 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Wrote the Book? Detecting and Attributing LLM Ghostwriters
Mar 30, 2026In this paper, we introduce GhostWriteBench, a dataset for LLM authorship attribution. It comprises long-form texts (50K+ words per book) generated by frontier LLMs, and is designed to test generalisation across multiple out-of-distribution (OOD) dimensions, including domain and unseen LLM author. We also propose TRACE -- a novel fingerprinting method that is interpretable and lightweight -- that works for both open- and closed-source models. TRACE creates the fingerprint by capturing token-level transition patterns (e.g., word rank) estimated by another lightweight language model. Experiments on GhostWriteBench demonstrate that TRACE achieves state-of-the-art performance, remains robust in OOD settings, and works well in limited training data scenarios.
AdaptDel: Adaptable Deletion Rate Randomized Smoothing for Certified Robustness
Nov 12, 2025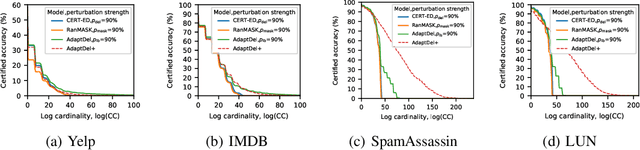
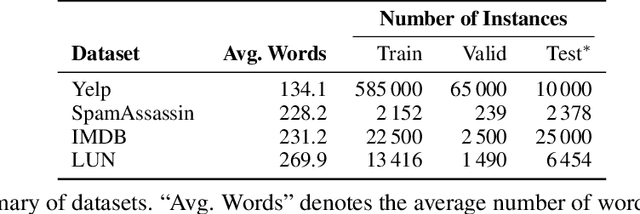
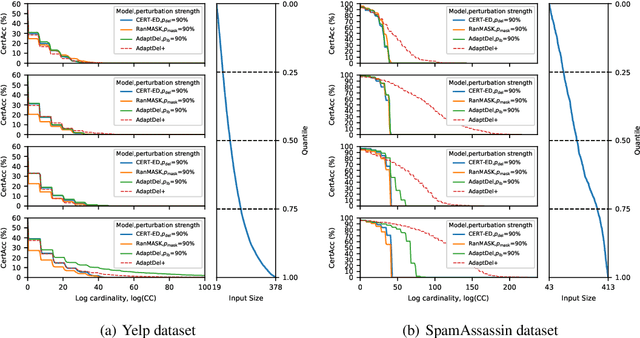
We consider the problem of certified robustness for sequence classification against edit distance perturbations. Naturally occurring inputs of varying lengths (e.g., sentences in natural language processing tasks) present a challenge to current methods that employ fixed-rate deletion mechanisms and lead to suboptimal performance. To this end, we introduce AdaptDel methods with adaptable deletion rates that dynamically adjust based on input properties. We extend the theoretical framework of randomized smoothing to variable-rate deletion, ensuring sound certification with respect to edit distance. We achieve strong empirical results in natural language tasks, observing up to 30 orders of magnitude improvement to median cardinality of the certified region, over state-of-the-art certifications.
CERT-ED: Certifiably Robust Text Classification for Edit Distance
Aug 01, 2024With the growing integration of AI in daily life, ensuring the robustness of systems to inference-time attacks is crucial. Among the approaches for certifying robustness to such adversarial examples, randomized smoothing has emerged as highly promising due to its nature as a wrapper around arbitrary black-box models. Previous work on randomized smoothing in natural language processing has primarily focused on specific subsets of edit distance operations, such as synonym substitution or word insertion, without exploring the certification of all edit operations. In this paper, we adapt Randomized Deletion (Huang et al., 2023) and propose, CERTified Edit Distance defense (CERT-ED) for natural language classification. Through comprehensive experiments, we demonstrate that CERT-ED outperforms the existing Hamming distance method RanMASK (Zeng et al., 2023) in 4 out of 5 datasets in terms of both accuracy and the cardinality of the certificate. By covering various threat models, including 5 direct and 5 transfer attacks, our method improves empirical robustness in 38 out of 50 settings.
RS-Reg: Probabilistic and Robust Certified Regression Through Randomized Smoothing
May 14, 2024



Randomized smoothing has shown promising certified robustness against adversaries in classification tasks. Despite such success with only zeroth-order access to base models, randomized smoothing has not been extended to a general form of regression. By defining robustness in regression tasks flexibly through probabilities, we demonstrate how to establish upper bounds on input data point perturbation (using the $\ell_2$ norm) for a user-specified probability of observing valid outputs. Furthermore, we showcase the asymptotic property of a basic averaging function in scenarios where the regression model operates without any constraint. We then derive a certified upper bound of the input perturbations when dealing with a family of regression models where the outputs are bounded. Our simulations verify the validity of the theoretical results and reveal the advantages and limitations of simple smoothing functions, i.e., averaging, in regression tasks. The code is publicly available at \url{https://github.com/arekavandi/Certified_Robust_Regression}.
Information Leakage from Data Updates in Machine Learning Models
Sep 20, 2023



In this paper we consider the setting where machine learning models are retrained on updated datasets in order to incorporate the most up-to-date information or reflect distribution shifts. We investigate whether one can infer information about these updates in the training data (e.g., changes to attribute values of records). Here, the adversary has access to snapshots of the machine learning model before and after the change in the dataset occurs. Contrary to the existing literature, we assume that an attribute of a single or multiple training data points are changed rather than entire data records are removed or added. We propose attacks based on the difference in the prediction confidence of the original model and the updated model. We evaluate our attack methods on two public datasets along with multi-layer perceptron and logistic regression models. We validate that two snapshots of the model can result in higher information leakage in comparison to having access to only the updated model. Moreover, we observe that data records with rare values are more vulnerable to attacks, which points to the disparate vulnerability of privacy attacks in the update setting. When multiple records with the same original attribute value are updated to the same new value (i.e., repeated changes), the attacker is more likely to correctly guess the updated values since repeated changes leave a larger footprint on the trained model. These observations point to vulnerability of machine learning models to attribute inference attacks in the update setting.
Certified Robustness of Learning-based Static Malware Detectors
Jan 31, 2023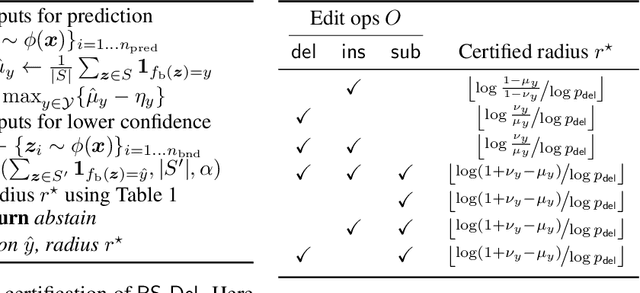


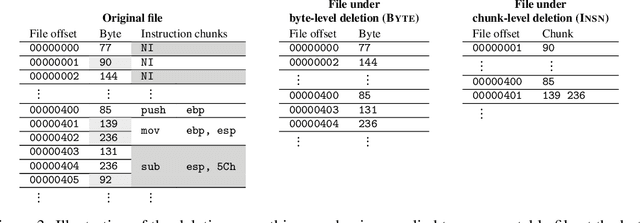
Certified defenses are a recent development in adversarial machine learning (ML), which aim to rigorously guarantee the robustness of ML models to adversarial perturbations. A large body of work studies certified defenses in computer vision, where $\ell_p$ norm-bounded evasion attacks are adopted as a tractable threat model. However, this threat model has known limitations in vision, and is not applicable to other domains -- e.g., where inputs may be discrete or subject to complex constraints. Motivated by this gap, we study certified defenses for malware detection, a domain where attacks against ML-based systems are a real and current threat. We consider static malware detection systems that operate on byte-level data. Our certified defense is based on the approach of randomized smoothing which we adapt by: (1) replacing the standard Gaussian randomization scheme with a novel deletion randomization scheme that operates on bytes or chunks of an executable; and (2) deriving a certificate that measures robustness to evasion attacks in terms of generalized edit distance. To assess the size of robustness certificates that are achievable while maintaining high accuracy, we conduct experiments on malware datasets using a popular convolutional malware detection model, MalConv. We are able to accurately classify 91% of the inputs while being certifiably robust to any adversarial perturbations of edit distance 128 bytes or less. By comparison, an existing certification of up to 128 bytes of substitutions (without insertions or deletions) achieves an accuracy of 78%. In addition, given that robustness certificates are conservative, we evaluate practical robustness to several recently published evasion attacks and, in some cases, find robustness beyond certified guarantees.
DDoD: Dual Denial of Decision Attacks on Human-AI Teams
Dec 07, 2022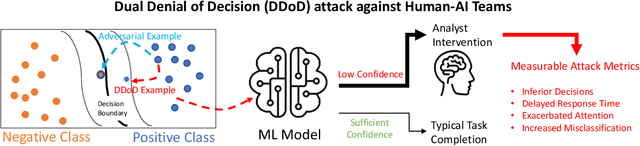
Artificial Intelligence (AI) systems have been increasingly used to make decision-making processes faster, more accurate, and more efficient. However, such systems are also at constant risk of being attacked. While the majority of attacks targeting AI-based applications aim to manipulate classifiers or training data and alter the output of an AI model, recently proposed Sponge Attacks against AI models aim to impede the classifier's execution by consuming substantial resources. In this work, we propose \textit{Dual Denial of Decision (DDoD) attacks against collaborative Human-AI teams}. We discuss how such attacks aim to deplete \textit{both computational and human} resources, and significantly impair decision-making capabilities. We describe DDoD on human and computational resources and present potential risk scenarios in a series of exemplary domains.
Verifiable and Provably Secure Machine Unlearning
Oct 17, 2022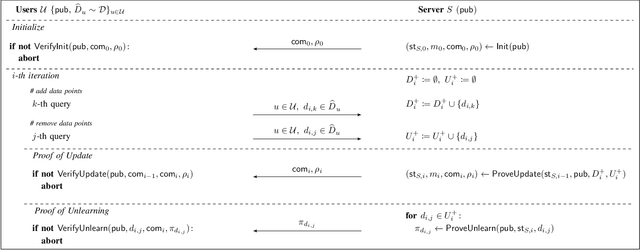



Machine unlearning aims to remove points from the training dataset of a machine learning model after training; for example when a user requests their data to be deleted. While many machine unlearning methods have been proposed, none of them enable users to audit the unlearning procedure and verify that their data was indeed unlearned. To address this, we define the first cryptographic framework to formally capture the security of verifiable machine unlearning. While our framework is generally applicable to different approaches, its advantages are perhaps best illustrated by our instantiation for the canonical approach to unlearning: retraining the model without the data to be unlearned. In our cryptographic protocol, the server first computes a proof that the model was trained on a dataset~$D$. Given a user data point $d$, the server then computes a proof of unlearning that shows that $d \notin D$. We realize our protocol using a SNARK and Merkle trees to obtain proofs of update and unlearning on the data. Based on cryptographic assumptions, we then present a formal game-based proof that our instantiation is secure. Finally, we validate the practicality of our constructions for unlearning in linear regression, logistic regression, and neural networks.
Protecting Global Properties of Datasets with Distribution Privacy Mechanisms
Jul 18, 2022

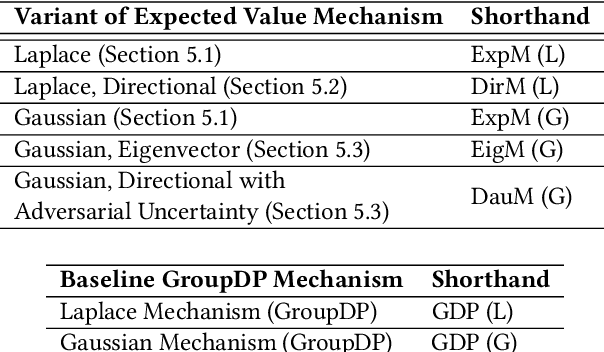

Alongside the rapid development of data collection and analysis techniques in recent years, there is increasingly an emphasis on the need to address information leakage associated with such usage of data. To this end, much work in the privacy literature is devoted to the protection of individual users and contributors of data. However, some situations instead require a different notion of data confidentiality involving global properties aggregated over the records of a dataset. Such notions of information protection are particularly applicable for business and organization data, where global properties may reflect trade secrets, or demographic data, which can be harmful if mishandled. Recent work on property inference attacks furthermore shows how data analysis algorithms can be susceptible to leaking these global properties of data, highlighting the importance of developing mechanisms that can protect such information. In this work, we demonstrate how a distribution privacy framework can be applied to formalize the problem of protecting global properties of datasets. Given this framework, we investigate several mechanisms and their tradeoffs for providing this notion of data confidentiality. We analyze the theoretical protection guarantees offered by these mechanisms under various data assumptions, then implement and empirically evaluate these mechanisms for several data analysis tasks. The results of our experiments show that our mechanisms can indeed reduce the effectiveness of practical property inference attacks while providing utility substantially greater than a crude group differential privacy baseline. Our work thus provides groundwork for theoretically supported mechanisms for protecting global properties of datasets.
Oblivious Sampling Algorithms for Private Data Analysis
Sep 28, 2020


We study secure and privacy-preserving data analysis based on queries executed on samples from a dataset. Trusted execution environments (TEEs) can be used to protect the content of the data during query computation, while supporting differential-private (DP) queries in TEEs provides record privacy when query output is revealed. Support for sample-based queries is attractive due to \emph{privacy amplification} since not all dataset is used to answer a query but only a small subset. However, extracting data samples with TEEs while proving strong DP guarantees is not trivial as secrecy of sample indices has to be preserved. To this end, we design efficient secure variants of common sampling algorithms. Experimentally we show that accuracy of models trained with shuffling and sampling is the same for differentially private models for MNIST and CIFAR-10, while sampling provides stronger privacy guarantees than shuffling.