 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaudini: Autoresearch Discovers State-of-the-Art Adversarial Attack Algorithms for LLMs
Mar 25, 2026LLM agents like Claude Code can not only write code but also be used for autonomous AI research and engineering \citep{rank2026posttrainbench, novikov2025alphaevolve}. We show that an \emph{autoresearch}-style pipeline \citep{karpathy2026autoresearch} powered by Claude Code discovers novel white-box adversarial attack \textit{algorithms} that \textbf{significantly outperform all existing (30+) methods} in jailbreaking and prompt injection evaluations. Starting from existing attack implementations, such as GCG~\citep{zou2023universal}, the agent iterates to produce new algorithms achieving up to 40\% attack success rate on CBRN queries against GPT-OSS-Safeguard-20B, compared to $\leq$10\% for existing algorithms (\Cref{fig:teaser}, left). The discovered algorithms generalize: attacks optimized on surrogate models transfer directly to held-out models, achieving \textbf{100\% ASR against Meta-SecAlign-70B} \citep{chen2025secalign} versus 56\% for the best baseline (\Cref{fig:teaser}, middle). Extending the findings of~\cite{carlini2025autoadvexbench}, our results are an early demonstration that incremental safety and security research can be automated using LLM agents. White-box adversarial red-teaming is particularly well-suited for this: existing methods provide strong starting points, and the optimization objective yields dense, quantitative feedback. We release all discovered attacks alongside baseline implementations and evaluation code at https://github.com/romovpa/claudini.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
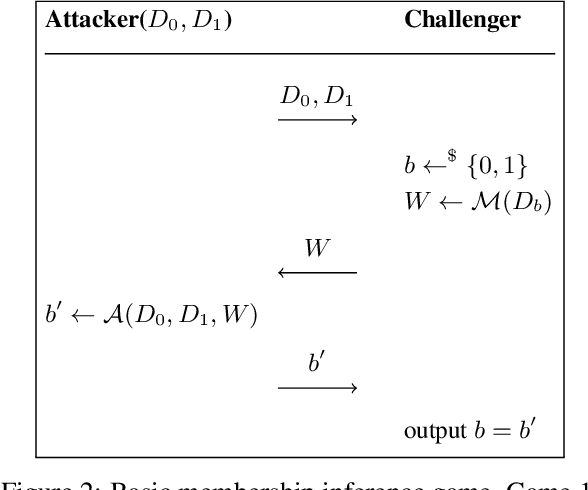
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Watermarking Training Data of Music Generation Models
Dec 12, 2024



Generative Artificial Intelligence (Gen-AI) models are increasingly used to produce content across domains, including text, images, and audio. While these models represent a major technical breakthrough, they gain their generative capabilities from being trained on enormous amounts of human-generated content, which often includes copyrighted material. In this work, we investigate whether audio watermarking techniques can be used to detect an unauthorized usage of content to train a music generation model. We compare outputs generated by a model trained on watermarked data to a model trained on non-watermarked data. We study factors that impact the model's generation behaviour: the watermarking technique, the proportion of watermarked samples in the training set, and the robustness of the watermarking technique against the model's tokenizer. Our results show that audio watermarking techniques, including some that are imperceptible to humans, can lead to noticeable shifts in the model's outputs. We also study the robustness of a state-of-the-art watermarking technique to removal techniques.
Free Record-Level Privacy Risk Evaluation Through Artifact-Based Methods
Nov 08, 2024

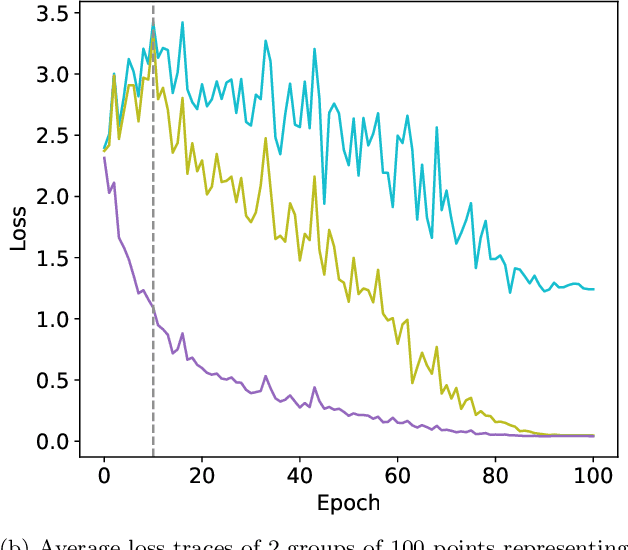

Membership inference attacks (MIAs) are widely used to empirically assess the privacy risks of samples used to train a target machine learning model. State-of-the-art methods however require training hundreds of shadow models, with the same size and architecture of the target model, solely to evaluate the privacy risk. While one might be able to afford this for small models, the cost often becomes prohibitive for medium and large models. We here instead propose a novel approach to identify the at-risk samples using only artifacts available during training, with little to no additional computational overhead. Our method analyzes individual per-sample loss traces and uses them to identify the vulnerable data samples. We demonstrate the effectiveness of our artifact-based approach through experiments on the CIFAR10 dataset, showing high precision in identifying vulnerable samples as determined by a SOTA shadow model-based MIA (LiRA). Impressively, our method reaches the same precision as another SOTA MIA when measured against LiRA, despite it being orders of magnitude cheaper. We then show LT-IQR to outperform alternative loss aggregation methods, perform ablation studies on hyperparameters, and validate the robustness of our method to the target metric. Finally, we study the evolution of the vulnerability score distribution throughout training as a metric for model-level risk assessment.
Mosaic Memory: Fuzzy Duplication in Copyright Traps for Large Language Models
May 24, 2024
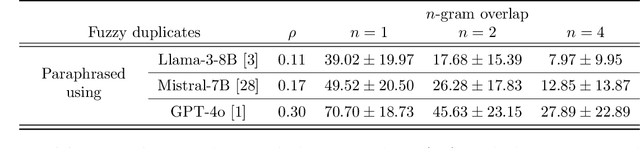
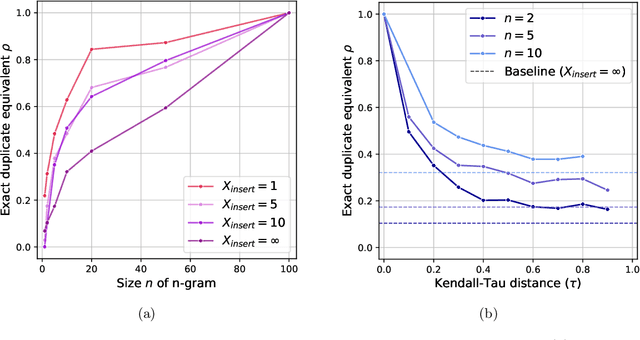
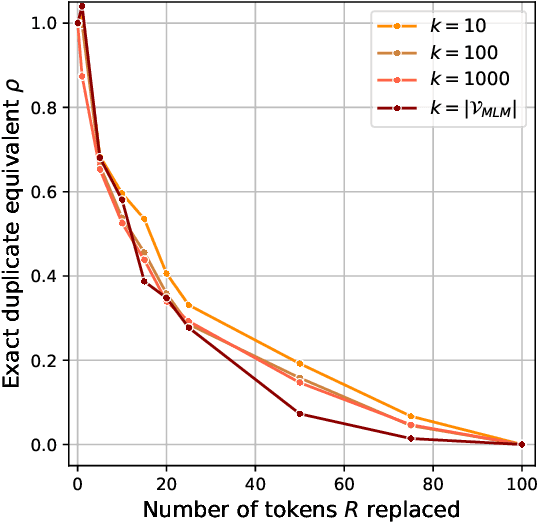
The immense datasets used to develop Large Language Models (LLMs) often include copyright-protected content, typically without the content creator's consent. Copyright traps have been proposed to be injected into the original content, improving content detectability in newly released LLMs. Traps, however, rely on the exact duplication of a unique text sequence, leaving them vulnerable to commonly deployed data deduplication techniques. We here propose the generation of fuzzy copyright traps, featuring slight modifications across duplication. When injected in the fine-tuning data of a 1.3B LLM, we show fuzzy trap sequences to be memorized nearly as well as exact duplicates. Specifically, the Membership Inference Attack (MIA) ROC AUC only drops from 0.90 to 0.87 when 4 tokens are replaced across the fuzzy duplicates. We also find that selecting replacement positions to minimize the exact overlap between fuzzy duplicates leads to similar memorization, while making fuzzy duplicates highly unlikely to be removed by any deduplication process. Lastly, we argue that the fact that LLMs memorize across fuzzy duplicates challenges the study of LLM memorization relying on naturally occurring duplicates. Indeed, we find that the commonly used training dataset, The Pile, contains significant amounts of fuzzy duplicates. This introduces a previously unexplored confounding factor in post-hoc studies of LLM memorization, and questions the effectiveness of (exact) data deduplication as a privacy protection technique.
Copyright Traps for Large Language Models
Feb 14, 2024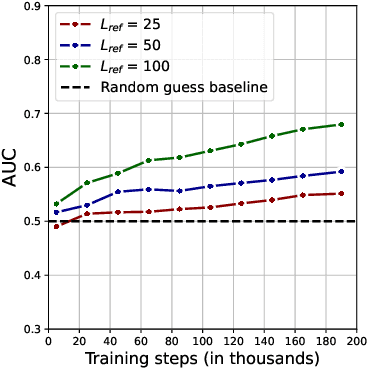
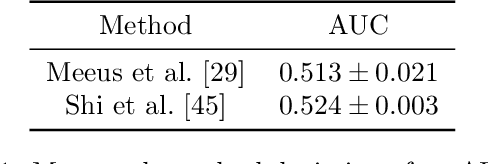
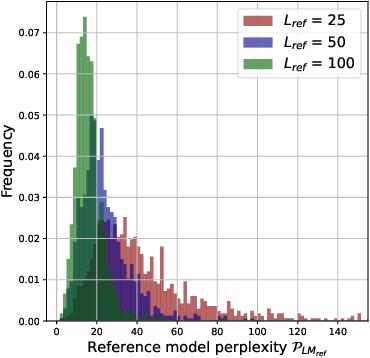
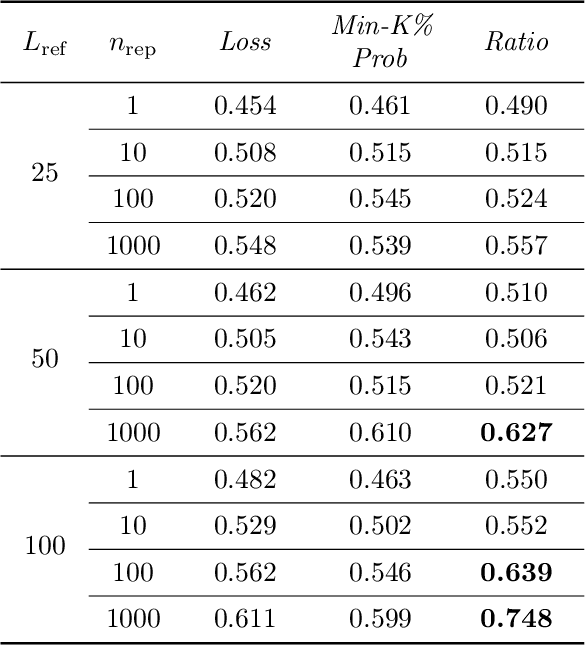
Questions of fair use of copyright-protected content to train Large Language Models (LLMs) are being very actively debated. Document-level inference has been proposed as a new task: inferring from black-box access to the trained model whether a piece of content has been seen during training. SOTA methods however rely on naturally occurring memorization of (part of) the content. While very effective against models that memorize a lot, we hypothesize--and later confirm--that they will not work against models that do not naturally memorize, e.g. medium-size 1B models. We here propose to use copyright traps, the inclusion of fictitious entries in original content, to detect the use of copyrighted materials in LLMs with a focus on models where memorization does not naturally occur. We carefully design an experimental setup, randomly inserting traps into original content (books) and train a 1.3B LLM. We first validate that the use of content in our target model would be undetectable using existing methods. We then show, contrary to intuition, that even medium-length trap sentences repeated a significant number of times (100) are not detectable using existing methods. However, we show that longer sequences repeated a large number of times can be reliably detected (AUC=0.75) and used as copyright traps. We further improve these results by studying how the number of times a sequence is seen improves detectability, how sequences with higher perplexity tend to be memorized more, and how taking context into account further improves detectability.
Defending against Reconstruction Attacks with Rényi Differential Privacy
Feb 15, 2022

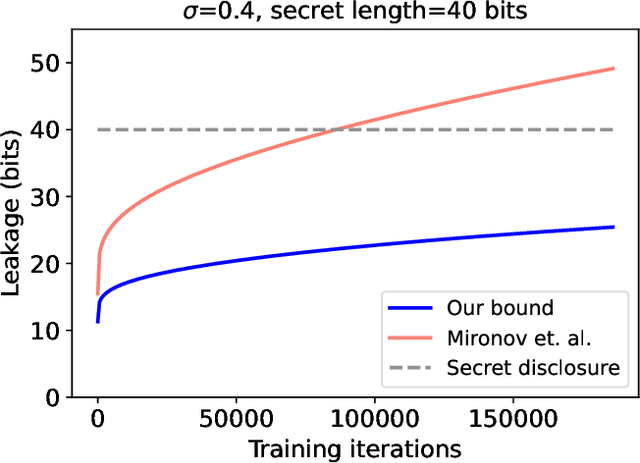
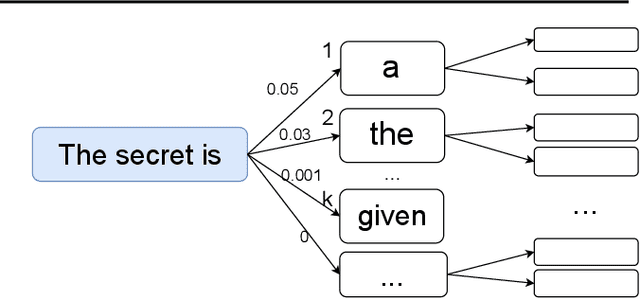
Reconstruction attacks allow an adversary to regenerate data samples of the training set using access to only a trained model. It has been recently shown that simple heuristics can reconstruct data samples from language models, making this threat scenario an important aspect of model release. Differential privacy is a known solution to such attacks, but is often used with a relatively large privacy budget (epsilon > 8) which does not translate to meaningful guarantees. In this paper we show that, for a same mechanism, we can derive privacy guarantees for reconstruction attacks that are better than the traditional ones from the literature. In particular, we show that larger privacy budgets do not protect against membership inference, but can still protect extraction of rare secrets. We show experimentally that our guarantees hold against various language models, including GPT-2 finetuned on Wikitext-103.
Opacus: User-Friendly Differential Privacy Library in PyTorch
Oct 05, 2021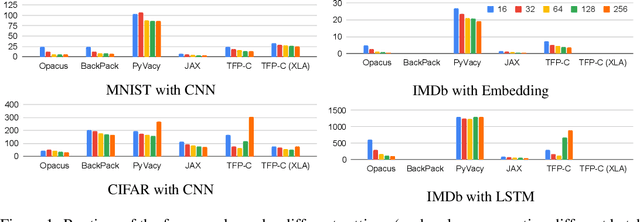
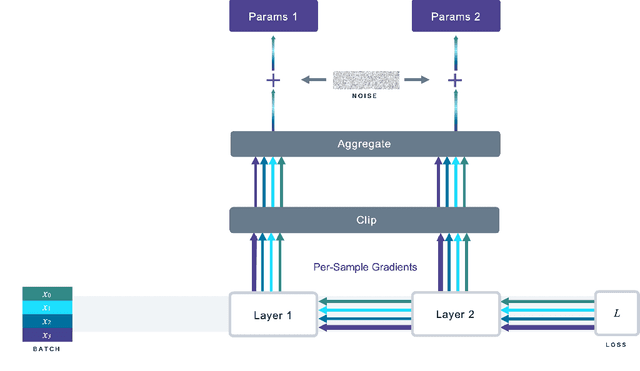
We introduce Opacus, a free, open-source PyTorch library for training deep learning models with differential privacy (hosted at opacus.ai). Opacus is designed for simplicity, flexibility, and speed. It provides a simple and user-friendly API, and enables machine learning practitioners to make a training pipeline private by adding as little as two lines to their code. It supports a wide variety of layers, including multi-head attention, convolution, LSTM, and embedding, right out of the box, and it also provides the means for supporting other user-defined layers. Opacus computes batched per-sample gradients, providing better efficiency compared to the traditional "micro batch" approach. In this paper we present Opacus, detail the principles that drove its implementation and unique features, and compare its performance against other frameworks for differential privacy in ML.
Antipodes of Label Differential Privacy: PATE and ALIBI
Jun 07, 2021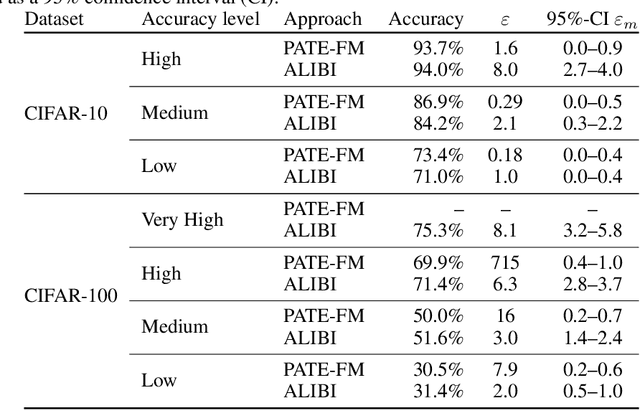
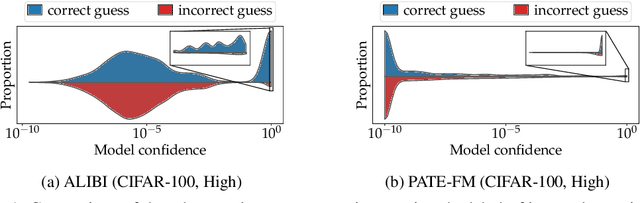
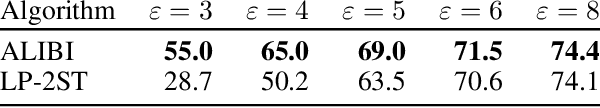
We consider the privacy-preserving machine learning (ML) setting where the trained model must satisfy differential privacy (DP) with respect to the labels of the training examples. We propose two novel approaches based on, respectively, the Laplace mechanism and the PATE framework, and demonstrate their effectiveness on standard benchmarks. While recent work by Ghazi et al. proposed Label DP schemes based on a randomized response mechanism, we argue that additive Laplace noise coupled with Bayesian inference (ALIBI) is a better fit for typical ML tasks. Moreover, we show how to achieve very strong privacy levels in some regimes, with our adaptation of the PATE framework that builds on recent advances in semi-supervised learning. We complement theoretical analysis of our algorithms' privacy guarantees with empirical evaluation of their memorization properties. Our evaluation suggests that comparing different algorithms according to their provable DP guarantees can be misleading and favor a less private algorithm with a tighter analysis.