 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplication-Robust Payoff-Allocation with Applications in Machine Learning Marketplaces
Jun 25, 2020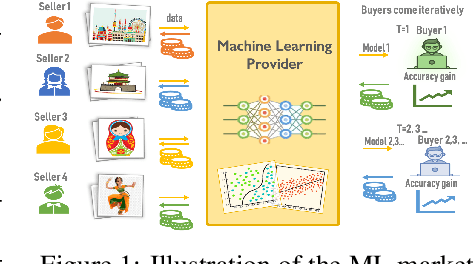
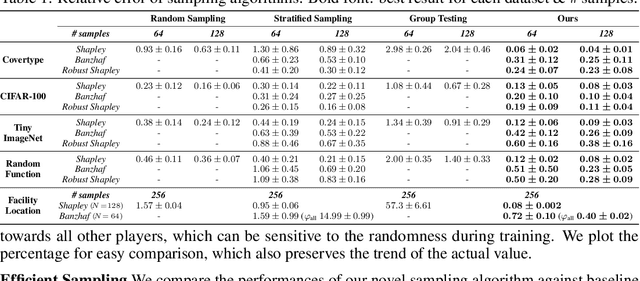
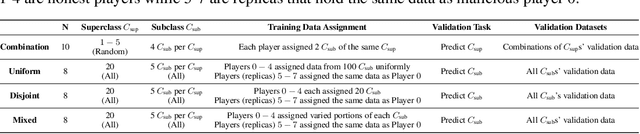
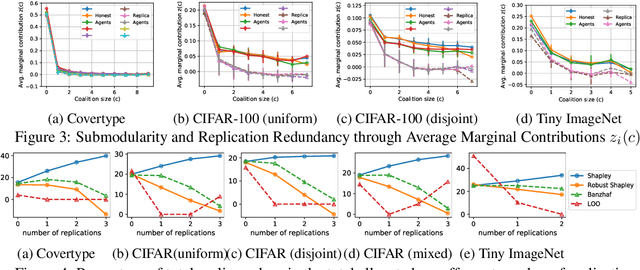
The ever-increasing take-up of machine learning techniques requires ever-more application-specific training data. Manually collecting such training data is a tedious and time-consuming process. Data marketplaces represent a compelling alternative, providing an easy way for acquiring data from potential data providers. A key component of such marketplaces is the compensation mechanism for data providers. Classic payoff-allocation methods such as the Shapley value can be vulnerable to data-replication attacks, and are infeasible to compute in the absence of efficient approximation algorithms. To address these challenges, we present an extensive theoretical study on the vulnerabilities of game theoretic payoff-allocation schemes to replication attacks. Our insights apply to a wide range of payoff-allocation schemes, and enable the design of customised replication-robust payoff-allocations. Furthermore, we present a novel efficient sampling algorithm for approximating payoff-allocation schemes based on marginal contributions. In our experiments, we validate the replication-robustness of classic payoff-allocation schemes and new payoff-allocation schemes derived from our theoretical insights. We also demonstrate the efficiency of our proposed sampling algorithm on a wide range of machine learning tasks.
Multi-agent Hierarchical Reinforcement Learning with Dynamic Termination
Oct 21, 2019
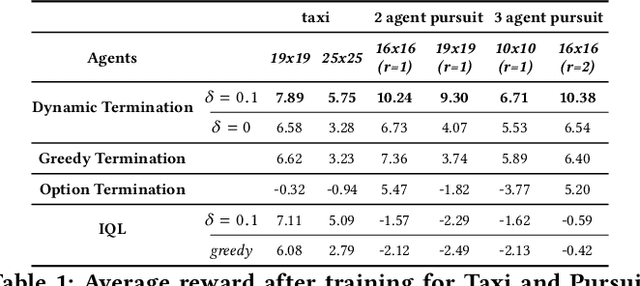
In a multi-agent system, an agent's optimal policy will typically depend on the policies chosen by others. Therefore, a key issue in multi-agent systems research is that of predicting the behaviours of others, and responding promptly to changes in such behaviours. One obvious possibility is for each agent to broadcast their current intention, for example, the currently executed option in a hierarchical reinforcement learning framework. However, this approach results in inflexibility of agents if options have an extended duration and are dynamic. While adjusting the executed option at each step improves flexibility from a single-agent perspective, frequent changes in options can induce inconsistency between an agent's actual behaviour and its broadcast intention. In order to balance flexibility and predictability, we propose a dynamic termination Bellman equation that allows the agents to flexibly terminate their options. We evaluate our model empirically on a set of multi-agent pursuit and taxi tasks, and show that our agents learn to adapt flexibly across scenarios that require different termination behaviours.
Efficient State-Space Inference of Periodic Latent Force Models
May 29, 2014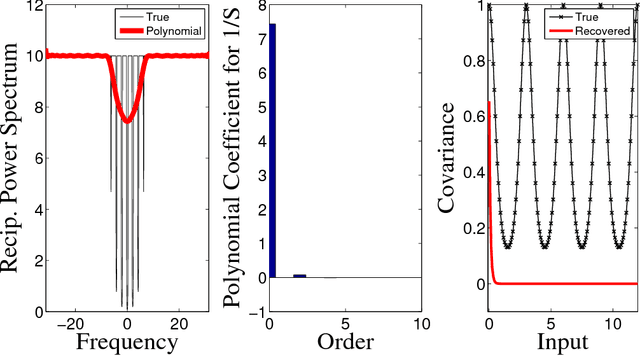

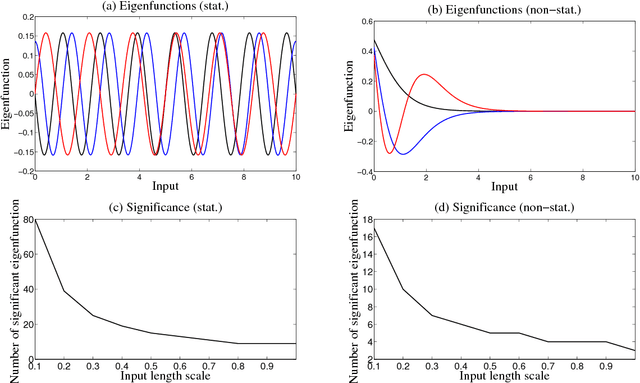
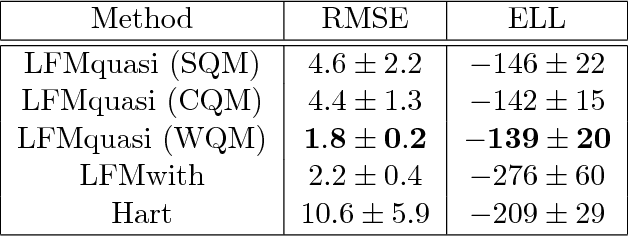
Latent force models (LFM) are principled approaches to incorporating solutions to differential equations within non-parametric inference methods. Unfortunately, the development and application of LFMs can be inhibited by their computational cost, especially when closed-form solutions for the LFM are unavailable, as is the case in many real world problems where these latent forces exhibit periodic behaviour. Given this, we develop a new sparse representation of LFMs which considerably improves their computational efficiency, as well as broadening their applicability, in a principled way, to domains with periodic or near periodic latent forces. Our approach uses a linear basis model to approximate one generative model for each periodic force. We assume that the latent forces are generated from Gaussian process priors and develop a linear basis model which fully expresses these priors. We apply our approach to model the thermal dynamics of domestic buildings and show that it is effective at predicting day-ahead temperatures within the homes. We also apply our approach within queueing theory in which quasi-periodic arrival rates are modelled as latent forces. In both cases, we demonstrate that our approach can be implemented efficiently using state-space methods which encode the linear dynamic systems via LFMs. Further, we show that state estimates obtained using periodic latent force models can reduce the root mean squared error to 17% of that from non-periodic models and 27% of the nearest rival approach which is the resonator model.
Learning Periodic Human Behaviour Models from Sparse Data for Crowdsourcing Aid Delivery in Developing Countries
Sep 26, 2013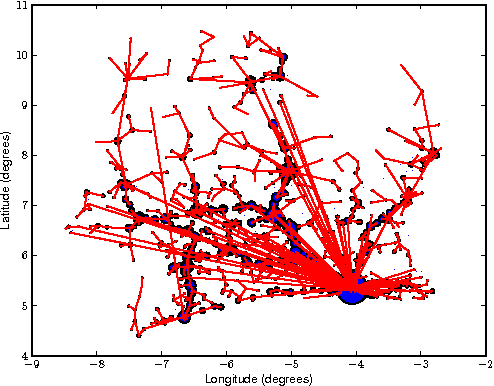
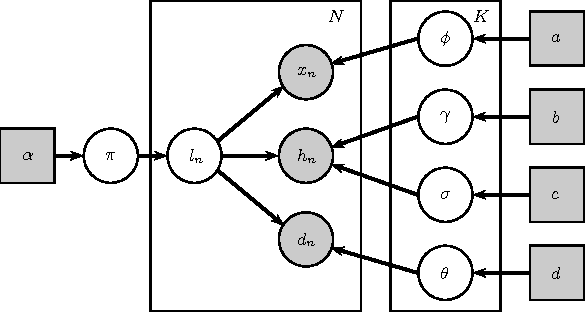

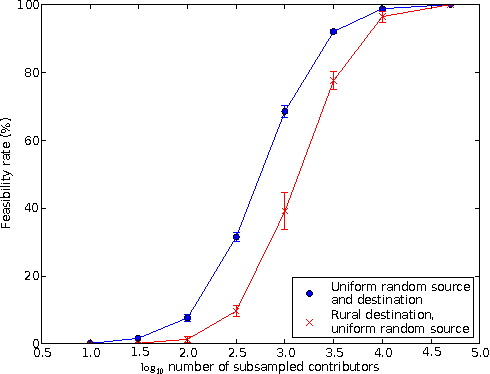
In many developing countries, half the population lives in rural locations, where access to essentials such as school materials, mosquito nets, and medical supplies is restricted. We propose an alternative method of distribution (to standard road delivery) in which the existing mobility habits of a local population are leveraged to deliver aid, which raises two technical challenges in the areas optimisation and learning. For optimisation, a standard Markov decision process applied to this problem is intractable, so we provide an exact formulation that takes advantage of the periodicities in human location behaviour. To learn such behaviour models from sparse data (i.e., cell tower observations), we develop a Bayesian model of human mobility. Using real cell tower data of the mobility behaviour of 50,000 individuals in Ivory Coast, we find that our model outperforms the state of the art approaches in mobility prediction by at least 25% (in held-out data likelihood). Furthermore, when incorporating mobility prediction with our MDP approach, we find a 81.3% reduction in total delivery time versus routine planning that minimises just the number of participants in the solution path.
Knapsack based Optimal Policies for Budget-Limited Multi-Armed Bandits
Apr 09, 2012
In budget-limited multi-armed bandit (MAB) problems, the learner's actions are costly and constrained by a fixed budget. Consequently, an optimal exploitation policy may not be to pull the optimal arm repeatedly, as is the case in other variants of MAB, but rather to pull the sequence of different arms that maximises the agent's total reward within the budget. This difference from existing MABs means that new approaches to maximising the total reward are required. Given this, we develop two pulling policies, namely: (i) KUBE; and (ii) fractional KUBE. Whereas the former provides better performance up to 40% in our experimental settings, the latter is computationally less expensive. We also prove logarithmic upper bounds for the regret of both policies, and show that these bounds are asymptotically optimal (i.e. they only differ from the best possible regret by a constant factor).