 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntersectional Fairness in Vision-Language Models for Medical Image Disease Classification
Dec 24, 2025Medical artificial intelligence (AI) systems, particularly multimodal vision-language models (VLM), often exhibit intersectional biases where models are systematically less confident in diagnosing marginalised patient subgroups. Such bias can lead to higher rates of inaccurate and missed diagnoses due to demographically skewed data and divergent distributions of diagnostic certainty. Current fairness interventions frequently fail to address these gaps or compromise overall diagnostic performance to achieve statistical parity among the subgroups. In this study, we developed Cross-Modal Alignment Consistency (CMAC-MMD), a training framework that standardises diagnostic certainty across intersectional patient subgroups. Unlike traditional debiasing methods, this approach equalises the model's decision confidence without requiring sensitive demographic data during clinical inference. We evaluated this approach using 10,015 skin lesion images (HAM10000) with external validation on 12,000 images (BCN20000), and 10,000 fundus images for glaucoma detection (Harvard-FairVLMed), stratifying performance by intersectional age, gender, and race attributes. In the dermatology cohort, the proposed method reduced the overall intersectional missed diagnosis gap (difference in True Positive Rate, $Δ$TPR) from 0.50 to 0.26 while improving the overall Area Under the Curve (AUC) from 0.94 to 0.97 compared to standard training. Similarly, for glaucoma screening, the method reduced $Δ$TPR from 0.41 to 0.31, achieving a better AUC of 0.72 (vs. 0.71 baseline). This establishes a scalable framework for developing high-stakes clinical decision support systems that are both accurate and can perform equitably across diverse patient subgroups, ensuring reliable performance without increasing privacy risks.
Benchmarking for Public Health Surveillance tasks on Social Media with a Domain-Specific Pretrained Language Model
Apr 09, 2022
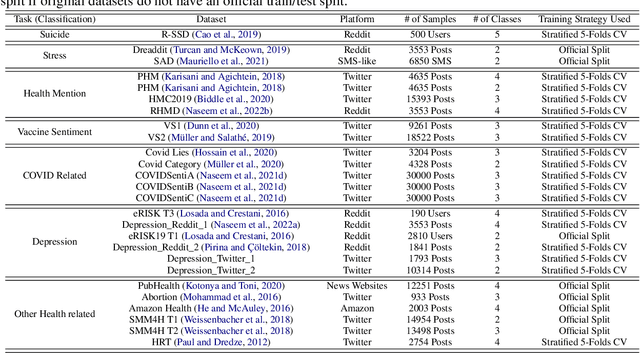
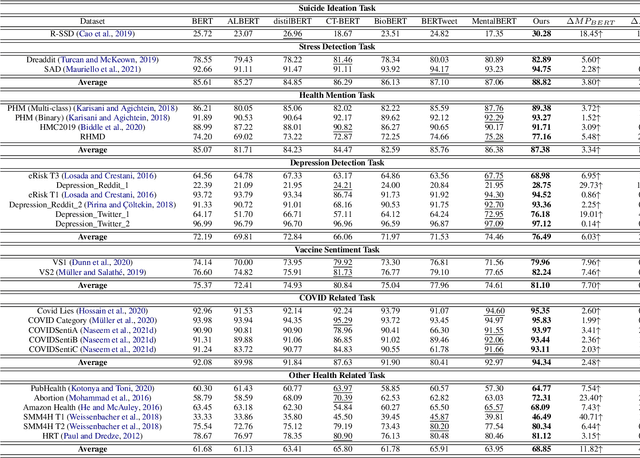
A user-generated text on social media enables health workers to keep track of information, identify possible outbreaks, forecast disease trends, monitor emergency cases, and ascertain disease awareness and response to official health correspondence. This exchange of health information on social media has been regarded as an attempt to enhance public health surveillance (PHS). Despite its potential, the technology is still in its early stages and is not ready for widespread application. Advancements in pretrained language models (PLMs) have facilitated the development of several domain-specific PLMs and a variety of downstream applications. However, there are no PLMs for social media tasks involving PHS. We present and release PHS-BERT, a transformer-based PLM, to identify tasks related to public health surveillance on social media. We compared and benchmarked the performance of PHS-BERT on 25 datasets from different social medial platforms related to 7 different PHS tasks. Compared with existing PLMs that are mainly evaluated on limited tasks, PHS-BERT achieved state-of-the-art performance on all 25 tested datasets, showing that our PLM is robust and generalizable in the common PHS tasks. By making PHS-BERT available, we aim to facilitate the community to reduce the computational cost and introduce new baselines for future works across various PHS-related tasks.
Sent2Span: Span Detection for PICO Extraction in the Biomedical Text without Span Annotations
Sep 06, 2021

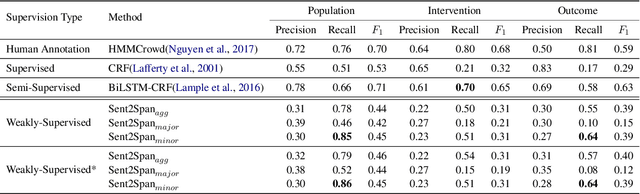

The rapid growth in published clinical trials makes it difficult to maintain up-to-date systematic reviews, which requires finding all relevant trials. This leads to policy and practice decisions based on out-of-date, incomplete, and biased subsets of available clinical evidence. Extracting and then normalising Population, Intervention, Comparator, and Outcome (PICO) information from clinical trial articles may be an effective way to automatically assign trials to systematic reviews and avoid searching and screening - the two most time-consuming systematic review processes. We propose and test a novel approach to PICO span detection. The major difference between our proposed method and previous approaches comes from detecting spans without needing annotated span data and using only crowdsourced sentence-level annotations. Experiments on two datasets show that PICO span detection results achieve much higher results for recall when compared to fully supervised methods with PICO sentence detection at least as good as human annotations. By removing the reliance on expert annotations for span detection, this work could be used in human-machine pipeline for turning low-quality crowdsourced, and sentence-level PICO annotations into structured information that can be used to quickly assign trials to relevant systematic reviews.
Benchmarking for Biomedical Natural Language Processing Tasks with a Domain Specific ALBERT
Jul 09, 2021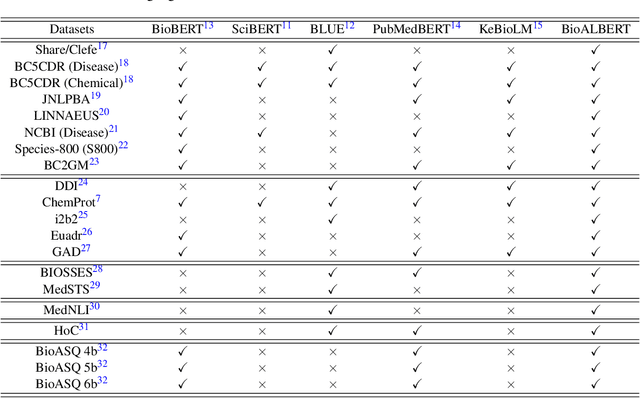


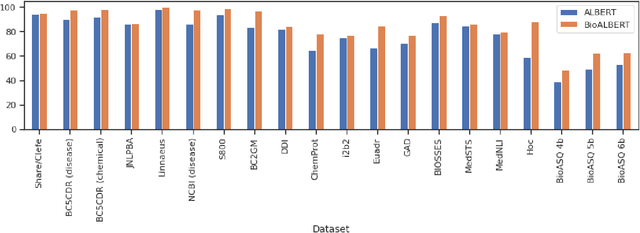
The availability of biomedical text data and advances in natural language processing (NLP) have made new applications in biomedical NLP possible. Language models trained or fine tuned using domain specific corpora can outperform general models, but work to date in biomedical NLP has been limited in terms of corpora and tasks. We present BioALBERT, a domain-specific adaptation of A Lite Bidirectional Encoder Representations from Transformers (ALBERT), trained on biomedical (PubMed and PubMed Central) and clinical (MIMIC-III) corpora and fine tuned for 6 different tasks across 20 benchmark datasets. Experiments show that BioALBERT outperforms the state of the art on named entity recognition (+11.09% BLURB score improvement), relation extraction (+0.80% BLURB score), sentence similarity (+1.05% BLURB score), document classification (+0.62% F1-score), and question answering (+2.83% BLURB score). It represents a new state of the art in 17 out of 20 benchmark datasets. By making BioALBERT models and data available, our aim is to help the biomedical NLP community avoid computational costs of training and establish a new set of baselines for future efforts across a broad range of biomedical NLP tasks.
Classifying vaccine sentiment tweets by modelling domain-specific representation and commonsense knowledge into context-aware attentive GRU
Jun 17, 2021
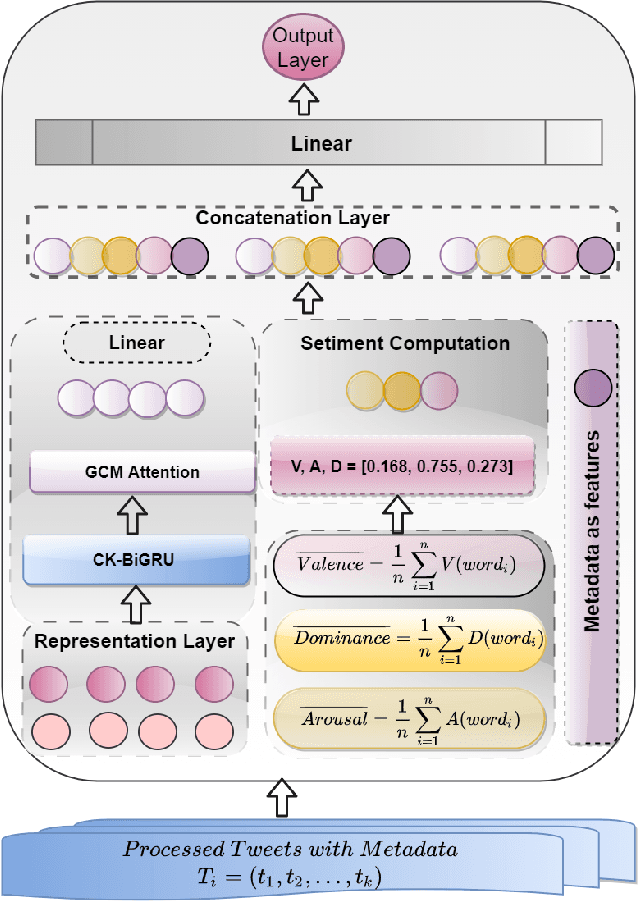
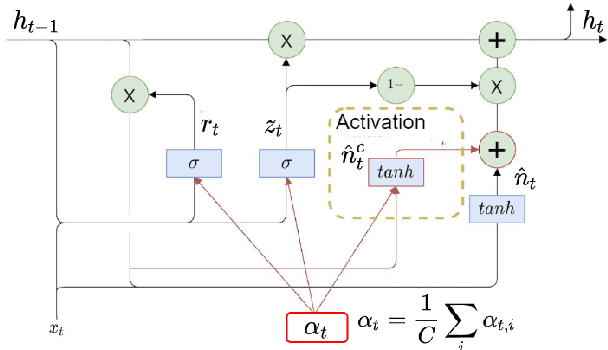
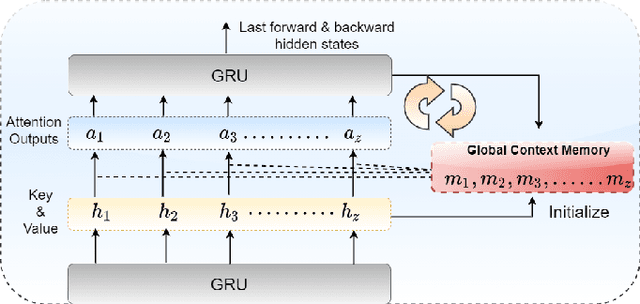
Vaccines are an important public health measure, but vaccine hesitancy and refusal can create clusters of low vaccine coverage and reduce the effectiveness of vaccination programs. Social media provides an opportunity to estimate emerging risks to vaccine acceptance by including geographical location and detailing vaccine-related concerns. Methods for classifying social media posts, such as vaccine-related tweets, use language models (LMs) trained on general domain text. However, challenges to measuring vaccine sentiment at scale arise from the absence of tonal stress and gestural cues and may not always have additional information about the user, e.g., past tweets or social connections. Another challenge in LMs is the lack of commonsense knowledge that are apparent in users metadata, i.e., emoticons, positive and negative words etc. In this study, to classify vaccine sentiment tweets with limited information, we present a novel end-to-end framework consisting of interconnected components that use domain-specific LM trained on vaccine-related tweets and models commonsense knowledge into a bidirectional gated recurrent network (CK-BiGRU) with context-aware attention. We further leverage syntactical, user metadata and sentiment information to capture the sentiment of a tweet. We experimented using two popular vaccine-related Twitter datasets and demonstrate that our proposed approach outperforms state-of-the-art models in identifying pro-vaccine, anti-vaccine and neutral tweets.
Mining Twitter to Assess the Determinants of Health Behavior towards Human Papillomavirus Vaccination in the United States
Jul 06, 2019

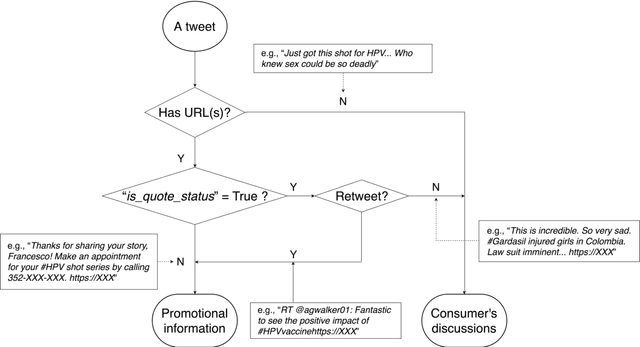

Objectives To test the feasibility of using Twitter data to assess determinants of consumers' health behavior towards Human papillomavirus (HPV) vaccination informed by the Integrated Behavior Model (IBM). Methods We used three Twitter datasets spanning from 2014 to 2018. We preprocessed and geocoded the tweets, and then built a rule-based model that classified each tweet into either promotional information or consumers' discussions. We applied topic modeling to discover major themes, and subsequently explored the associations between the topics learned from consumers' discussions and the responses of HPV-related questions in the Health Information National Trends Survey (HINTS). Results We collected 2,846,495 tweets and analyzed 335,681 geocoded tweets. Through topic modeling, we identified 122 high-quality topics. The most discussed consumer topic is "cervical cancer screening"; while in promotional tweets, the most popular topic is to increase awareness of "HPV causes cancer". 87 out of the 122 topics are correlated between promotional information and consumers' discussions. Guided by IBM, we examined the alignment between our Twitter findings and the results obtained from HINTS. 35 topics can be mapped to HINTS questions by keywords, 112 topics can be mapped to IBM constructs, and 45 topics have statistically significant correlations with HINTS responses in terms of geographic distributions. Conclusion Not only mining Twitter to assess consumers' health behaviors can obtain results comparable to surveys but can yield additional insights via a theory-driven approach. Limitations exist, nevertheless, these encouraging results impel us to develop innovative ways of leveraging social media in the changing health communication landscape.
Modelling spatiotemporal variation of positive and negative sentiment on Twitter to improve the identification of localised deviations
Feb 22, 2018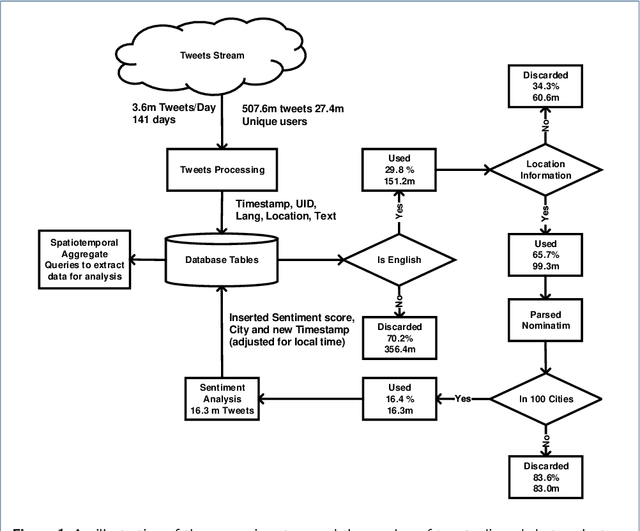
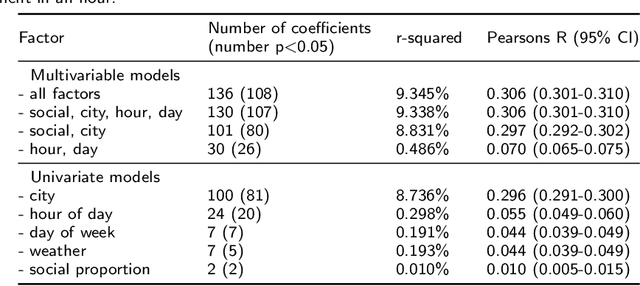
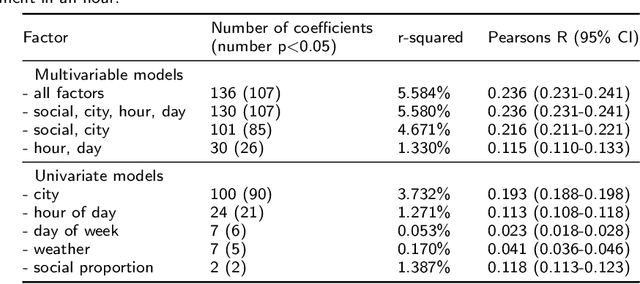
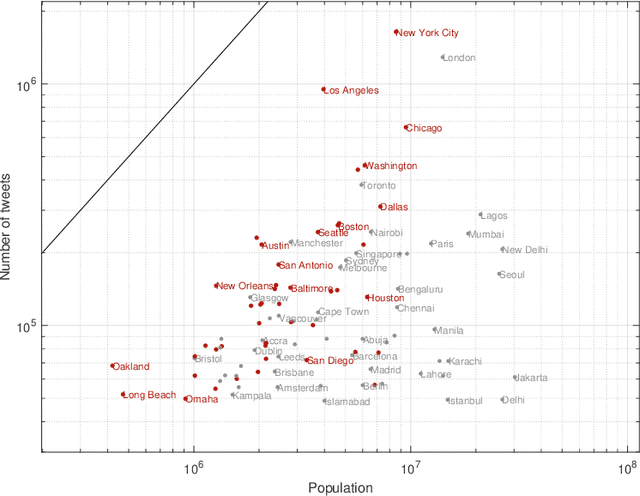
Studies examining how sentiment on social media varies over time and space appear to produce inconsistent results. Analysing 16.54 million English-language tweets from 100 cities posted between 13 July and 30 November 2017, our aim was to clarify how spatiotemporal and social factors contributed to variation in sentiment on Twitter. We estimated positive and negative sentiment for each of the cities using dictionary-based sentiment analysis and constructed models to explain differences in sentiment using time of day, day of week, weather, interaction type (social or non-social), and city as factors. Tests in a distinct but contiguous period of time showed that all factors were independently associated with sentiment. In the full multivariable model of positive (Pearson's R in test data 0.236; 95% CI 0.231-0.241), and negative (Pearson's R in test data 0.306 95% CI 0.301-0.310) sentiment, city and time of day explained more of the variance than other factors. Extreme differences between observed and expected sentiment using the full model appeared to be better aligned with international news events than degenerate models. In applications that aim to detect localised events using the sentiment of Twitter populations, it is useful to account for baseline differences before looking for unexpected changes.