 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Representation, Not Clinical Knowledge: Where Apparent LLM Triage Failures Originate
May 28, 2026Patient-voiced clinical-triage benchmarks report high under-triage rates for consumer LLMs for constrained multiple-choice output, yet the same cases score differently with free-text. We ask whether output format changes the model's \emph{clinical representation} or only the mapping from a preserved representation to an answer. Using sparse-autoencoder (SAE) features in Gemma 3 4B/12B IT and Qwen3-8B, we find the same medical features fire on the shared clinical narrative under both formats but go {silent} at the multiple-choice decision token in all the cases at every model. Three independent methods (natural-language autoencoder verbalization, decision-token logit attribution, and top-feature characterization) agree that scaffold and format features, but not medical features, drive the decision logits. Behaviorally, the multiple-choice penalty inverts under both structured and natural-language input, option-order shuffle rules out positional bias, and the gap is dominated by off-by-one decision (the model picks an adjacent acuity letter to the gold answer) rather than knowledge failure. Thus, the failure originates in the output format and not in the clinical representation.
Domain-Specific Pretraining Improves Confidence in Whole Slide Image Classification
Feb 20, 2023Whole Slide Images (WSIs) or histopathology images are used in digital pathology. WSIs pose great challenges to deep learning models for clinical diagnosis, owing to their size and lack of pixel-level annotations. With the recent advancements in computational pathology, newer multiple-instance learning-based models have been proposed. Multiple-instance learning for WSIs necessitates creating patches and uses the encoding of these patches for diagnosis. These models use generic pre-trained models (ResNet-50 pre-trained on ImageNet) for patch encoding. The recently proposed KimiaNet, a DenseNet121 model pre-trained on TCGA slides, is a domain-specific pre-trained model. This paper shows the effect of domain-specific pre-training on WSI classification. To investigate the impact of domain-specific pre-training, we considered the current state-of-the-art multiple-instance learning models, 1) CLAM, an attention-based model, and 2) TransMIL, a self-attention-based model, and evaluated the models' confidence and predictive performance in detecting primary brain tumors - gliomas. Domain-specific pre-training improves the confidence of the models and also achieves a new state-of-the-art performance of WSI-based glioma subtype classification, showing a high clinical applicability in assisting glioma diagnosis.
DDoD: Dual Denial of Decision Attacks on Human-AI Teams
Dec 07, 2022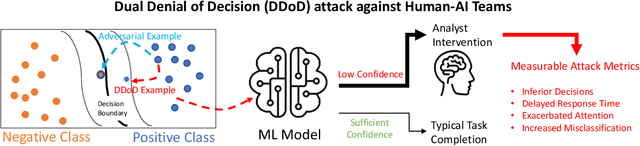
Artificial Intelligence (AI) systems have been increasingly used to make decision-making processes faster, more accurate, and more efficient. However, such systems are also at constant risk of being attacked. While the majority of attacks targeting AI-based applications aim to manipulate classifiers or training data and alter the output of an AI model, recently proposed Sponge Attacks against AI models aim to impede the classifier's execution by consuming substantial resources. In this work, we propose \textit{Dual Denial of Decision (DDoD) attacks against collaborative Human-AI teams}. We discuss how such attacks aim to deplete \textit{both computational and human} resources, and significantly impair decision-making capabilities. We describe DDoD on human and computational resources and present potential risk scenarios in a series of exemplary domains.
Automatic Speech Summarisation: A Scoping Review
Aug 27, 2020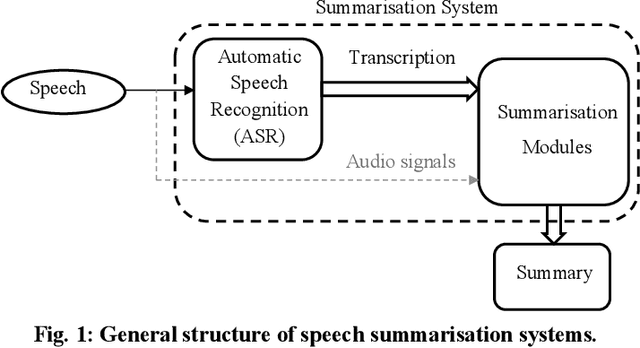
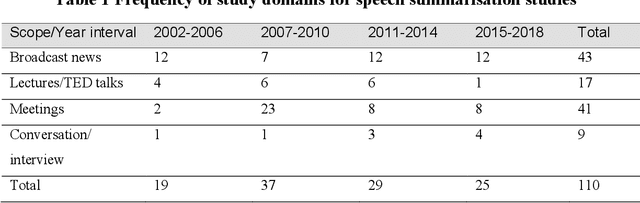
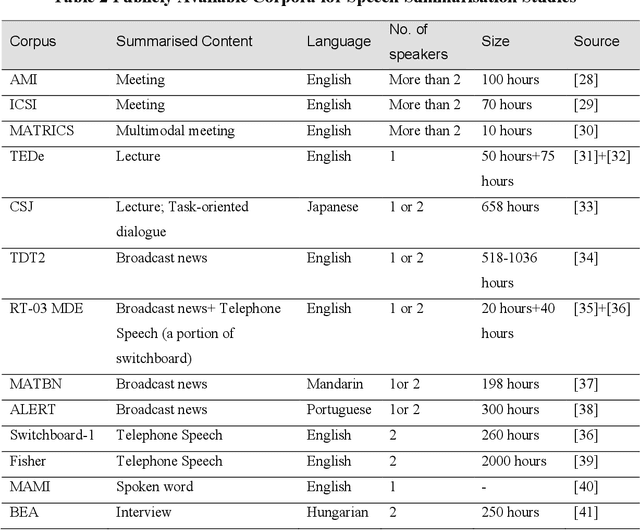
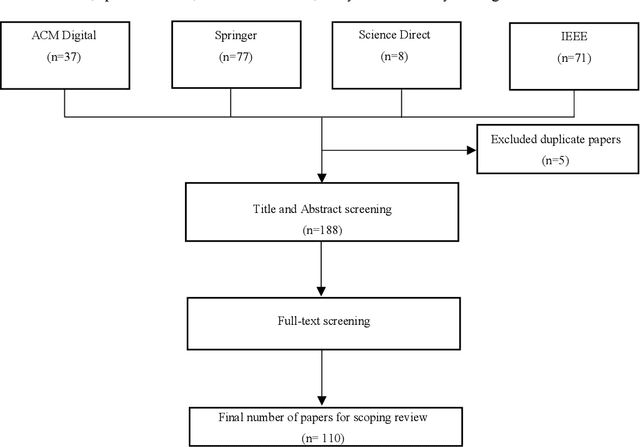
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.
Jointly Modeling Intra- and Inter-transaction Dependencies with Hierarchical Attentive Transaction Embeddings for Next-item Recommendation
May 30, 2020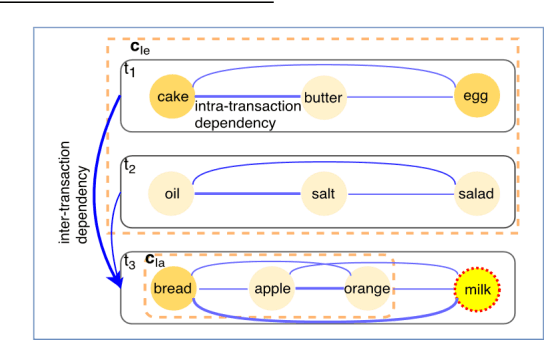
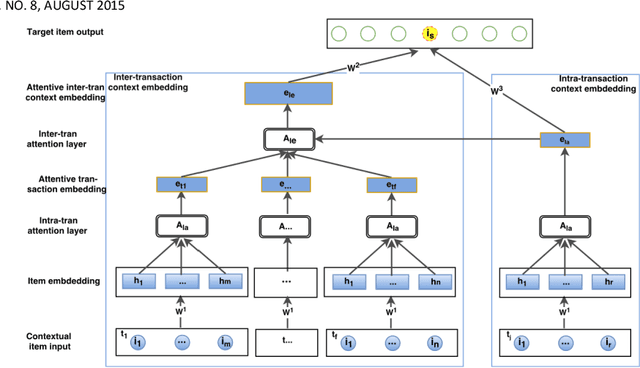
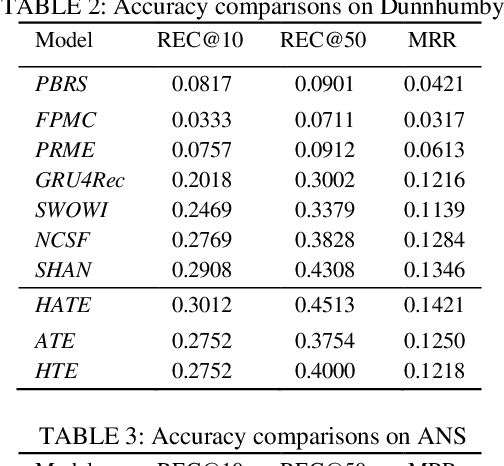
A transaction-based recommender system (TBRS) aims to predict the next item by modeling dependencies in transactional data. Generally, two kinds of dependencies considered are intra-transaction dependency and inter-transaction dependency. Most existing TBRSs recommend next item by only modeling the intra-transaction dependency within the current transaction while ignoring inter-transaction dependency with recent transactions that may also affect the next item. However, as not all recent transactions are relevant to the current and next items, the relevant ones should be identified and prioritized. In this paper, we propose a novel hierarchical attentive transaction embedding (HATE) model to tackle these issues. Specifically, a two-level attention mechanism integrates both item embedding and transaction embedding to build an attentive context representation that incorporates both intraand inter-transaction dependencies. With the learned context representation, HATE then recommends the next item. Experimental evaluations on two real-world transaction datasets show that HATE significantly outperforms the state-ofthe-art methods in terms of recommendation accuracy.
Empirical Analysis of Zipf's Law, Power Law, and Lognormal Distributions in Medical Discharge Reports
Mar 30, 2020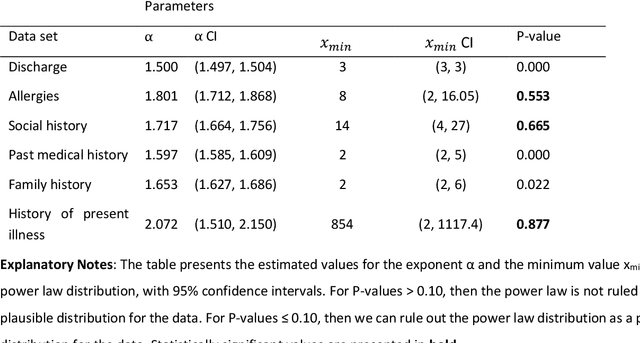
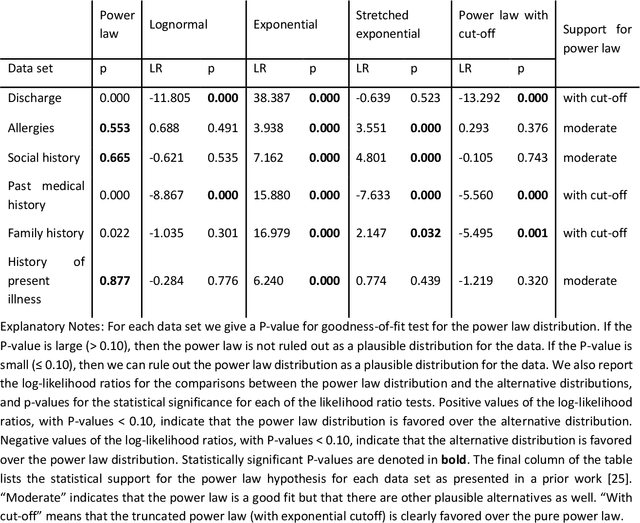
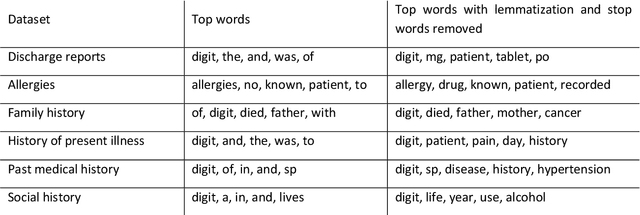
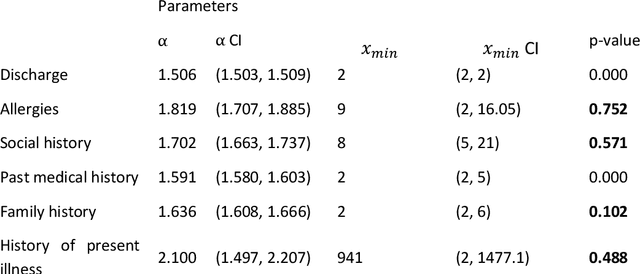
Bayesian modelling and statistical text analysis rely on informed probability priors to encourage good solutions. This paper empirically analyses whether text in medical discharge reports follow Zipf's law, a commonly assumed statistical property of language where word frequency follows a discrete power law distribution. We examined 20,000 medical discharge reports from the MIMIC-III dataset. Methods included splitting the discharge reports into tokens, counting token frequency, fitting power law distributions to the data, and testing whether alternative distributions--lognormal, exponential, stretched exponential, and truncated power law--provided superior fits to the data. Results show that discharge reports are best fit by the truncated power law and lognormal distributions. Our findings suggest that Bayesian modelling and statistical text analysis of discharge report text would benefit from using truncated power law and lognormal probability priors.
Graph Based Recommendations: From Data Representation to Feature Extraction and Application
Jul 05, 2017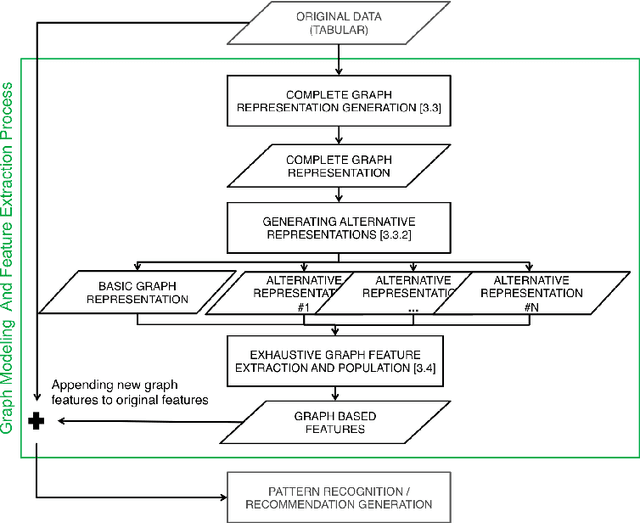

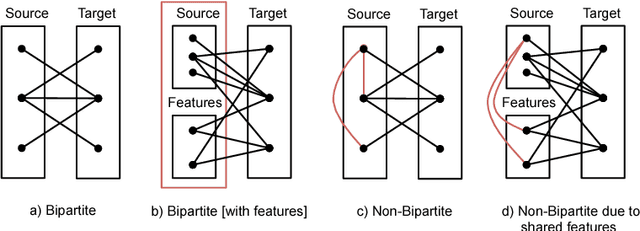

Modeling users for the purpose of identifying their preferences and then personalizing services on the basis of these models is a complex task, primarily due to the need to take into consideration various explicit and implicit signals, missing or uncertain information, contextual aspects, and more. In this study, a novel generic approach for uncovering latent preference patterns from user data is proposed and evaluated. The approach relies on representing the data using graphs, and then systematically extracting graph-based features and using them to enrich the original user models. The extracted features encapsulate complex relationships between users, items, and metadata. The enhanced user models can then serve as an input to any recommendation algorithm. The proposed approach is domain-independent (demonstrated on data from movies, music, and business recommender systems), and is evaluated using several state-of-the-art machine learning methods, on different recommendation tasks, and using different evaluation metrics. The results show a unanimous improvement in the recommendation accuracy across tasks and domains. In addition, the evaluation provides a deeper analysis regarding the performance of the approach in special scenarios, including high sparsity and variability of ratings.
Does Weather Matter? Causal Analysis of TV Logs
Mar 24, 2017
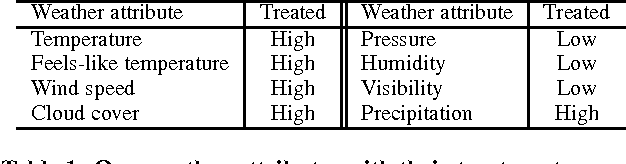
Weather affects our mood and behaviors, and many aspects of our life. When it is sunny, most people become happier; but when it rains, some people get depressed. Despite this evidence and the abundance of data, weather has mostly been overlooked in the machine learning and data science research. This work presents a causal analysis of how weather affects TV watching patterns. We show that some weather attributes, such as pressure and precipitation, cause major changes in TV watching patterns. To the best of our knowledge, this is the first large-scale causal study of the impact of weather on TV watching patterns.
DUM: Diversity-Weighted Utility Maximization for Recommendations
Nov 13, 2014


The need for diversification of recommendation lists manifests in a number of recommender systems use cases. However, an increase in diversity may undermine the utility of the recommendations, as relevant items in the list may be replaced by more diverse ones. In this work we propose a novel method for maximizing the utility of the recommended items subject to the diversity of user's tastes, and show that an optimal solution to this problem can be found greedily. We evaluate the proposed method in two online user studies as well as in an offline analysis incorporating a number of evaluation metrics. The results of evaluations show the superiority of our method over a number of baselines.