 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaudini: Autoresearch Discovers State-of-the-Art Adversarial Attack Algorithms for LLMs
Mar 25, 2026LLM agents like Claude Code can not only write code but also be used for autonomous AI research and engineering \citep{rank2026posttrainbench, novikov2025alphaevolve}. We show that an \emph{autoresearch}-style pipeline \citep{karpathy2026autoresearch} powered by Claude Code discovers novel white-box adversarial attack \textit{algorithms} that \textbf{significantly outperform all existing (30+) methods} in jailbreaking and prompt injection evaluations. Starting from existing attack implementations, such as GCG~\citep{zou2023universal}, the agent iterates to produce new algorithms achieving up to 40\% attack success rate on CBRN queries against GPT-OSS-Safeguard-20B, compared to $\leq$10\% for existing algorithms (\Cref{fig:teaser}, left). The discovered algorithms generalize: attacks optimized on surrogate models transfer directly to held-out models, achieving \textbf{100\% ASR against Meta-SecAlign-70B} \citep{chen2025secalign} versus 56\% for the best baseline (\Cref{fig:teaser}, middle). Extending the findings of~\cite{carlini2025autoadvexbench}, our results are an early demonstration that incremental safety and security research can be automated using LLM agents. White-box adversarial red-teaming is particularly well-suited for this: existing methods provide strong starting points, and the optimization objective yields dense, quantitative feedback. We release all discovered attacks alongside baseline implementations and evaluation code at https://github.com/romovpa/claudini.
RAT-Bench: A Comprehensive Benchmark for Text Anonymization
Feb 13, 2026Data containing personal information is increasingly used to train, fine-tune, or query Large Language Models (LLMs). Text is typically scrubbed of identifying information prior to use, often with tools such as Microsoft's Presidio or Anthropic's PII purifier. These tools have traditionally been evaluated on their ability to remove specific identifiers (e.g., names), yet their effectiveness at preventing re-identification remains unclear. We introduce RAT-Bench, a comprehensive benchmark for text anonymization tools based on re-identification risk. Using U.S. demographic statistics, we generate synthetic text containing various direct and indirect identifiers across domains, languages, and difficulty levels. We evaluate a range of NER- and LLM-based text anonymization tools and, based on the attributes an LLM-based attacker is able to correctly infer from the anonymized text, we report the risk of re-identification in the U.S. population, while properly accounting for the disparate impact of identifiers. We find that, while capabilities vary widely, even the best tools are far from perfect in particular when direct identifiers are not written in standard ways and when indirect identifiers enable re-identification. Overall we find LLM-based anonymizers, including new iterative anonymizers, to provide a better privacy-utility trade-off albeit at a higher computational cost. Importantly, we also find them to work well across languages. We conclude with recommendations for future anonymization tools and will release the benchmark and encourage community efforts to expand it, in particular to other geographies.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Alignment Under Pressure: The Case for Informed Adversaries When Evaluating LLM Defenses
May 21, 2025
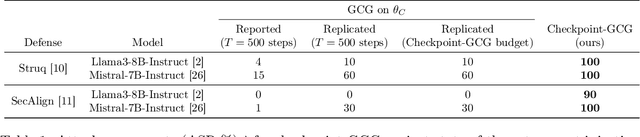
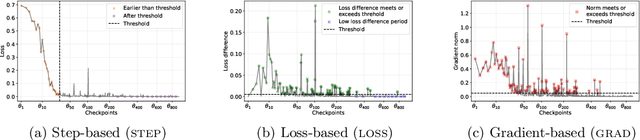

Large language models (LLMs) are rapidly deployed in real-world applications ranging from chatbots to agentic systems. Alignment is one of the main approaches used to defend against attacks such as prompt injection and jailbreaks. Recent defenses report near-zero Attack Success Rates (ASR) even against Greedy Coordinate Gradient (GCG), a white-box attack that generates adversarial suffixes to induce attacker-desired outputs. However, this search space over discrete tokens is extremely large, making the task of finding successful attacks difficult. GCG has, for instance, been shown to converge to local minima, making it sensitive to initialization choices. In this paper, we assess the future-proof robustness of these defenses using a more informed threat model: attackers who have access to some information about the alignment process. Specifically, we propose an informed white-box attack leveraging the intermediate model checkpoints to initialize GCG, with each checkpoint acting as a stepping stone for the next one. We show this approach to be highly effective across state-of-the-art (SOTA) defenses and models. We further show our informed initialization to outperform other initialization methods and show a gradient-informed checkpoint selection strategy to greatly improve attack performance and efficiency. Importantly, we also show our method to successfully find universal adversarial suffixes -- single suffixes effective across diverse inputs. Our results show that, contrary to previous beliefs, effective adversarial suffixes do exist against SOTA alignment-based defenses, that these can be found by existing attack methods when adversaries exploit alignment knowledge, and that even universal suffixes exist. Taken together, our results highlight the brittleness of current alignment-based methods and the need to consider stronger threat models when testing the safety of LLMs.
The DCR Delusion: Measuring the Privacy Risk of Synthetic Data
May 02, 2025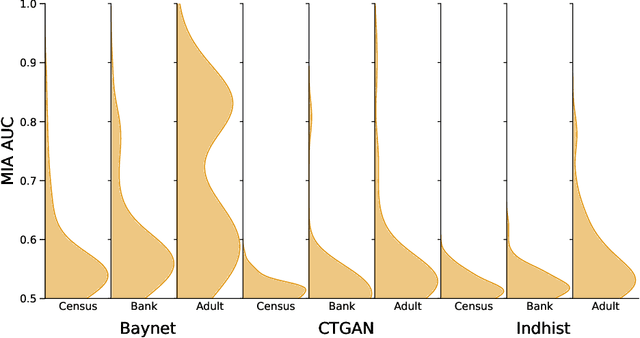

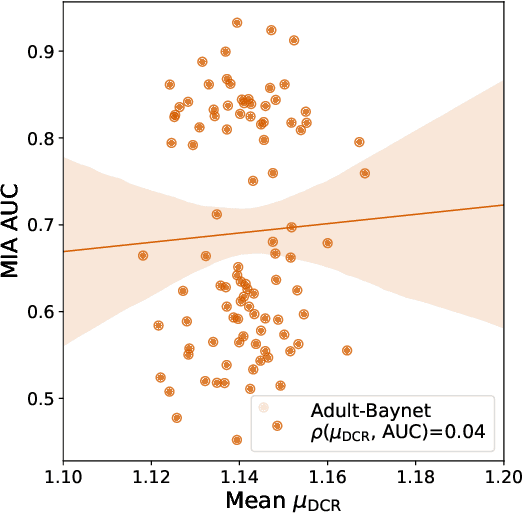
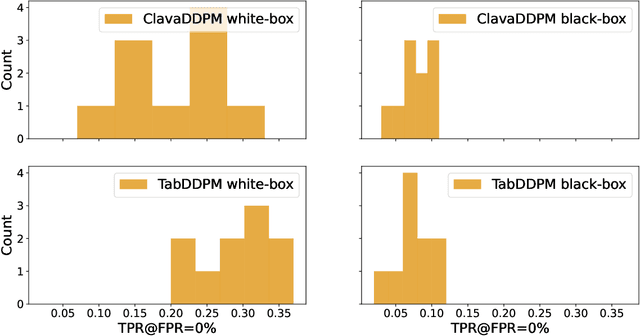
Synthetic data has become an increasingly popular way to share data without revealing sensitive information. Though Membership Inference Attacks (MIAs) are widely considered the gold standard for empirically assessing the privacy of a synthetic dataset, practitioners and researchers often rely on simpler proxy metrics such as Distance to Closest Record (DCR). These metrics estimate privacy by measuring the similarity between the training data and generated synthetic data. This similarity is also compared against that between the training data and a disjoint holdout set of real records to construct a binary privacy test. If the synthetic data is not more similar to the training data than the holdout set is, it passes the test and is considered private. In this work we show that, while computationally inexpensive, DCR and other distance-based metrics fail to identify privacy leakage. Across multiple datasets and both classical models such as Baynet and CTGAN and more recent diffusion models, we show that datasets deemed private by proxy metrics are highly vulnerable to MIAs. We similarly find both the binary privacy test and the continuous measure based on these metrics to be uninformative of actual membership inference risk. We further show that these failures are consistent across different metric hyperparameter settings and record selection methods. Finally, we argue DCR and other distance-based metrics to be flawed by design and show a example of a simple leakage they miss in practice. With this work, we hope to motivate practitioners to move away from proxy metrics to MIAs as the rigorous, comprehensive standard of evaluating privacy of synthetic data, in particular to make claims of datasets being legally anonymous.
DeSIA: Attribute Inference Attacks Against Limited Fixed Aggregate Statistics
Apr 25, 2025Empirical inference attacks are a popular approach for evaluating the privacy risk of data release mechanisms in practice. While an active attack literature exists to evaluate machine learning models or synthetic data release, we currently lack comparable methods for fixed aggregate statistics, in particular when only a limited number of statistics are released. We here propose an inference attack framework against fixed aggregate statistics and an attribute inference attack called DeSIA. We instantiate DeSIA against the U.S. Census PPMF dataset and show it to strongly outperform reconstruction-based attacks. In particular, we show DeSIA to be highly effective at identifying vulnerable users, achieving a true positive rate of 0.14 at a false positive rate of $10^{-3}$. We then show DeSIA to perform well against users whose attributes cannot be verified and when varying the number of aggregate statistics and level of noise addition. We also perform an extensive ablation study of DeSIA and show how DeSIA can be successfully adapted to the membership inference task. Overall, our results show that aggregation alone is not sufficient to protect privacy, even when a relatively small number of aggregates are being released, and emphasize the need for formal privacy mechanisms and testing before aggregate statistics are released.
Watermarking Training Data of Music Generation Models
Dec 12, 2024



Generative Artificial Intelligence (Gen-AI) models are increasingly used to produce content across domains, including text, images, and audio. While these models represent a major technical breakthrough, they gain their generative capabilities from being trained on enormous amounts of human-generated content, which often includes copyrighted material. In this work, we investigate whether audio watermarking techniques can be used to detect an unauthorized usage of content to train a music generation model. We compare outputs generated by a model trained on watermarked data to a model trained on non-watermarked data. We study factors that impact the model's generation behaviour: the watermarking technique, the proportion of watermarked samples in the training set, and the robustness of the watermarking technique against the model's tokenizer. Our results show that audio watermarking techniques, including some that are imperceptible to humans, can lead to noticeable shifts in the model's outputs. We also study the robustness of a state-of-the-art watermarking technique to removal techniques.
Free Record-Level Privacy Risk Evaluation Through Artifact-Based Methods
Nov 08, 2024

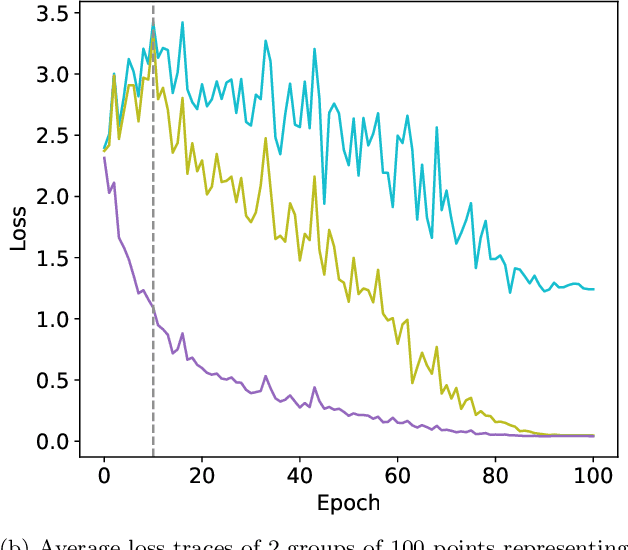

Membership inference attacks (MIAs) are widely used to empirically assess the privacy risks of samples used to train a target machine learning model. State-of-the-art methods however require training hundreds of shadow models, with the same size and architecture of the target model, solely to evaluate the privacy risk. While one might be able to afford this for small models, the cost often becomes prohibitive for medium and large models. We here instead propose a novel approach to identify the at-risk samples using only artifacts available during training, with little to no additional computational overhead. Our method analyzes individual per-sample loss traces and uses them to identify the vulnerable data samples. We demonstrate the effectiveness of our artifact-based approach through experiments on the CIFAR10 dataset, showing high precision in identifying vulnerable samples as determined by a SOTA shadow model-based MIA (LiRA). Impressively, our method reaches the same precision as another SOTA MIA when measured against LiRA, despite it being orders of magnitude cheaper. We then show LT-IQR to outperform alternative loss aggregation methods, perform ablation studies on hyperparameters, and validate the robustness of our method to the target metric. Finally, we study the evolution of the vulnerability score distribution throughout training as a metric for model-level risk assessment.
QueryCheetah: Fast Automated Discovery of Attribute Inference Attacks Against Query-Based Systems
Sep 03, 2024



Query-based systems (QBSs) are one of the key approaches for sharing data. QBSs allow analysts to request aggregate information from a private protected dataset. Attacks are a crucial part of ensuring QBSs are truly privacy-preserving. The development and testing of attacks is however very labor-intensive and unable to cope with the increasing complexity of systems. Automated approaches have been shown to be promising but are currently extremely computationally intensive, limiting their applicability in practice. We here propose QueryCheetah, a fast and effective method for automated discovery of privacy attacks against QBSs. We instantiate QueryCheetah on attribute inference attacks and show it to discover stronger attacks than previous methods while being 18 times faster than the state-of-the-art automated approach. We then show how QueryCheetah allows system developers to thoroughly evaluate the privacy risk, including for various attacker strengths and target individuals. We finally show how QueryCheetah can be used out-of-the-box to find attacks in larger syntaxes and workarounds around ad-hoc defenses.
A Zero Auxiliary Knowledge Membership Inference Attack on Aggregate Location Data
Jun 26, 2024

Location data is frequently collected from populations and shared in aggregate form to guide policy and decision making. However, the prevalence of aggregated data also raises the privacy concern of membership inference attacks (MIAs). MIAs infer whether an individual's data contributed to the aggregate release. Although effective MIAs have been developed for aggregate location data, these require access to an extensive auxiliary dataset of individual traces over the same locations, which are collected from a similar population. This assumption is often impractical given common privacy practices surrounding location data. To measure the risk of an MIA performed by a realistic adversary, we develop the first Zero Auxiliary Knowledge (ZK) MIA on aggregate location data, which eliminates the need for an auxiliary dataset of real individual traces. Instead, we develop a novel synthetic approach, such that suitable synthetic traces are generated from the released aggregate. We also develop methods to correct for bias and noise, to show that our synthetic-based attack is still applicable when privacy mechanisms are applied prior to release. Using two large-scale location datasets, we demonstrate that our ZK MIA matches the state-of-the-art Knock-Knock (KK) MIA across a wide range of settings, including popular implementations of differential privacy (DP) and suppression of small counts. Furthermore, we show that ZK MIA remains highly effective even when the adversary only knows a small fraction (10%) of their target's location history. This demonstrates that effective MIAs can be performed by realistic adversaries, highlighting the need for strong DP protection.