 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
Flowception: Temporally Expansive Flow Matching for Video Generation
Dec 12, 2025We present Flowception, a novel non-autoregressive and variable-length video generation framework. Flowception learns a probability path that interleaves discrete frame insertions with continuous frame denoising. Compared to autoregressive methods, Flowception alleviates error accumulation/drift as the frame insertion mechanism during sampling serves as an efficient compression mechanism to handle long-term context. Compared to full-sequence flows, our method reduces FLOPs for training three-fold, while also being more amenable to local attention variants, and allowing to learn the length of videos jointly with their content. Quantitative experimental results show improved FVD and VBench metrics over autoregressive and full-sequence baselines, which is further validated with qualitative results. Finally, by learning to insert and denoise frames in a sequence, Flowception seamlessly integrates different tasks such as image-to-video generation and video interpolation.
Is Less Really More? Fake News Detection with Limited Information
Apr 02, 2025The threat that online fake news and misinformation pose to democracy, justice, public confidence, and especially to vulnerable populations, has led to a sharp increase in the need for fake news detection and intervention. Whether multi-modal or pure text-based, most fake news detection methods depend on textual analysis of entire articles. However, these fake news detection methods come with certain limitations. For instance, fake news detection methods that rely on full text can be computationally inefficient, demand large amounts of training data to achieve competitive accuracy, and may lack robustness across different datasets. This is because fake news datasets have strong variations in terms of the level and types of information they provide; where some can include large paragraphs of text with images and metadata, others can be a few short sentences. Perhaps if one could only use minimal information to detect fake news, fake news detection methods could become more robust and resilient to the lack of information. We aim to overcome these limitations by detecting fake news using systematically selected, limited information that is both effective and capable of delivering robust, promising performance. We propose a framework called SLIM Systematically-selected Limited Information) for fake news detection. In SLIM, we quantify the amount of information by introducing information-theoretic measures. SLIM leverages limited information to achieve performance in fake news detection comparable to that of state-of-the-art obtained using the full text. Furthermore, by combining various types of limited information, SLIM can perform even better while significantly reducing the quantity of information required for training compared to state-of-the-art language model-based fake news detection techniques.
Byte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
READ: Recurrent Adaptation of Large Transformers
May 24, 2023Fine-tuning large-scale Transformers has led to the explosion of many AI applications across Natural Language Processing and Computer Vision tasks. However, fine-tuning all pre-trained model parameters becomes impractical as the model size and number of tasks increase. Parameter-efficient transfer learning (PETL) methods aim to address these challenges. While effective in reducing the number of trainable parameters, PETL methods still require significant energy and computational resources to fine-tune. In this paper, we introduce \textbf{RE}current \textbf{AD}aption (READ) -- a lightweight and memory-efficient fine-tuning method -- to overcome the limitations of the current PETL approaches. Specifically, READ inserts a small RNN network alongside the backbone model so that the model does not have to back-propagate through the large backbone network. Through comprehensive empirical evaluation of the GLUE benchmark, we demonstrate READ can achieve a $56\%$ reduction in the training memory consumption and an $84\%$ reduction in the GPU energy usage while retraining high model quality compared to full-tuning. Additionally, the model size of READ does not grow with the backbone model size, making it a highly scalable solution for fine-tuning large Transformers.
Now It Sounds Like You: Learning Personalized Vocabulary On Device
May 05, 2023

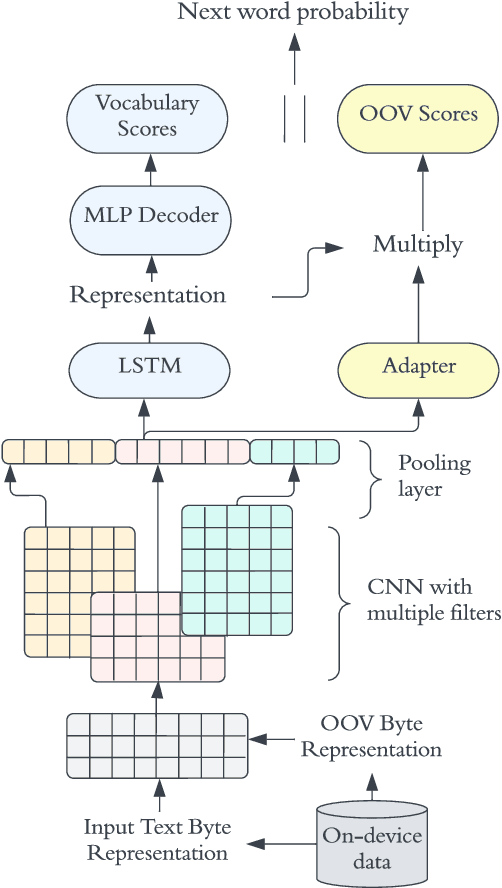

In recent years, Federated Learning (FL) has shown significant advancements in its ability to perform various natural language processing (NLP) tasks. This work focuses on applying personalized FL for on-device language modeling. Due to limitations of memory and latency, these models cannot support the complexity of sub-word tokenization or beam search decoding, resulting in the decision to deploy a closed-vocabulary language model. However, closed-vocabulary models are unable to handle out-of-vocabulary (OOV) words belonging to specific users. To address this issue, We propose a novel technique called "OOV expansion" that improves OOV coverage and increases model accuracy while minimizing the impact on memory and latency. This method introduces a personalized "OOV adapter" that effectively transfers knowledge from a central model and learns word embedding for personalized vocabulary. OOV expansion significantly outperforms standard FL personalization methods on a set of common FL benchmarks.
On Noisy Evaluation in Federated Hyperparameter Tuning
Jan 05, 2023Hyperparameter tuning is critical to the success of federated learning applications. Unfortunately, appropriately selecting hyperparameters is challenging in federated networks. Issues of scale, privacy, and heterogeneity introduce noise in the tuning process and make it difficult to evaluate the performance of various hyperparameters. In this work, we perform the first systematic study on the effect of noisy evaluation in federated hyperparameter tuning. We first identify and rigorously explore key sources of noise, including client subsampling, data and systems heterogeneity, and data privacy. Surprisingly, our results indicate that even small amounts of noise can significantly impact tuning methods-reducing the performance of state-of-the-art approaches to that of naive baselines. To address noisy evaluation in such scenarios, we propose a simple and effective approach that leverages public proxy data to boost the evaluation signal. Our work establishes general challenges, baselines, and best practices for future work in federated hyperparameter tuning.
Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning
Oct 14, 2022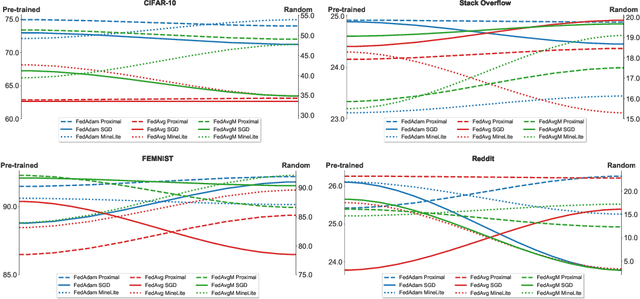

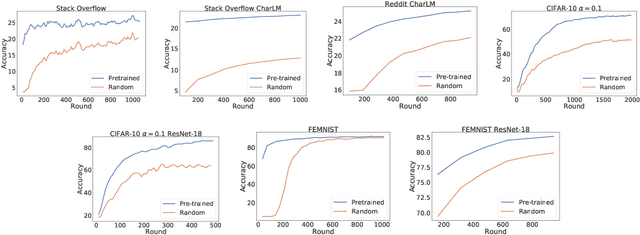
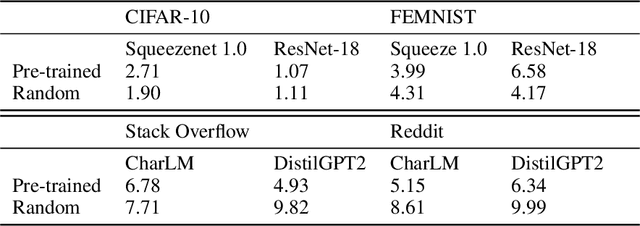
An oft-cited challenge of federated learning is the presence of heterogeneity. \emph{Data heterogeneity} refers to the fact that data from different clients may follow very different distributions. \emph{System heterogeneity} refers to the fact that client devices have different system capabilities. A considerable number of federated optimization methods address this challenge. In the literature, empirical evaluations usually start federated training from random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task that can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four standard federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables the training of more accurate models (up to 40\%) than is possible when starting from random initialization. Surprisingly, we also find that starting federated learning from a pre-trained initialization reduces the effect of both data and system heterogeneity. We recommend that future work proposing and evaluating federated optimization methods evaluate the performance when starting from random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
Where to Begin? Exploring the Impact of Pre-Training and Initialization in Federated Learning
Jun 30, 2022



An oft-cited challenge of federated learning is the presence of data heterogeneity -- the data at different clients may follow very different distributions. Several federated optimization methods have been proposed to address these challenges. In the literature, empirical evaluations usually start federated training from a random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task which can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four common federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables training more accurate models (by up to 40\%) than is possible than when starting from a random initialization. Surprisingly, we also find that the effect of data heterogeneity is much less significant when starting federated training from a pre-trained initialization. Rather, when starting from a pre-trained model, using an adaptive optimizer at the server, such as \textsc{FedAdam}, consistently leads to the best accuracy. We recommend that future work proposing and evaluating federated optimization methods consider the performance when starting both random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity
May 30, 2022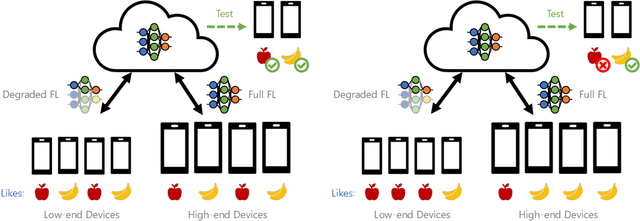
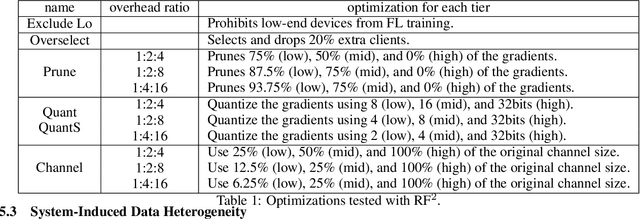
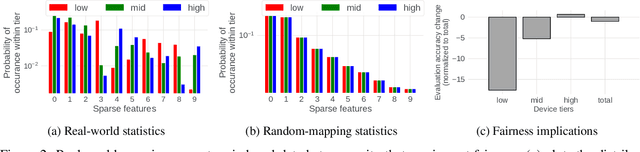
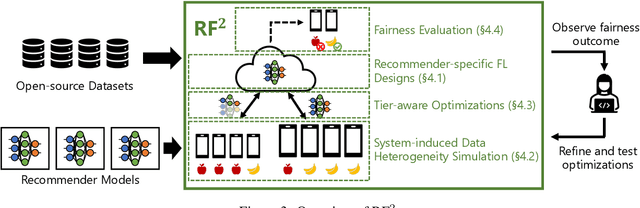
Federated learning (FL) is an effective mechanism for data privacy in recommender systems by running machine learning model training on-device. While prior FL optimizations tackled the data and system heterogeneity challenges faced by FL, they assume the two are independent of each other. This fundamental assumption is not reflective of real-world, large-scale recommender systems -- data and system heterogeneity are tightly intertwined. This paper takes a data-driven approach to show the inter-dependence of data and system heterogeneity in real-world data and quantifies its impact on the overall model quality and fairness. We design a framework, RF^2, to model the inter-dependence and evaluate its impact on state-of-the-art model optimization techniques for federated recommendation tasks. We demonstrate that the impact on fairness can be severe under realistic heterogeneity scenarios, by up to 15.8--41x compared to a simple setup assumed in most (if not all) prior work. It means when realistic system-induced data heterogeneity is not properly modeled, the fairness impact of an optimization can be downplayed by up to 41x. The result shows that modeling realistic system-induced data heterogeneity is essential to achieving fair federated recommendation learning. We plan to open-source RF^2 to enable future design and evaluation of FL innovations.