 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Agent Planning for Security and Autonomy
Feb 11, 2026Indirect prompt injection attacks threaten AI agents that execute consequential actions, motivating deterministic system-level defenses. Such defenses can provably block unsafe actions by enforcing confidentiality and integrity policies, but currently appear costly: they reduce task completion rates and increase token usage compared to probabilistic defenses. We argue that existing evaluations miss a key benefit of system-level defenses: reduced reliance on human oversight. We introduce autonomy metrics to quantify this benefit: the fraction of consequential actions an agent can execute without human-in-the-loop (HITL) approval while preserving security. To increase autonomy, we design a security-aware agent that (i) introduces richer HITL interactions, and (ii) explicitly plans for both task progress and policy compliance. We implement this agent design atop an existing information-flow control defense against prompt injection and evaluate it on the AgentDojo and WASP benchmarks. Experiments show that this approach yields higher autonomy without sacrificing utility.
Securing AI Agents with Information-Flow Control
May 29, 2025As AI agents become increasingly autonomous and capable, ensuring their security against vulnerabilities such as prompt injection becomes critical. This paper explores the use of information-flow control (IFC) to provide security guarantees for AI agents. We present a formal model to reason about the security and expressiveness of agent planners. Using this model, we characterize the class of properties enforceable by dynamic taint-tracking and construct a taxonomy of tasks to evaluate security and utility trade-offs of planner designs. Informed by this exploration, we present Fides, a planner that tracks confidentiality and integrity labels, deterministically enforces security policies, and introduces novel primitives for selectively hiding information. Its evaluation in AgentDojo demonstrates that this approach broadens the range of tasks that can be securely accomplished. A tutorial to walk readers through the the concepts introduced in the paper can be found at https://github.com/microsoft/fides
The Canary's Echo: Auditing Privacy Risks of LLM-Generated Synthetic Text
Feb 19, 2025



How much information about training samples can be gleaned from synthetic data generated by Large Language Models (LLMs)? Overlooking the subtleties of information flow in synthetic data generation pipelines can lead to a false sense of privacy. In this paper, we design membership inference attacks (MIAs) that target data used to fine-tune pre-trained LLMs that are then used to synthesize data, particularly when the adversary does not have access to the fine-tuned model but only to the synthetic data. We show that such data-based MIAs do significantly better than a random guess, meaning that synthetic data leaks information about the training data. Further, we find that canaries crafted to maximize vulnerability to model-based MIAs are sub-optimal for privacy auditing when only synthetic data is released. Such out-of-distribution canaries have limited influence on the model's output when prompted to generate useful, in-distribution synthetic data, which drastically reduces their vulnerability. To tackle this problem, we leverage the mechanics of auto-regressive models to design canaries with an in-distribution prefix and a high-perplexity suffix that leave detectable traces in synthetic data. This enhances the power of data-based MIAs and provides a better assessment of the privacy risks of releasing synthetic data generated by LLMs.
Permissive Information-Flow Analysis for Large Language Models
Oct 04, 2024



Large Language Models (LLMs) are rapidly becoming commodity components of larger software systems. This poses natural security and privacy problems: poisoned data retrieved from one component can change the model's behavior and compromise the entire system, including coercing the model to spread confidential data to untrusted components. One promising approach is to tackle this problem at the system level via dynamic information flow (aka taint) tracking. Unfortunately, the traditional approach of propagating the most restrictive input label to the output is too conservative for applications where LLMs operate on inputs retrieved from diverse sources. In this paper, we propose a novel, more permissive approach to propagate information flow labels through LLM queries. The key idea behind our approach is to propagate only the labels of the samples that were influential in generating the model output and to eliminate the labels of unnecessary input. We implement and investigate the effectiveness of two variations of this approach, based on (i) prompt-based retrieval augmentation, and (ii) a $k$-nearest-neighbors language model. We compare these with the baseline of an introspection-based influence estimator that directly asks the language model to predict the output label. The results obtained highlight the superiority of our prompt-based label propagator, which improves the label in more than 85% of the cases in an LLM agent setting. These findings underscore the practicality of permissive label propagation for retrieval augmentation.
Closed-Form Bounds for DP-SGD against Record-level Inference
Feb 22, 2024



Machine learning models trained with differentially-private (DP) algorithms such as DP-SGD enjoy resilience against a wide range of privacy attacks. Although it is possible to derive bounds for some attacks based solely on an $(\varepsilon,\delta)$-DP guarantee, meaningful bounds require a small enough privacy budget (i.e., injecting a large amount of noise), which results in a large loss in utility. This paper presents a new approach to evaluate the privacy of machine learning models against specific record-level threats, such as membership and attribute inference, without the indirection through DP. We focus on the popular DP-SGD algorithm, and derive simple closed-form bounds. Our proofs model DP-SGD as an information theoretic channel whose inputs are the secrets that an attacker wants to infer (e.g., membership of a data record) and whose outputs are the intermediate model parameters produced by iterative optimization. We obtain bounds for membership inference that match state-of-the-art techniques, whilst being orders of magnitude faster to compute. Additionally, we present a novel data-dependent bound against attribute inference. Our results provide a direct, interpretable, and practical way to evaluate the privacy of trained models against specific inference threats without sacrificing utility.
Rethinking Privacy in Machine Learning Pipelines from an Information Flow Control Perspective
Nov 27, 2023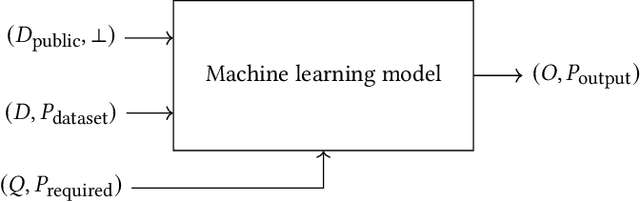
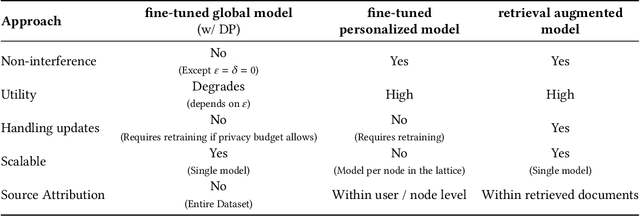
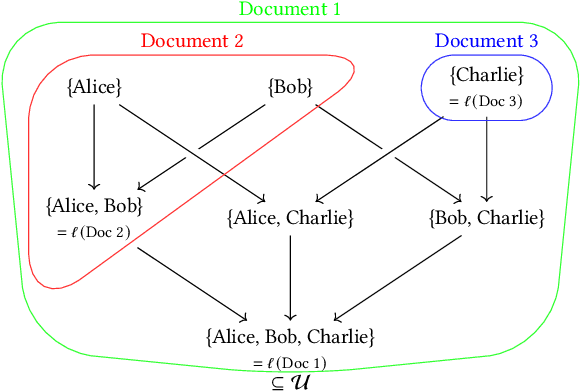
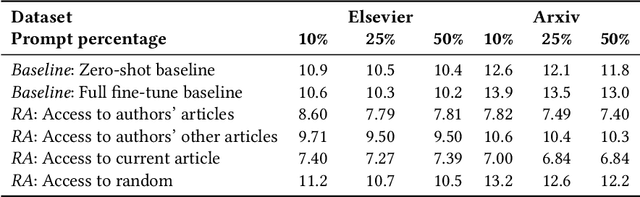
Modern machine learning systems use models trained on ever-growing corpora. Typically, metadata such as ownership, access control, or licensing information is ignored during training. Instead, to mitigate privacy risks, we rely on generic techniques such as dataset sanitization and differentially private model training, with inherent privacy/utility trade-offs that hurt model performance. Moreover, these techniques have limitations in scenarios where sensitive information is shared across multiple participants and fine-grained access control is required. By ignoring metadata, we therefore miss an opportunity to better address security, privacy, and confidentiality challenges. In this paper, we take an information flow control perspective to describe machine learning systems, which allows us to leverage metadata such as access control policies and define clear-cut privacy and confidentiality guarantees with interpretable information flows. Under this perspective, we contrast two different approaches to achieve user-level non-interference: 1) fine-tuning per-user models, and 2) retrieval augmented models that access user-specific datasets at inference time. We compare these two approaches to a trivially non-interfering zero-shot baseline using a public model and to a baseline that fine-tunes this model on the whole corpus. We evaluate trained models on two datasets of scientific articles and demonstrate that retrieval augmented architectures deliver the best utility, scalability, and flexibility while satisfying strict non-interference guarantees.
SoK: Memorization in General-Purpose Large Language Models
Oct 24, 2023
Large Language Models (LLMs) are advancing at a remarkable pace, with myriad applications under development. Unlike most earlier machine learning models, they are no longer built for one specific application but are designed to excel in a wide range of tasks. A major part of this success is due to their huge training datasets and the unprecedented number of model parameters, which allow them to memorize large amounts of information contained in the training data. This memorization goes beyond mere language, and encompasses information only present in a few documents. This is often desirable since it is necessary for performing tasks such as question answering, and therefore an important part of learning, but also brings a whole array of issues, from privacy and security to copyright and beyond. LLMs can memorize short secrets in the training data, but can also memorize concepts like facts or writing styles that can be expressed in text in many different ways. We propose a taxonomy for memorization in LLMs that covers verbatim text, facts, ideas and algorithms, writing styles, distributional properties, and alignment goals. We describe the implications of each type of memorization - both positive and negative - for model performance, privacy, security and confidentiality, copyright, and auditing, and ways to detect and prevent memorization. We further highlight the challenges that arise from the predominant way of defining memorization with respect to model behavior instead of model weights, due to LLM-specific phenomena such as reasoning capabilities or differences between decoding algorithms. Throughout the paper, we describe potential risks and opportunities arising from memorization in LLMs that we hope will motivate new research directions.
Why Train More? Effective and Efficient Membership Inference via Memorization
Oct 12, 2023
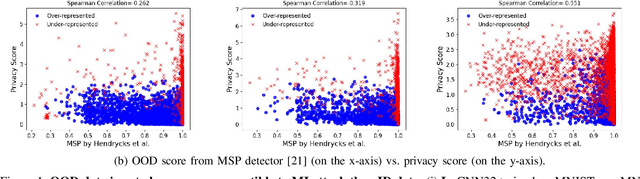
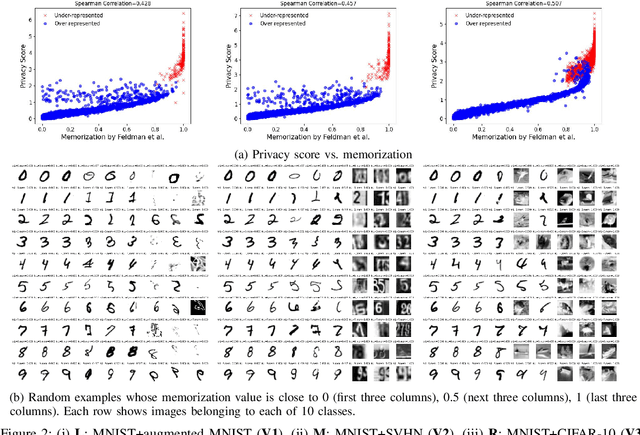
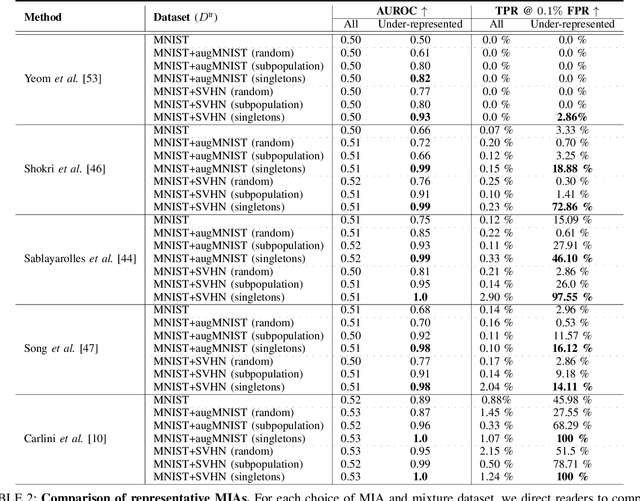
Membership Inference Attacks (MIAs) aim to identify specific data samples within the private training dataset of machine learning models, leading to serious privacy violations and other sophisticated threats. Many practical black-box MIAs require query access to the data distribution (the same distribution where the private data is drawn) to train shadow models. By doing so, the adversary obtains models trained "with" or "without" samples drawn from the distribution, and analyzes the characteristics of the samples under consideration. The adversary is often required to train more than hundreds of shadow models to extract the signals needed for MIAs; this becomes the computational overhead of MIAs. In this paper, we propose that by strategically choosing the samples, MI adversaries can maximize their attack success while minimizing the number of shadow models. First, our motivational experiments suggest memorization as the key property explaining disparate sample vulnerability to MIAs. We formalize this through a theoretical bound that connects MI advantage with memorization. Second, we show sample complexity bounds that connect the number of shadow models needed for MIAs with memorization. Lastly, we confirm our theoretical arguments with comprehensive experiments; by utilizing samples with high memorization scores, the adversary can (a) significantly improve its efficacy regardless of the MIA used, and (b) reduce the number of shadow models by nearly two orders of magnitude compared to state-of-the-art approaches.
Re-aligning Shadow Models can Improve White-box Membership Inference Attacks
Jun 08, 2023



Machine learning models have been shown to leak sensitive information about their training datasets. As models are being increasingly used, on devices, to automate tasks and power new applications, there have been concerns that such white-box access to its parameters, as opposed to the black-box setting which only provides query access to the model, increases the attack surface. Directly extending the shadow modelling technique from the black-box to the white-box setting has been shown, in general, not to perform better than black-box only attacks. A key reason is misalignment, a known characteristic of deep neural networks. We here present the first systematic analysis of the causes of misalignment in shadow models and show the use of a different weight initialisation to be the main cause of shadow model misalignment. Second, we extend several re-alignment techniques, previously developed in the model fusion literature, to the shadow modelling context, where the goal is to re-align the layers of a shadow model to those of the target model.We show re-alignment techniques to significantly reduce the measured misalignment between the target and shadow models. Finally, we perform a comprehensive evaluation of white-box membership inference attacks (MIA). Our analysis reveals that (1) MIAs suffer from misalignment between shadow models, but that (2) re-aligning the shadow models improves, sometimes significantly, MIA performance. On the CIFAR10 dataset with a false positive rate of 1\%, white-box MIA using re-aligned shadow models improves the true positive rate by 4.5\%.Taken together, our results highlight that on-device deployment increase the attack surface and that the newly available information can be used by an attacker.
On the Efficacy of Differentially Private Few-shot Image Classification
Feb 02, 2023There has been significant recent progress in training differentially private (DP) models which achieve accuracy that approaches the best non-private models. These DP models are typically pretrained on large public datasets and then fine-tuned on downstream datasets that are (i) relatively large, and (ii) similar in distribution to the pretraining data. However, in many applications including personalization, it is crucial to perform well in the few-shot setting, as obtaining large amounts of labeled data may be problematic; and on images from a wide variety of domains for use in various specialist settings. To understand under which conditions few-shot DP can be effective, we perform an exhaustive set of experiments that reveals how the accuracy and vulnerability to attack of few-shot DP image classification models are affected as the number of shots per class, privacy level, model architecture, dataset, and subset of learnable parameters in the model vary. We show that to achieve DP accuracy on par with non-private models, the shots per class must be increased as the privacy level increases by as much as 32$\times$ for CIFAR-100 at $\epsilon=1$. We also find that few-shot non-private models are highly susceptible to membership inference attacks. DP provides clear mitigation against the attacks, but a small $\epsilon$ is required to effectively prevent them. Finally, we evaluate DP federated learning systems and establish state-of-the-art performance on the challenging FLAIR federated learning benchmark.