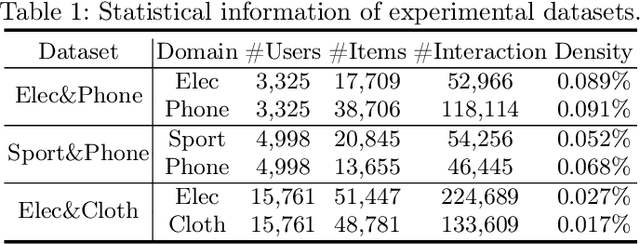
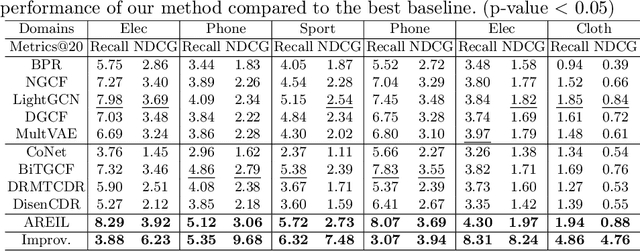
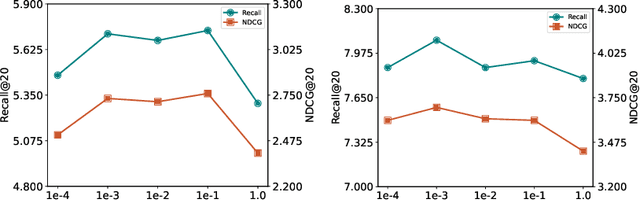
Cross-domain recommendation (CDR), aiming to extract and transfer knowledge across domains, has attracted wide attention for its efficacy in addressing data sparsity and cold-start problems. Despite significant advances in representation disentanglement to capture diverse user preferences, existing methods usually neglect representation enhancement and lack rigorous decoupling constraints, thereby limiting the transfer of relevant information. To this end, we propose a Unified Framework for Adaptive Representation Enhancement and Inversed Learning in Cross-Domain Recommendation (AREIL). Specifically, we first divide user embeddings into domain-shared and domain-specific components to disentangle mixed user preferences. Then, we incorporate intra-domain and inter-domain information to adaptively enhance the ability of user representations. In particular, we propose a graph convolution module to capture high-order information, and a self-attention module to reveal inter-domain correlations and accomplish adaptive fusion. Next, we adopt domain classifiers and gradient reversal layers to achieve inversed representation learning in a unified framework. Finally, we employ a cross-entropy loss for measuring recommendation performance and jointly optimize the entire framework via multi-task learning. Extensive experiments on multiple datasets validate the substantial improvement in the recommendation performance of AREIL. Moreover, ablation studies and representation visualizations further illustrate the effectiveness of adaptive enhancement and inversed learning in CDR.