 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMA: A Training-Free Plug-and-Play Mixing Augmentation for Video Behavior Recognition
Jan 01, 2026Video behavior recognition demands stable and discriminative representations under complex spatiotemporal variations. However, prevailing data augmentation strategies for videos remain largely perturbation-driven, often introducing uncontrolled variations that amplify non-discriminative factors, which finally weaken intra-class distributional structure and representation drift with inconsistent gains across temporal scales. To address these problems, we propose Representation-aware Mixing Augmentation (ReMA), a plug-and-play augmentation strategy that formulates mixing as a controlled replacement process to expand representations while preserving class-conditional stability. ReMA integrates two complementary mechanisms. Firstly, the Representation Alignment Mechanism (RAM) performs structured intra-class mixing under distributional alignment constraints, suppressing irrelevant intra-class drift while enhancing statistical reliability. Then, the Dynamic Selection Mechanism (DSM) generates motion-aware spatiotemporal masks to localize perturbations, guiding them away from discrimination-sensitive regions and promoting temporal coherence. By jointly controlling how and where mixing is applied, ReMA improves representation robustness without additional supervision or trainable parameters. Extensive experiments on diverse video behavior benchmarks demonstrate that ReMA consistently enhances generalization and robustness across different spatiotemporal granularities.
LIHE: Linguistic Instance-Split Hyperbolic-Euclidean Framework for Generalized Weakly-Supervised Referring Expression Comprehension
Nov 15, 2025



Existing Weakly-Supervised Referring Expression Comprehension (WREC) methods, while effective, are fundamentally limited by a one-to-one mapping assumption, hindering their ability to handle expressions corresponding to zero or multiple targets in realistic scenarios. To bridge this gap, we introduce the Weakly-Supervised Generalized Referring Expression Comprehension task (WGREC), a more practical paradigm that handles expressions with variable numbers of referents. However, extending WREC to WGREC presents two fundamental challenges: supervisory signal ambiguity, where weak image-level supervision is insufficient for training a model to infer the correct number and identity of referents, and semantic representation collapse, where standard Euclidean similarity forces hierarchically-related concepts into non-discriminative clusters, blurring categorical boundaries. To tackle these challenges, we propose a novel WGREC framework named Linguistic Instance-Split Hyperbolic-Euclidean (LIHE), which operates in two stages. The first stage, Referential Decoupling, predicts the number of target objects and decomposes the complex expression into simpler sub-expressions. The second stage, Referent Grounding, then localizes these sub-expressions using HEMix, our innovative hybrid similarity module that synergistically combines the precise alignment capabilities of Euclidean proximity with the hierarchical modeling strengths of hyperbolic geometry. This hybrid approach effectively prevents semantic collapse while preserving fine-grained distinctions between related concepts. Extensive experiments demonstrate LIHE establishes the first effective weakly supervised WGREC baseline on gRefCOCO and Ref-ZOM, while HEMix achieves consistent improvements on standard REC benchmarks, improving IoU@0.5 by up to 2.5\%. The code is available at https://anonymous.4open.science/r/LIHE.
Bind-Your-Avatar: Multi-Talking-Character Video Generation with Dynamic 3D-mask-based Embedding Router
Jun 24, 2025



Recent years have witnessed remarkable advances in audio-driven talking head generation. However, existing approaches predominantly focus on single-character scenarios. While some methods can create separate conversation videos between two individuals, the critical challenge of generating unified conversation videos with multiple physically co-present characters sharing the same spatial environment remains largely unaddressed. This setting presents two key challenges: audio-to-character correspondence control and the lack of suitable datasets featuring multi-character talking videos within the same scene. To address these challenges, we introduce Bind-Your-Avatar, an MM-DiT-based model specifically designed for multi-talking-character video generation in the same scene. Specifically, we propose (1) A novel framework incorporating a fine-grained Embedding Router that binds `who' and `speak what' together to address the audio-to-character correspondence control. (2) Two methods for implementing a 3D-mask embedding router that enables frame-wise, fine-grained control of individual characters, with distinct loss functions based on observed geometric priors and a mask refinement strategy to enhance the accuracy and temporal smoothness of the predicted masks. (3) The first dataset, to the best of our knowledge, specifically constructed for multi-talking-character video generation, and accompanied by an open-source data processing pipeline, and (4) A benchmark for the dual-talking-characters video generation, with extensive experiments demonstrating superior performance over multiple state-of-the-art methods.
MELLM: Exploring LLM-Powered Micro-Expression Understanding Enhanced by Subtle Motion Perception
May 11, 2025
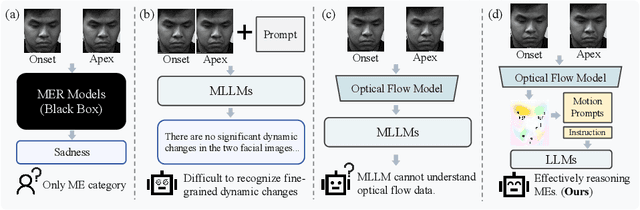
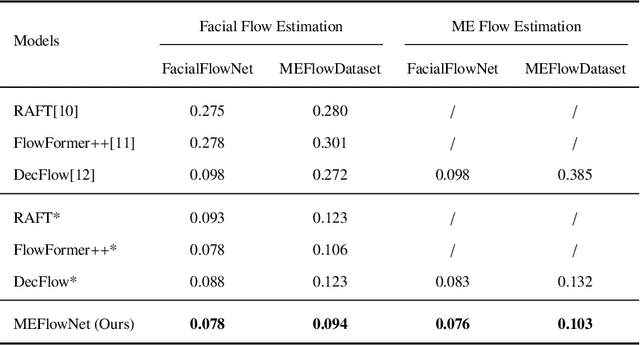
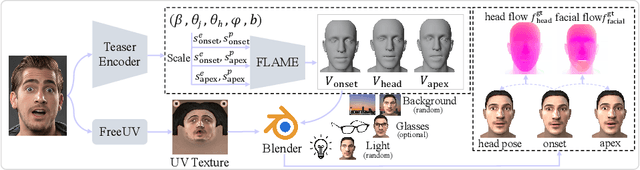
Micro-expressions (MEs) are crucial psychological responses with significant potential for affective computing. However, current automatic micro-expression recognition (MER) research primarily focuses on discrete emotion classification, neglecting a convincing analysis of the subtle dynamic movements and inherent emotional cues. The rapid progress in multimodal large language models (MLLMs), known for their strong multimodal comprehension and language generation abilities, offers new possibilities. MLLMs have shown success in various vision-language tasks, indicating their potential to understand MEs comprehensively, including both fine-grained motion patterns and underlying emotional semantics. Nevertheless, challenges remain due to the subtle intensity and short duration of MEs, as existing MLLMs are not designed to capture such delicate frame-level facial dynamics. In this paper, we propose a novel Micro-Expression Large Language Model (MELLM), which incorporates a subtle facial motion perception strategy with the strong inference capabilities of MLLMs, representing the first exploration of MLLMs in the domain of ME analysis. Specifically, to explicitly guide the MLLM toward motion-sensitive regions, we construct an interpretable motion-enhanced color map by fusing onset-apex optical flow dynamics with the corresponding grayscale onset frame as the model input. Additionally, specialized fine-tuning strategies are incorporated to further enhance the model's visual perception of MEs. Furthermore, we construct an instruction-description dataset based on Facial Action Coding System (FACS) annotations and emotion labels to train our MELLM. Comprehensive evaluations across multiple benchmark datasets demonstrate that our model exhibits superior robustness and generalization capabilities in ME understanding (MEU). Code is available at https://github.com/zyzhangUstc/MELLM.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
MME-Survey: A Comprehensive Survey on Evaluation of Multimodal LLMs
Nov 22, 2024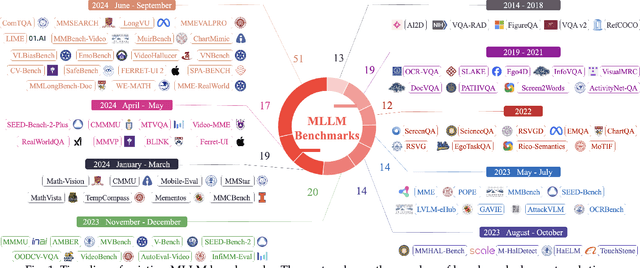
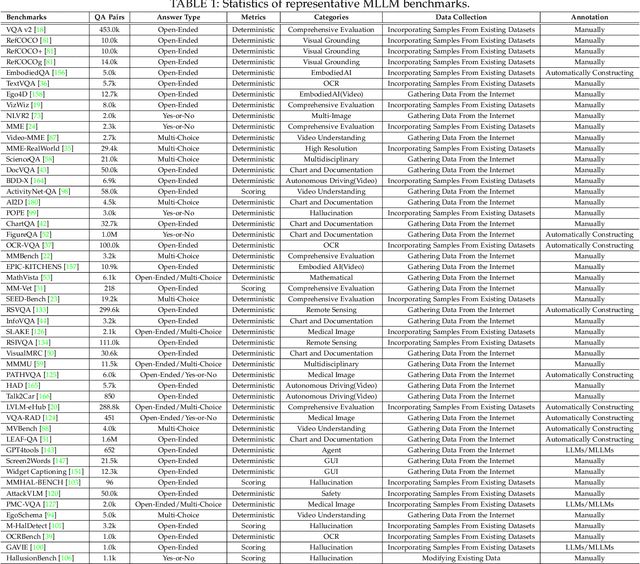
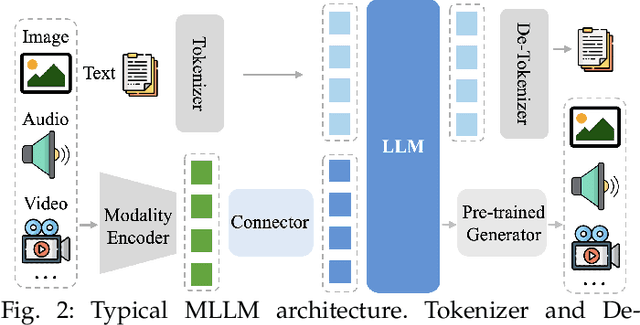
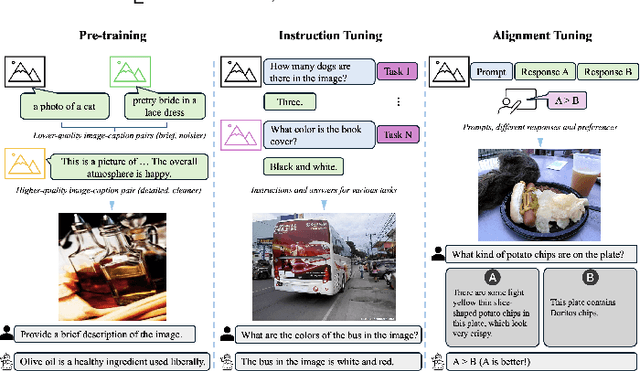
As a prominent direction of Artificial General Intelligence (AGI), Multimodal Large Language Models (MLLMs) have garnered increased attention from both industry and academia. Building upon pre-trained LLMs, this family of models further develops multimodal perception and reasoning capabilities that are impressive, such as writing code given a flow chart or creating stories based on an image. In the development process, evaluation is critical since it provides intuitive feedback and guidance on improving models. Distinct from the traditional train-eval-test paradigm that only favors a single task like image classification, the versatility of MLLMs has spurred the rise of various new benchmarks and evaluation methods. In this paper, we aim to present a comprehensive survey of MLLM evaluation, discussing four key aspects: 1) the summarised benchmarks types divided by the evaluation capabilities, including foundation capabilities, model self-analysis, and extented applications; 2) the typical process of benchmark counstruction, consisting of data collection, annotation, and precautions; 3) the systematic evaluation manner composed of judge, metric, and toolkit; 4) the outlook for the next benchmark. This work aims to offer researchers an easy grasp of how to effectively evaluate MLLMs according to different needs and to inspire better evaluation methods, thereby driving the progress of MLLM research.
Exploring User Retrieval Integration towards Large Language Models for Cross-Domain Sequential Recommendation
Jun 05, 2024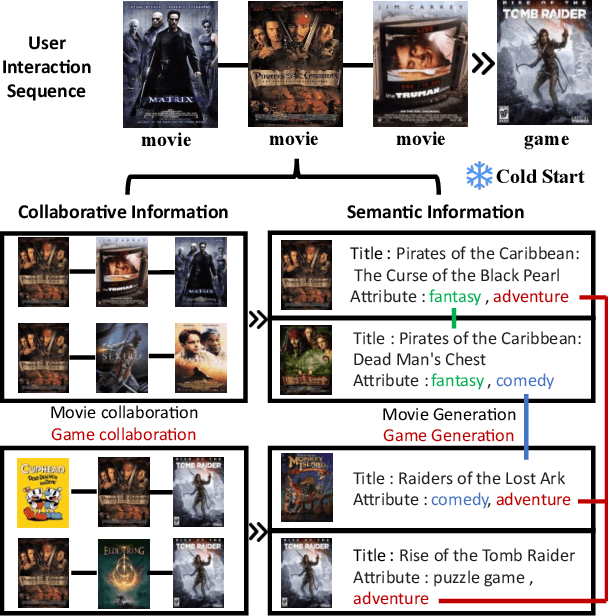
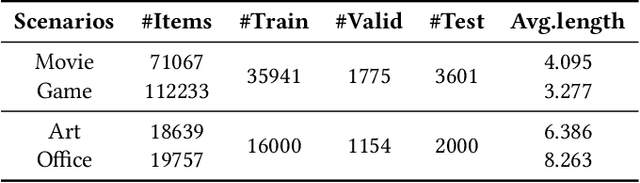
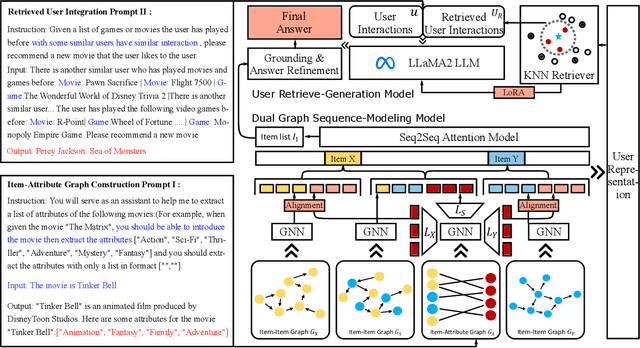
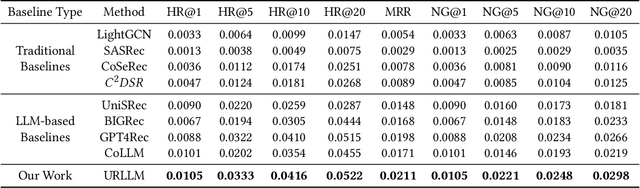
Cross-Domain Sequential Recommendation (CDSR) aims to mine and transfer users' sequential preferences across different domains to alleviate the long-standing cold-start issue. Traditional CDSR models capture collaborative information through user and item modeling while overlooking valuable semantic information. Recently, Large Language Model (LLM) has demonstrated powerful semantic reasoning capabilities, motivating us to introduce them to better capture semantic information. However, introducing LLMs to CDSR is non-trivial due to two crucial issues: seamless information integration and domain-specific generation. To this end, we propose a novel framework named URLLM, which aims to improve the CDSR performance by exploring the User Retrieval approach and domain grounding on LLM simultaneously. Specifically, we first present a novel dual-graph sequential model to capture the diverse information, along with an alignment and contrastive learning method to facilitate domain knowledge transfer. Subsequently, a user retrieve-generation model is adopted to seamlessly integrate the structural information into LLM, fully harnessing its emergent inferencing ability. Furthermore, we propose a domain-specific strategy and a refinement module to prevent out-of-domain generation. Extensive experiments on Amazon demonstrated the information integration and domain-specific generation ability of URLLM in comparison to state-of-the-art baselines. Our code is available at https://github.com/TingJShen/URLLM
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
May 31, 2024



In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding. The potential of MLLMs in processing sequential visual data is still insufficiently explored, highlighting the absence of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis. Our work distinguishes from existing benchmarks through four key features: 1) Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability; 2) Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics; 3) Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audios, to unveil the all-round capabilities of MLLMs; 4) Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. 900 videos with a total of 256 hours are manually selected and annotated by repeatedly viewing all the video content, resulting in 2,700 question-answer pairs. With Video-MME, we extensively evaluate various state-of-the-art MLLMs, including GPT-4 series and Gemini 1.5 Pro, as well as open-source image models like InternVL-Chat-V1.5 and video models like LLaVA-NeXT-Video. Our experiments reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models. Our dataset along with these findings underscores the need for further improvements in handling longer sequences and multi-modal data. Project Page: https://video-mme.github.io
Dataset Regeneration for Sequential Recommendation
May 28, 2024The sequential recommender (SR) system is a crucial component of modern recommender systems, as it aims to capture the evolving preferences of users. Significant efforts have been made to enhance the capabilities of SR systems. These methods typically follow the \textbf{model-centric} paradigm, which involves developing effective models based on fixed datasets. However, this approach often overlooks potential quality issues and flaws inherent in the data. Driven by the potential of \textbf{data-centric} AI, we propose a novel data-centric paradigm for developing an ideal training dataset using a model-agnostic dataset regeneration framework called DR4SR. This framework enables the regeneration of a dataset with exceptional cross-architecture generalizability. Additionally, we introduce the DR4SR+ framework, which incorporates a model-aware dataset personalizer to tailor the regenerated dataset specifically for a target model. To demonstrate the effectiveness of the data-centric paradigm, we integrate our framework with various model-centric methods and observe significant performance improvements across four widely adopted datasets. Furthermore, we conduct in-depth analyses to explore the potential of the data-centric paradigm and provide valuable insights. The code can be found at \textcolor{blue}{\url{https://anonymous.4open.science/r/KDD2024-86EA/}}
Learning Partially Aligned Item Representation for Cross-Domain Sequential Recommendation
May 21, 2024



Cross-domain sequential recommendation (CDSR) aims to uncover and transfer users' sequential preferences across multiple recommendation domains. While significant endeavors have been made, they primarily concentrated on developing advanced transfer modules and aligning user representations using self-supervised learning techniques. However, the problem of aligning item representations has received limited attention, and misaligned item representations can potentially lead to sub-optimal sequential modeling and user representation alignment. To this end, we propose a model-agnostic framework called \textbf{C}ross-domain item representation \textbf{A}lignment for \textbf{C}ross-\textbf{D}omain \textbf{S}equential \textbf{R}ecommendation (\textbf{CA-CDSR}), which achieves sequence-aware generation and adaptively partial alignment for item representations. Specifically, we first develop a sequence-aware feature augmentation strategy, which captures both collaborative and sequential item correlations, thus facilitating holistic item representation generation. Next, we conduct an empirical study to investigate the partial representation alignment problem from a spectrum perspective. It motivates us to devise an adaptive spectrum filter, achieving partial alignment adaptively. Furthermore, the aligned item representations can be fed into different sequential encoders to obtain user representations. The entire framework is optimized in a multi-task learning paradigm with an annealing strategy. Extensive experiments have demonstrated that CA-CDSR can surpass state-of-the-art baselines by a significant margin and can effectively align items in representation spaces to enhance performance.