 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Protocol for Intelligible Interaction Between Agents That Learn and Explain
Jan 04, 2023

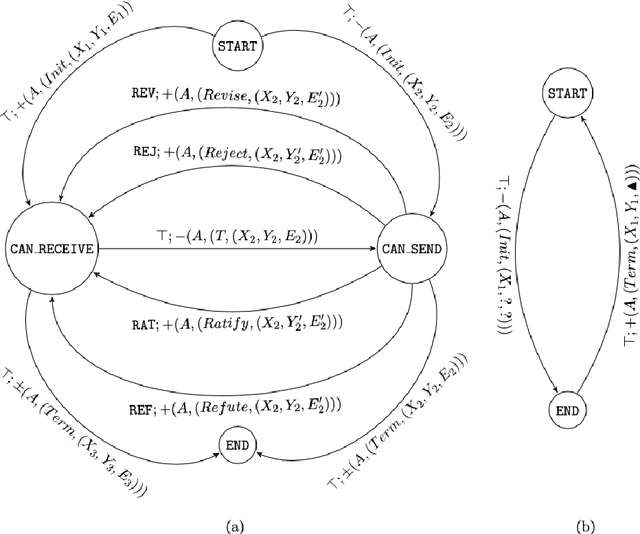

Recent engineering developments have seen the emergence of Machine Learning (ML) as a powerful form of data analysis with widespread applicability beyond its historical roots in the design of autonomous agents. However, relatively little attention has been paid to the interaction between people and ML systems. Recent developments on Explainable ML address this by providing visual and textual information on how the ML system arrived at a conclusion. In this paper we view the interaction between humans and ML systems within the broader context of interaction between agents capable of learning and explanation. Within this setting, we argue that it is more helpful to view the interaction as characterised by two-way intelligibility of information rather than once-off explanation of a prediction. We formulate two-way intelligibility as a property of a communication protocol. Development of the protocol is motivated by a set of `Intelligibility Axioms' for decision-support systems that use ML with a human-in-the-loop. The axioms are intended as sufficient criteria to claim that: (a) information provided by a human is intelligible to an ML system; and (b) information provided by an ML system is intelligible to a human. The axioms inform the design of a general synchronous interaction model between agents capable of learning and explanation. We identify conditions of compatibility between agents that result in bounded communication, and define Weak and Strong Two-Way Intelligibility between agents as properties of the communication protocol.
One-way Explainability Isn't The Message
May 05, 2022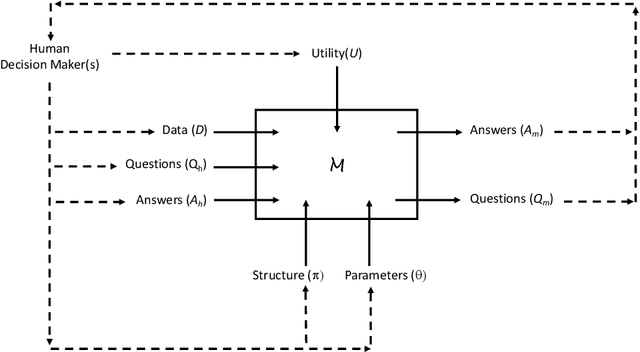

Recent engineering developments in specialised computational hardware, data-acquisition and storage technology have seen the emergence of Machine Learning (ML) as a powerful form of data analysis with widespread applicability beyond its historical roots in the design of autonomous agents. However -- possibly because of its origins in the development of agents capable of self-discovery -- relatively little attention has been paid to the interaction between people and ML. In this paper we are concerned with the use of ML in automated or semi-automated tools that assist one or more human decision makers. We argue that requirements on both human and machine in this context are significantly different to the use of ML either as part of autonomous agents for self-discovery or as part statistical data analysis. Our principal position is that the design of such human-machine systems should be driven by repeated, two-way intelligibility of information rather than one-way explainability of the ML-system's recommendations. Iterated rounds of intelligible information exchange, we think, will characterise the kinds of collaboration that will be needed to understand complex phenomena for which neither man or machine have complete answers. We propose operational principles -- we call them Intelligibility Axioms -- to guide the design of a collaborative decision-support system. The principles are concerned with: (a) what it means for information provided by the human to be intelligible to the ML system; and (b) what it means for an explanation provided by an ML system to be intelligible to a human. Using examples from the literature on the use of ML for drug-design and in medicine, we demonstrate cases where the conditions of the axioms are met. We describe some additional requirements needed for the design of a truly collaborative decision-support system.
Automatic Speech Summarisation: A Scoping Review
Aug 27, 2020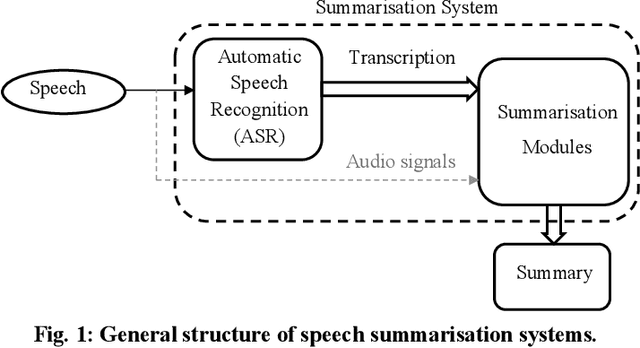
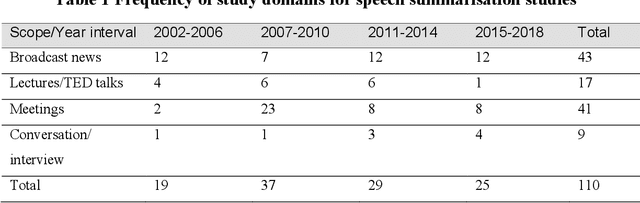
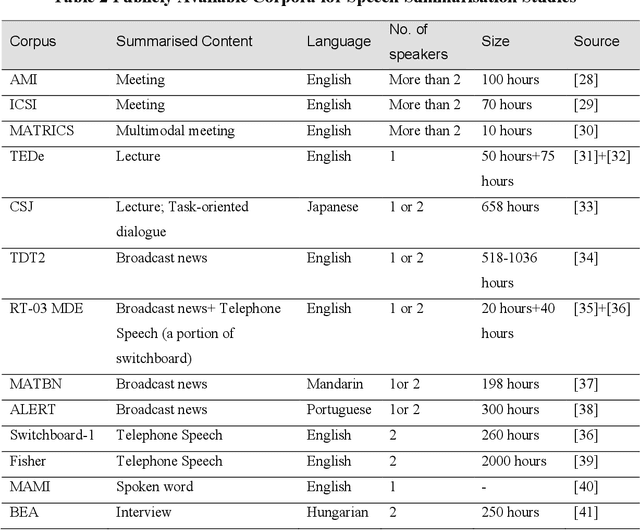
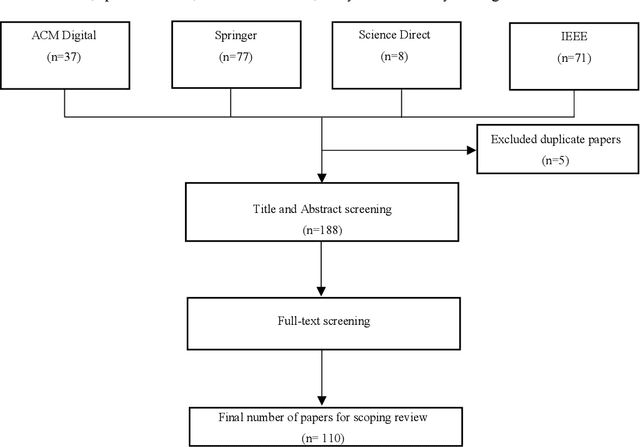
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.
Empirical Analysis of Zipf's Law, Power Law, and Lognormal Distributions in Medical Discharge Reports
Mar 30, 2020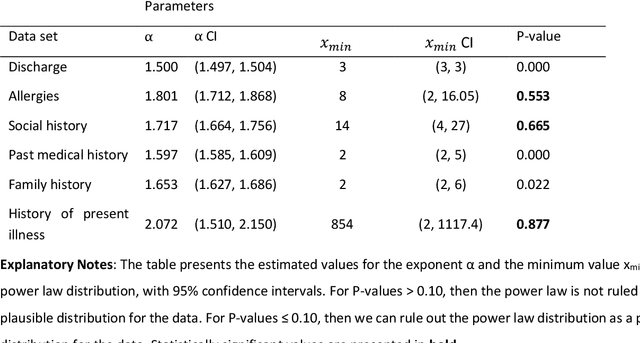
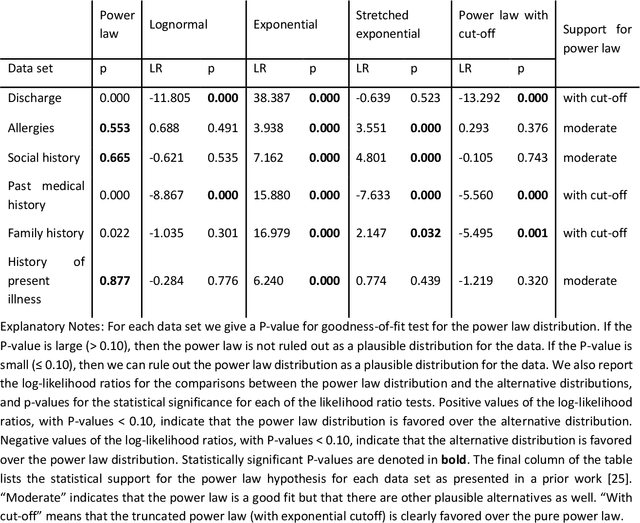
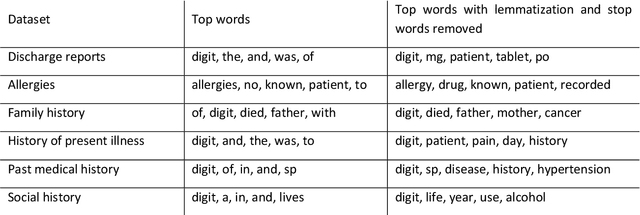
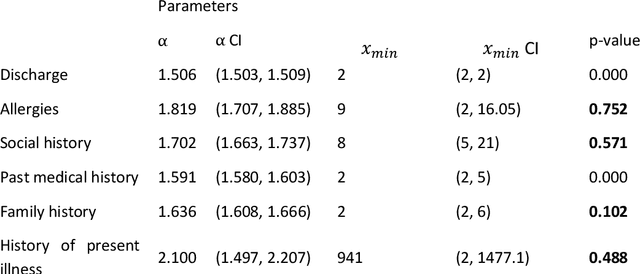
Bayesian modelling and statistical text analysis rely on informed probability priors to encourage good solutions. This paper empirically analyses whether text in medical discharge reports follow Zipf's law, a commonly assumed statistical property of language where word frequency follows a discrete power law distribution. We examined 20,000 medical discharge reports from the MIMIC-III dataset. Methods included splitting the discharge reports into tokens, counting token frequency, fitting power law distributions to the data, and testing whether alternative distributions--lognormal, exponential, stretched exponential, and truncated power law--provided superior fits to the data. Results show that discharge reports are best fit by the truncated power law and lognormal distributions. Our findings suggest that Bayesian modelling and statistical text analysis of discharge report text would benefit from using truncated power law and lognormal probability priors.
Modelling spatiotemporal variation of positive and negative sentiment on Twitter to improve the identification of localised deviations
Feb 22, 2018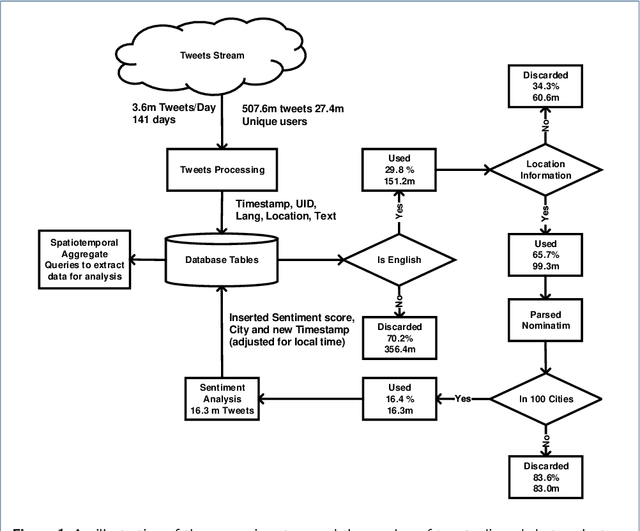
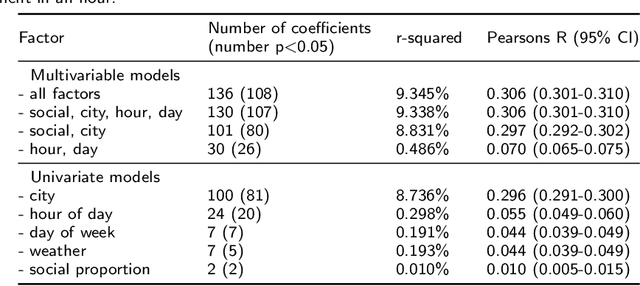
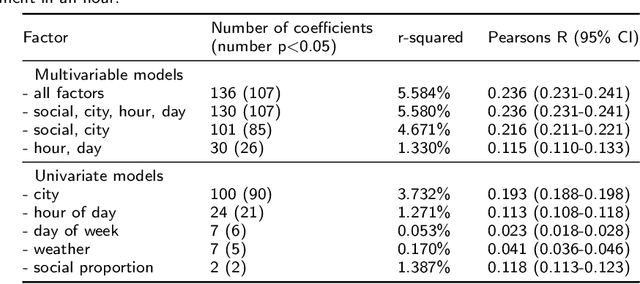
Studies examining how sentiment on social media varies over time and space appear to produce inconsistent results. Analysing 16.54 million English-language tweets from 100 cities posted between 13 July and 30 November 2017, our aim was to clarify how spatiotemporal and social factors contributed to variation in sentiment on Twitter. We estimated positive and negative sentiment for each of the cities using dictionary-based sentiment analysis and constructed models to explain differences in sentiment using time of day, day of week, weather, interaction type (social or non-social), and city as factors. Tests in a distinct but contiguous period of time showed that all factors were independently associated with sentiment. In the full multivariable model of positive (Pearson's R in test data 0.236; 95% CI 0.231-0.241), and negative (Pearson's R in test data 0.306 95% CI 0.301-0.310) sentiment, city and time of day explained more of the variance than other factors. Extreme differences between observed and expected sentiment using the full model appeared to be better aligned with international news events than degenerate models. In applications that aim to detect localised events using the sentiment of Twitter populations, it is useful to account for baseline differences before looking for unexpected changes.