 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch in Collaborative Learning Does Not Serve Cross-Silo Federated Learning in Practice
Oct 14, 2025Cross-silo federated learning (FL) is a promising approach to enable cross-organization collaboration in machine learning model development without directly sharing private data. Despite growing organizational interest driven by data protection regulations such as GDPR and HIPAA, the adoption of cross-silo FL remains limited in practice. In this paper, we conduct an interview study to understand the practical challenges associated with cross-silo FL adoption. With interviews spanning a diverse set of stakeholders such as user organizations, software providers, and academic researchers, we uncover various barriers, from concerns about model performance to questions of incentives and trust between participating organizations. Our study shows that cross-silo FL faces a set of challenges that have yet to be well-captured by existing research in the area and are quite distinct from other forms of federated learning such as cross-device FL. We end with a discussion on future research directions that can help overcome these challenges.
Exact Unlearning of Finetuning Data via Model Merging at Scale
Apr 06, 2025Approximate unlearning has gained popularity as an approach to efficiently update an LLM so that it behaves (roughly) as if it was not trained on a subset of data to begin with. However, existing methods are brittle in practice and can easily be attacked to reveal supposedly unlearned information. To alleviate issues with approximate unlearning, we instead propose SIFT-Masks (SIgn-Fixed Tuning-Masks), an exact unlearning method based on model merging. SIFT-Masks addresses two key limitations of standard model merging: (1) merging a large number of tasks can severely harm utility; and (2) methods that boost utility by sharing extra information across tasks make exact unlearning prohibitively expensive. SIFT-Masks solves these issues by (1) applying local masks to recover task-specific performance; and (2) constraining finetuning to align with a global sign vector as a lightweight approach to determine masks independently before merging. Across four settings where we merge up to 500 models, SIFT-Masks improves accuracy by 5-80% over naive merging and uses up to 250x less compute for exact unlearning compared to other merging baselines.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Federated LoRA with Sparse Communication
Jun 07, 2024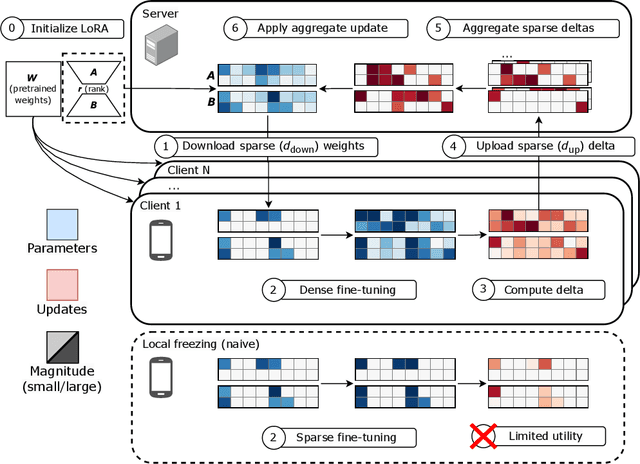

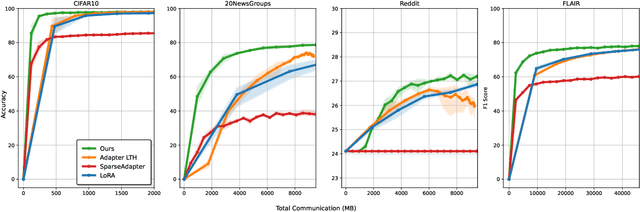
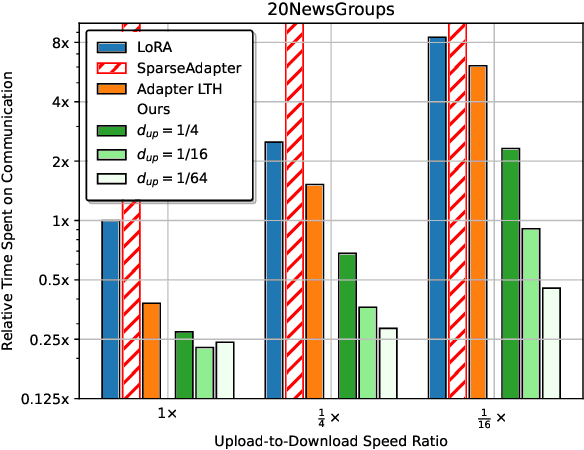
Low-rank adaptation (LoRA) is a natural method for finetuning in communication-constrained machine learning settings such as cross-device federated learning. Prior work that has studied LoRA in the context of federated learning has focused on improving LoRA's robustness to heterogeneity and privacy. In this work, we instead consider techniques for further improving communication-efficiency in federated LoRA. Unfortunately, we show that centralized ML methods that improve the efficiency of LoRA through unstructured pruning do not transfer well to federated settings. We instead study a simple approach, \textbf{FLASC}, that applies sparsity to LoRA during communication while allowing clients to locally fine-tune the entire LoRA module. Across four common federated learning tasks, we demonstrate that this method matches the performance of dense LoRA with up to $10\times$ less communication. Additionally, despite being designed primarily to target communication, we find that this approach has benefits in terms of heterogeneity and privacy relative to existing approaches tailored to these specific concerns. Overall, our work highlights the importance of considering system-specific constraints when developing communication-efficient finetuning approaches, and serves as a simple and competitive baseline for future work in federated finetuning.
On Noisy Evaluation in Federated Hyperparameter Tuning
Jan 05, 2023Hyperparameter tuning is critical to the success of federated learning applications. Unfortunately, appropriately selecting hyperparameters is challenging in federated networks. Issues of scale, privacy, and heterogeneity introduce noise in the tuning process and make it difficult to evaluate the performance of various hyperparameters. In this work, we perform the first systematic study on the effect of noisy evaluation in federated hyperparameter tuning. We first identify and rigorously explore key sources of noise, including client subsampling, data and systems heterogeneity, and data privacy. Surprisingly, our results indicate that even small amounts of noise can significantly impact tuning methods-reducing the performance of state-of-the-art approaches to that of naive baselines. To address noisy evaluation in such scenarios, we propose a simple and effective approach that leverages public proxy data to boost the evaluation signal. Our work establishes general challenges, baselines, and best practices for future work in federated hyperparameter tuning.
ProportionNet: Balancing Fairness and Revenue for Auction Design with Deep Learning
Oct 13, 2020
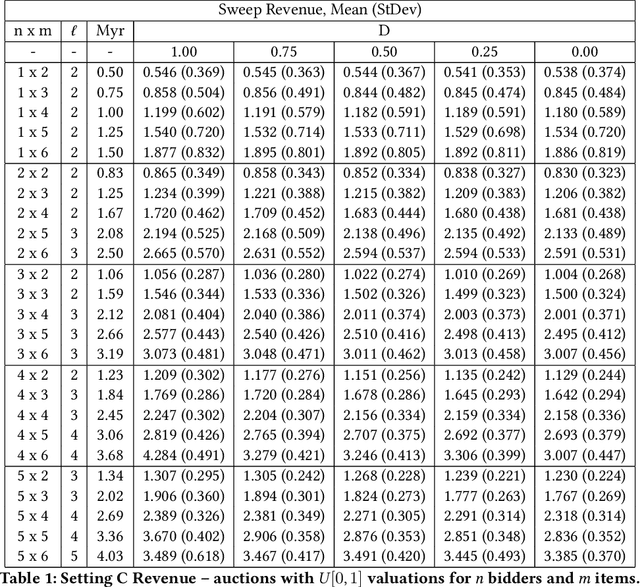
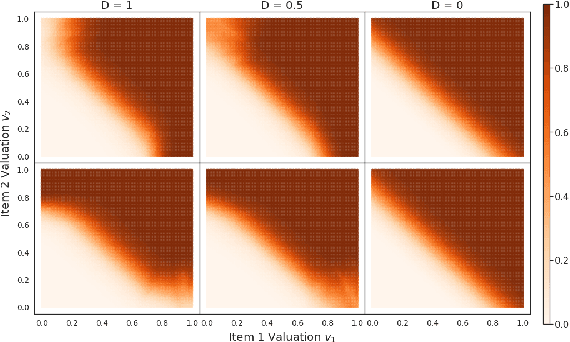
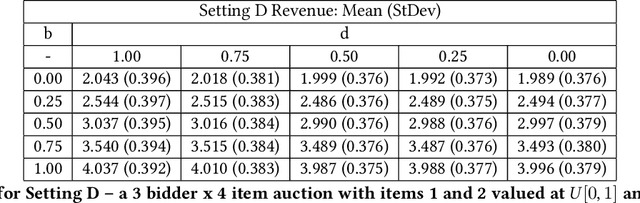
The design of revenue-maximizing auctions with strong incentive guarantees is a core concern of economic theory. Computational auctions enable online advertising, sourcing, spectrum allocation, and myriad financial markets. Analytic progress in this space is notoriously difficult; since Myerson's 1981 work characterizing single-item optimal auctions, there has been limited progress outside of restricted settings. A recent paper by D\"utting et al. circumvents analytic difficulties by applying deep learning techniques to, instead, approximate optimal auctions. In parallel, new research from Ilvento et al. and other groups has developed notions of fairness in the context of auction design. Inspired by these advances, in this paper, we extend techniques for approximating auctions using deep learning to address concerns of fairness while maintaining high revenue and strong incentive guarantees.
HATSUKI : An anime character like robot figure platform with anime-style expressions and imitation learning based action generation
Mar 31, 2020


Japanese character figurines are popular and have pivot position in Otaku culture. Although numerous robots have been developed, less have focused on otaku-culture or on embodying the anime character figurine. Therefore, we take the first steps to bridge this gap by developing Hatsuki, which is a humanoid robot platform with anime based design. Hatsuki's novelty lies in aesthetic design, 2D facial expressions, and anime-style behaviors that allows it to deliver rich interaction experiences resembling anime-characters. We explain our design implementation process of Hatsuki, followed by our evaluations. In order to explore user impressions and opinions towards Hatsuki, we conducted a questionnaire in the world's largest anime-figurine event. The results indicate that participants were generally very satisfied with Hatsuki's design, and proposed various use case scenarios and deployment contexts for Hatsuki. The second evaluation focused on imitation learning, as such method can provide better interaction ability in the real world and generate rich, context-adaptive behavior in different situations. We made Hatsuki learn 11 actions, combining voice, facial expressions and motions, through neuron network based policy model with our proposed interface. Results show our approach was successfully able to generate the actions through self-organized contexts, which shows the potential for generalizing our approach in further actions under different contexts. Lastly, we present our future research direction for Hatsuki, and provide our conclusion.
Towards Explainability of Machine Learning Models in Insurance Pricing
Mar 24, 2020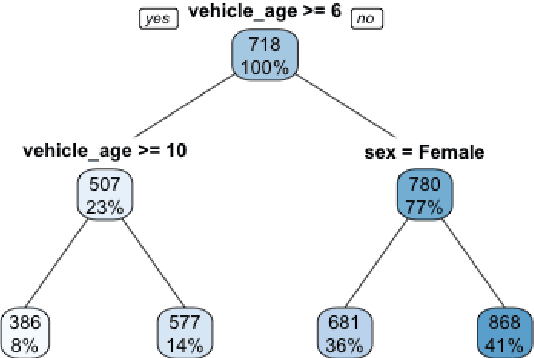
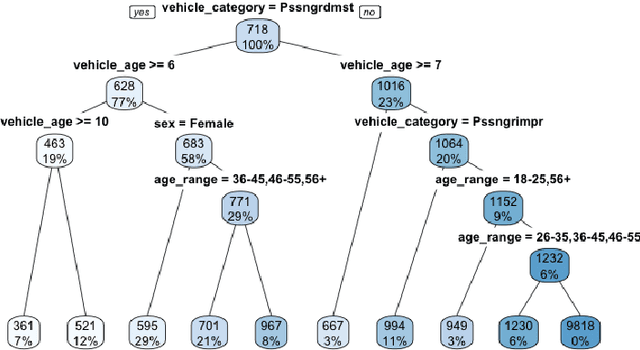
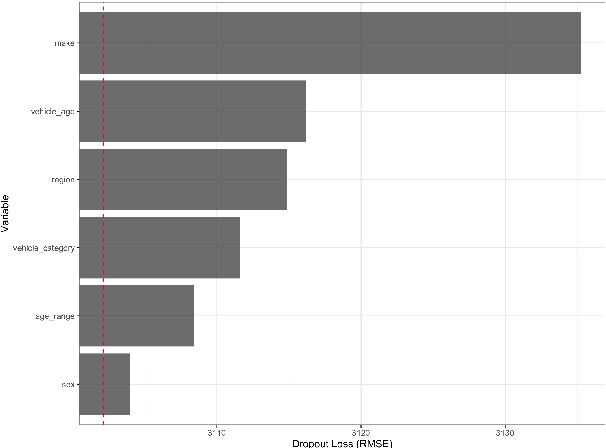
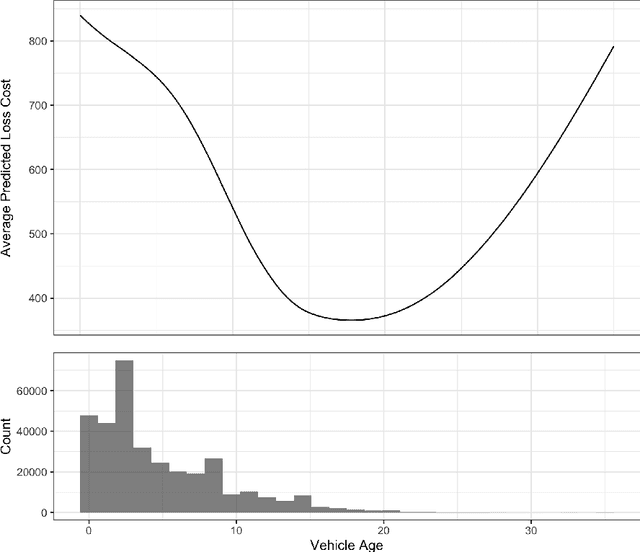
Machine learning methods have garnered increasing interest among actuaries in recent years. However, their adoption by practitioners has been limited, partly due to the lack of transparency of these methods, as compared to generalized linear models. In this paper, we discuss the need for model interpretability in property & casualty insurance ratemaking, propose a framework for explaining models, and present a case study to illustrate the framework.
Individual Claims Forecasting with Bayesian Mixture Density Networks
Mar 05, 2020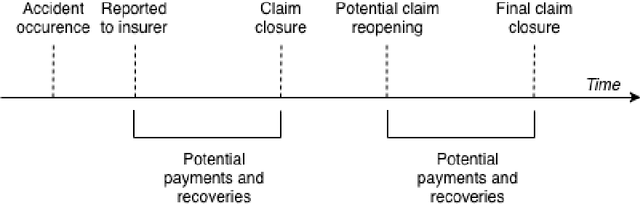
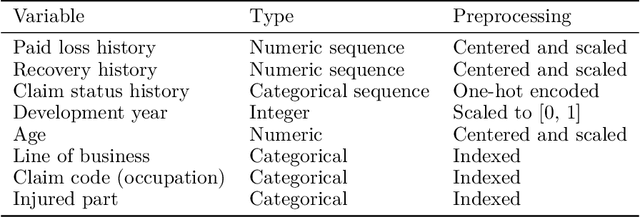
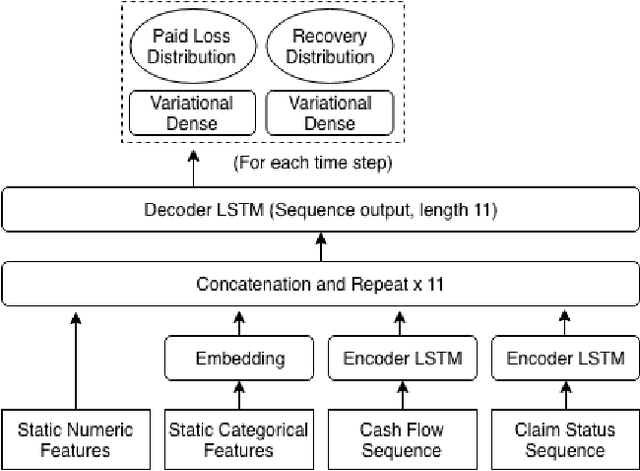
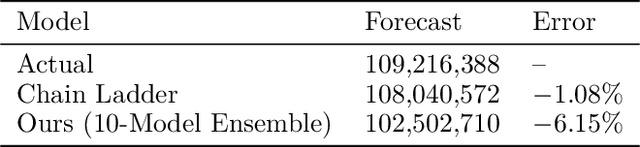
We introduce an individual claims forecasting framework utilizing Bayesian mixture density networks that can be used for claims analytics tasks such as case reserving and triaging. The proposed approach enables incorporating claims information from both structured and unstructured data sources, producing multi-period cash flow forecasts, and generating different scenarios of future payment patterns. We implement and evaluate the modeling framework using publicly available data.
Generative Synthesis of Insurance Datasets
Dec 05, 2019

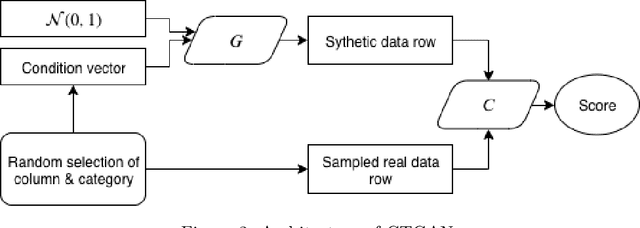

One of the impediments in advancing actuarial research and developing open source assets for insurance analytics is the lack of realistic publicly available datasets. In this work, we develop a workflow for synthesizing insurance datasets leveraging state-of-the-art neural network techniques. We evaluate the predictive modeling efficacy of datasets synthesized from publicly available data in the domains of general insurance pricing and life insurance shock lapse modeling. The trained synthesizers are able to capture representative characteristics of the real datasets. This workflow is implemented via an R interface to promote adoption by researchers and data owners.