 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Record-Level Privacy Risk Evaluation Through Artifact-Based Methods
Paper and Code


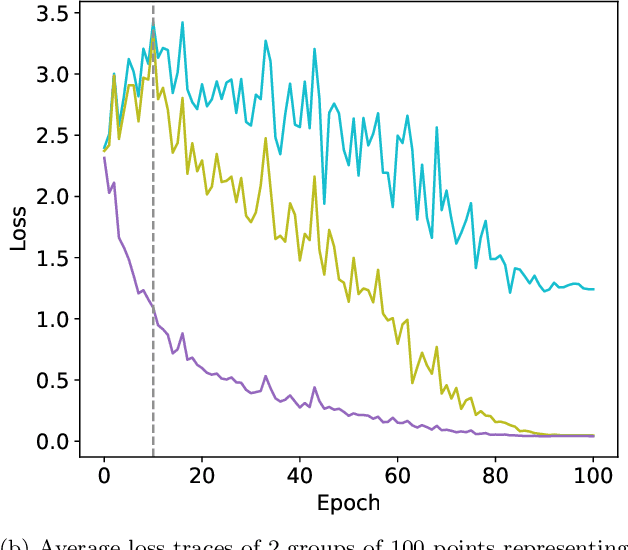

Membership inference attacks (MIAs) are widely used to empirically assess the privacy risks of samples used to train a target machine learning model. State-of-the-art methods however require training hundreds of shadow models, with the same size and architecture of the target model, solely to evaluate the privacy risk. While one might be able to afford this for small models, the cost often becomes prohibitive for medium and large models. We here instead propose a novel approach to identify the at-risk samples using only artifacts available during training, with little to no additional computational overhead. Our method analyzes individual per-sample loss traces and uses them to identify the vulnerable data samples. We demonstrate the effectiveness of our artifact-based approach through experiments on the CIFAR10 dataset, showing high precision in identifying vulnerable samples as determined by a SOTA shadow model-based MIA (LiRA). Impressively, our method reaches the same precision as another SOTA MIA when measured against LiRA, despite it being orders of magnitude cheaper. We then show LT-IQR to outperform alternative loss aggregation methods, perform ablation studies on hyperparameters, and validate the robustness of our method to the target metric. Finally, we study the evolution of the vulnerability score distribution throughout training as a metric for model-level risk assessment.