 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActFER: Agentic Facial Expression Recognition via Active Tool-Augmented Visual Reasoning
Apr 10, 2026Recent advances in Multimodal Large Language Models (MLLMs) have created new opportunities for facial expression recognition (FER), moving it beyond pure label prediction toward reasoning-based affect understanding. However, existing MLLM-based FER methods still follow a passive paradigm: they rely on externally prepared facial inputs and perform single-pass reasoning over fixed visual evidence, without the capability for active facial perception. To address this limitation, we propose ActFER, an agentic framework that reformulates FER as active visual evidence acquisition followed by multimodal reasoning. Specifically, ActFER dynamically invokes tools for face detection and alignment, selectively zooms into informative local regions, and reasons over facial Action Units (AUs) and emotions through a visual Chain-of-Thought. To realize such behavior, we further develop Utility-Calibrated GRPO (UC-GRPO), a reinforcement learning algorithm tailored to agentic FER. UC-GRPO uses AU-grounded multi-level verifiable rewards to densify supervision, query-conditional contrastive utility estimation to enable sample-aware dynamic credit assignment for local inspection, and emotion-aware EMA calibration to reduce noisy utility estimates while capturing emotion-wise inspection tendencies. This algorithm enables ActFER to learn both when local inspection is beneficial and how to reason over the acquired evidence. Comprehensive experiments show that ActFER trained with UC-GRPO consistently outperforms passive MLLM-based FER baselines and substantially improves AU prediction accuracy.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
MELLM: Exploring LLM-Powered Micro-Expression Understanding Enhanced by Subtle Motion Perception
May 11, 2025
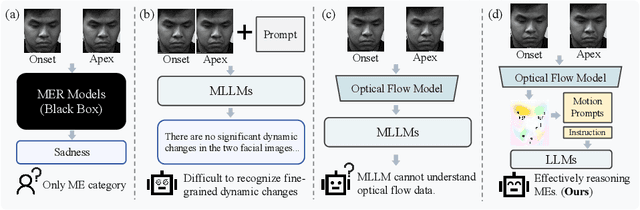
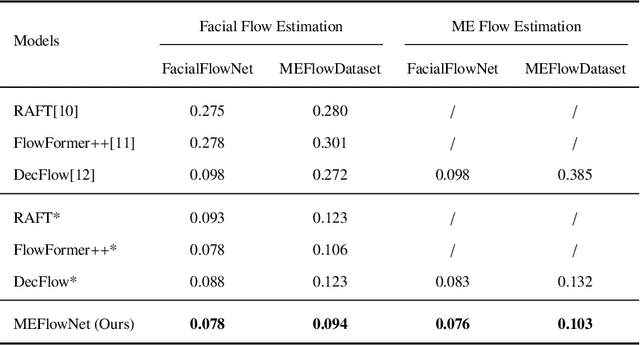
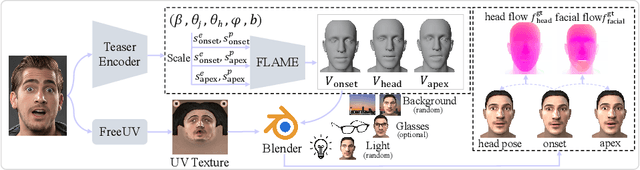
Micro-expressions (MEs) are crucial psychological responses with significant potential for affective computing. However, current automatic micro-expression recognition (MER) research primarily focuses on discrete emotion classification, neglecting a convincing analysis of the subtle dynamic movements and inherent emotional cues. The rapid progress in multimodal large language models (MLLMs), known for their strong multimodal comprehension and language generation abilities, offers new possibilities. MLLMs have shown success in various vision-language tasks, indicating their potential to understand MEs comprehensively, including both fine-grained motion patterns and underlying emotional semantics. Nevertheless, challenges remain due to the subtle intensity and short duration of MEs, as existing MLLMs are not designed to capture such delicate frame-level facial dynamics. In this paper, we propose a novel Micro-Expression Large Language Model (MELLM), which incorporates a subtle facial motion perception strategy with the strong inference capabilities of MLLMs, representing the first exploration of MLLMs in the domain of ME analysis. Specifically, to explicitly guide the MLLM toward motion-sensitive regions, we construct an interpretable motion-enhanced color map by fusing onset-apex optical flow dynamics with the corresponding grayscale onset frame as the model input. Additionally, specialized fine-tuning strategies are incorporated to further enhance the model's visual perception of MEs. Furthermore, we construct an instruction-description dataset based on Facial Action Coding System (FACS) annotations and emotion labels to train our MELLM. Comprehensive evaluations across multiple benchmark datasets demonstrate that our model exhibits superior robustness and generalization capabilities in ME understanding (MEU). Code is available at https://github.com/zyzhangUstc/MELLM.
AU-aware graph convolutional network for Macro- and Micro-expression spotting
Mar 16, 2023Automatic Micro-Expression (ME) spotting in long videos is a crucial step in ME analysis but also a challenging task due to the short duration and low intensity of MEs. When solving this problem, previous works generally lack in considering the structures of human faces and the correspondence between expressions and relevant facial muscles. To address this issue for better performance of ME spotting, this paper seeks to extract finer spatial features by modeling the relationships between facial Regions of Interest (ROIs). Specifically, we propose a graph convolutional-based network, called Action-Unit-aWare Graph Convolutional Network (AUW-GCN). Furthermore, to inject prior information and to cope with the problem of small datasets, AU-related statistics are encoded into the network. Comprehensive experiments show that our results outperform baseline methods consistently and achieve new SOTA performance in two benchmark datasets,CAS(ME)^2 and SAMM-LV. Our code is available at https://github.com/xjtupanda/AUW-GCN.
More is Better: A Database for Spontaneous Micro-Expression with High Frame Rates
Jan 03, 2023As one of the most important psychic stress reactions, micro-expressions (MEs), are spontaneous and transient facial expressions that can reveal the genuine emotions of human beings. Thus, recognizing MEs (MER) automatically is becoming increasingly crucial in the field of affective computing, and provides essential technical support in lie detection, psychological analysis and other areas. However, the lack of abundant ME data seriously restricts the development of cutting-edge data-driven MER models. Despite the recent efforts of several spontaneous ME datasets to alleviate this problem, it is still a tiny amount of work. To solve the problem of ME data hunger, we construct a dynamic spontaneous ME dataset with the largest current ME data scale, called DFME (Dynamic Facial Micro-expressions), which includes 7,526 well-labeled ME videos induced by 671 participants and annotated by more than 20 annotators throughout three years. Afterwards, we adopt four classical spatiotemporal feature learning models on DFME to perform MER experiments to objectively verify the validity of DFME dataset. In addition, we explore different solutions to the class imbalance and key-frame sequence sampling problems in dynamic MER respectively on DFME, so as to provide a valuable reference for future research. The comprehensive experimental results show that our DFME dataset can facilitate the research of automatic MER, and provide a new benchmark for MER. DFME will be published via https://mea-lab-421.github.io.
Sent2Span: Span Detection for PICO Extraction in the Biomedical Text without Span Annotations
Sep 06, 2021

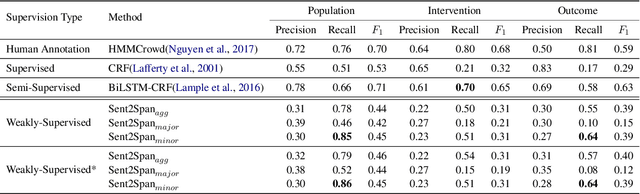

The rapid growth in published clinical trials makes it difficult to maintain up-to-date systematic reviews, which requires finding all relevant trials. This leads to policy and practice decisions based on out-of-date, incomplete, and biased subsets of available clinical evidence. Extracting and then normalising Population, Intervention, Comparator, and Outcome (PICO) information from clinical trial articles may be an effective way to automatically assign trials to systematic reviews and avoid searching and screening - the two most time-consuming systematic review processes. We propose and test a novel approach to PICO span detection. The major difference between our proposed method and previous approaches comes from detecting spans without needing annotated span data and using only crowdsourced sentence-level annotations. Experiments on two datasets show that PICO span detection results achieve much higher results for recall when compared to fully supervised methods with PICO sentence detection at least as good as human annotations. By removing the reliance on expert annotations for span detection, this work could be used in human-machine pipeline for turning low-quality crowdsourced, and sentence-level PICO annotations into structured information that can be used to quickly assign trials to relevant systematic reviews.
HAMNER: Headword Amplified Multi-span Distantly Supervised Method for Domain Specific Named Entity Recognition
Dec 03, 2019
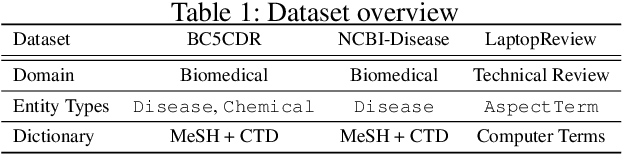

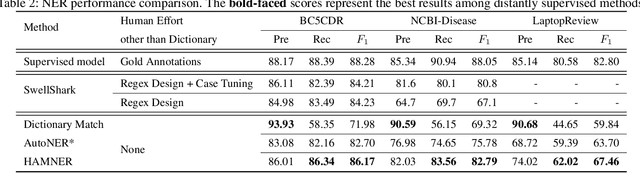
To tackle Named Entity Recognition (NER) tasks, supervised methods need to obtain sufficient cleanly annotated data, which is labor and time consuming. On the contrary, distantly supervised methods acquire automatically annotated data using dictionaries to alleviate this requirement. Unfortunately, dictionaries hinder the effectiveness of distantly supervised methods for NER due to its limited coverage, especially in specific domains. In this paper, we aim at the limitations of the dictionary usage and mention boundary detection. We generalize the distant supervision by extending the dictionary with headword based non-exact matching. We apply a function to better weight the matched entity mentions. We propose a span-level model, which classifies all the possible spans then infers the selected spans with a proposed dynamic programming algorithm. Experiments on all three benchmark datasets demonstrate that our method outperforms previous state-of-the-art distantly supervised methods.
On Tie Strength Augmented Social Correlation for Inferring Preference of Mobile Telco Users
Dec 09, 2016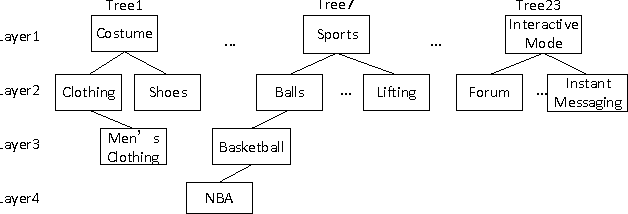
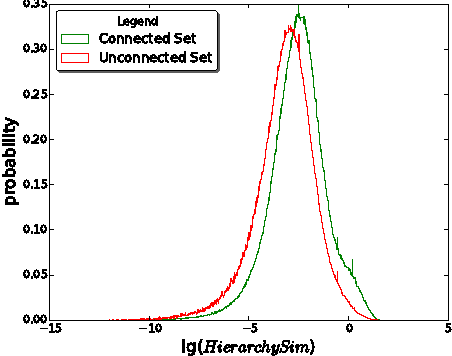
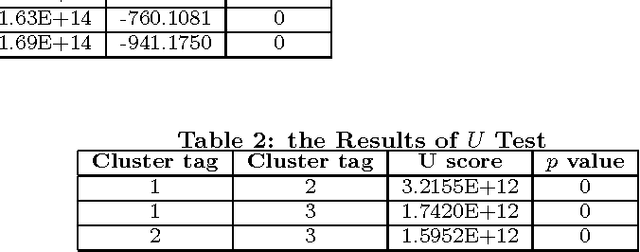
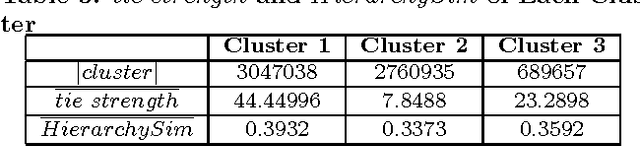
For mobile telecom operators, it is critical to build preference profiles of their customers and connected users, which can help operators make better marketing strategies, and provide more personalized services. With the deployment of deep packet inspection (DPI) in telecom networks, it is possible for the telco operators to obtain user online preference. However, DPI has its limitations and user preference derived only from DPI faces sparsity and cold start problems. To better infer the user preference, social correlation in telco users network derived from Call Detailed Records (CDRs) with regard to online preference is investigated. Though widely verified in several online social networks, social correlation between online preference of users in mobile telco networks, where the CDRs derived relationship are of less social properties and user mobile internet surfing activities are not visible to neighbourhood, has not been explored at a large scale. Based on a real world telecom dataset including CDRs and preference of more than $550K$ users for several months, we verified that correlation does exist between online preference in such \textit{ambiguous} social network. Furthermore, we found that the stronger ties that users build, the more similarity between their preference may have. After defining the preference inferring task as a Top-$K$ recommendation problem, we incorporated Matrix Factorization Collaborative Filtering model with social correlation and tie strength based on call patterns to generate Top-$K$ preferred categories for users. The proposed Tie Strength Augmented Social Recommendation (TSASoRec) model takes data sparsity and cold start user problems into account, considering both the recorded and missing recorded category entries. The experiment on real dataset shows the proposed model can better infer user preference, especially for cold start users.