 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyllabus: Portable Curricula for Reinforcement Learning Agents
Nov 18, 2024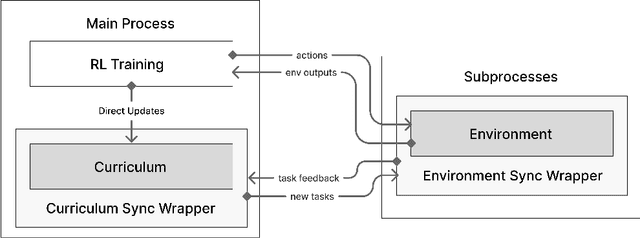


Curriculum learning has been a quiet yet crucial component of many of the high-profile successes of reinforcement learning. Despite this, none of the major reinforcement learning libraries directly support curriculum learning or include curriculum learning implementations. These methods can improve the capabilities and robustness of RL agents, but often require significant, complex changes to agent training code. We introduce Syllabus, a library for training RL agents with curriculum learning, as a solution to this problem. Syllabus provides a universal API for curriculum learning algorithms, implementations of popular curriculum learning methods, and infrastructure for easily integrating them with distributed training code written in nearly any RL library. Syllabus provides a minimal API for each of the core components of curriculum learning, dramatically simplifying the process of designing new algorithms and applying existing algorithms to new environments. We demonstrate that the same Syllabus code can be used to train agents written in multiple different RL libraries on numerous domains. In doing so, we present the first examples of curriculum learning in NetHack and Neural MMO, two of the premier challenges for single-agent and multi-agent RL respectively, achieving strong results compared to state of the art baselines.
Robust Fair Clustering with Group Membership Uncertainty Sets
Jun 02, 2024We study the canonical fair clustering problem where each cluster is constrained to have close to population-level representation of each group. Despite significant attention, the salient issue of having incomplete knowledge about the group membership of each point has been superficially addressed. In this paper, we consider a setting where errors exist in the assigned group memberships. We introduce a simple and interpretable family of error models that require a small number of parameters to be given by the decision maker. We then present an algorithm for fair clustering with provable robustness guarantees. Our framework enables the decision maker to trade off between the robustness and the clustering quality. Unlike previous work, our algorithms are backed by worst-case theoretical guarantees. Finally, we empirically verify the performance of our algorithm on real world datasets and show its superior performance over existing baselines.
Reward Scale Robustness for Proximal Policy Optimization via DreamerV3 Tricks
Oct 26, 2023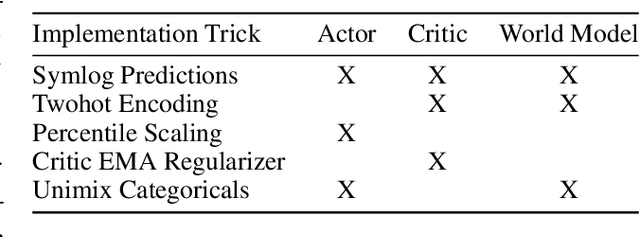
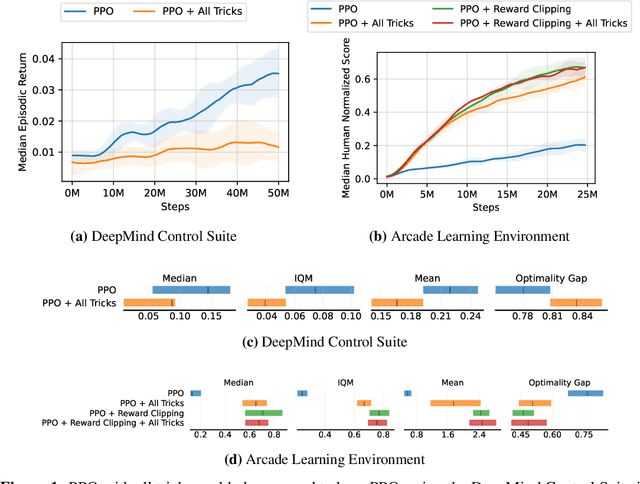
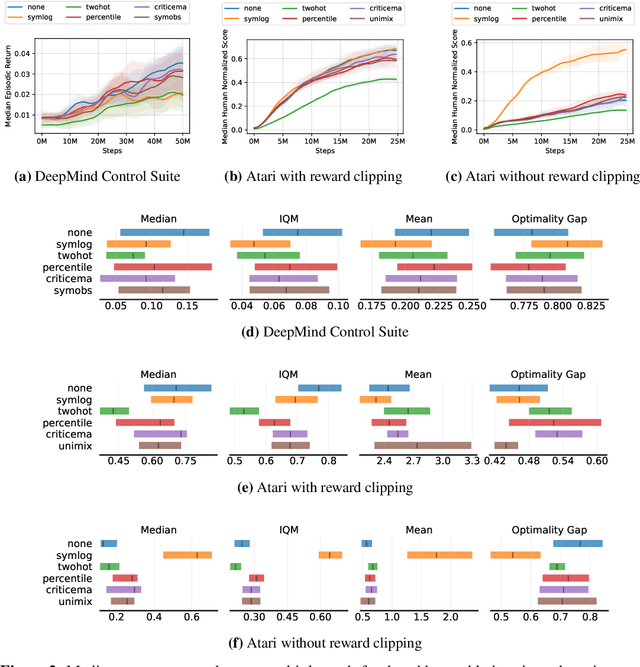
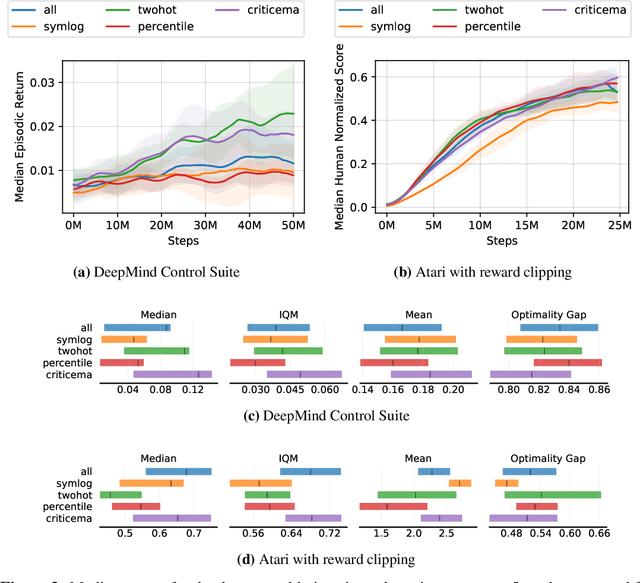
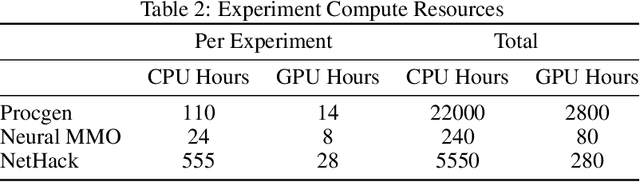
Most reinforcement learning methods rely heavily on dense, well-normalized environment rewards. DreamerV3 recently introduced a model-based method with a number of tricks that mitigate these limitations, achieving state-of-the-art on a wide range of benchmarks with a single set of hyperparameters. This result sparked discussion about the generality of the tricks, since they appear to be applicable to other reinforcement learning algorithms. Our work applies DreamerV3's tricks to PPO and is the first such empirical study outside of the original work. Surprisingly, we find that the tricks presented do not transfer as general improvements to PPO. We use a high quality PPO reference implementation and present extensive ablation studies totaling over 10,000 A100 hours on the Arcade Learning Environment and the DeepMind Control Suite. Though our experiments demonstrate that these tricks do not generally outperform PPO, we identify cases where they succeed and offer insight into the relationship between the implementation tricks. In particular, PPO with these tricks performs comparably to PPO on Atari games with reward clipping and significantly outperforms PPO without reward clipping.
RecRec: Algorithmic Recourse for Recommender Systems
Aug 28, 2023



Recommender systems play an essential role in the choices people make in domains such as entertainment, shopping, food, news, employment, and education. The machine learning models underlying these recommender systems are often enormously large and black-box in nature for users, content providers, and system developers alike. It is often crucial for all stakeholders to understand the model's rationale behind making certain predictions and recommendations. This is especially true for the content providers whose livelihoods depend on the recommender system. Drawing motivation from the practitioners' need, in this work, we propose a recourse framework for recommender systems, targeted towards the content providers. Algorithmic recourse in the recommendation setting is a set of actions that, if executed, would modify the recommendations (or ranking) of an item in the desired manner. A recourse suggests actions of the form: "if a feature changes X to Y, then the ranking of that item for a set of users will change to Z." Furthermore, we demonstrate that RecRec is highly effective in generating valid, sparse, and actionable recourses through an empirical evaluation of recommender systems trained on three real-world datasets. To the best of our knowledge, this work is the first to conceptualize and empirically test a generalized framework for generating recourses for recommender systems.
Diffused Redundancy in Pre-trained Representations
May 31, 2023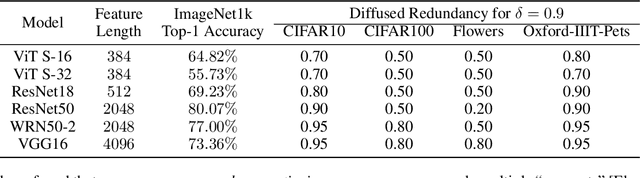
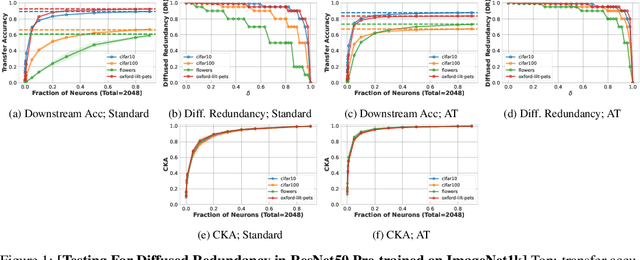
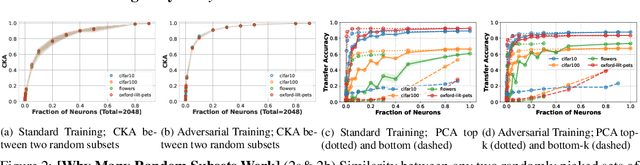
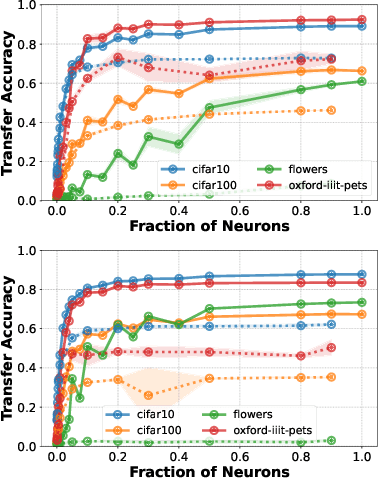
Representations learned by pre-training a neural network on a large dataset are increasingly used successfully to perform a variety of downstream tasks. In this work, we take a closer look at how features are encoded in such pre-trained representations. We find that learned representations in a given layer exhibit a degree of diffuse redundancy, i.e., any randomly chosen subset of neurons in the layer that is larger than a threshold size shares a large degree of similarity with the full layer and is able to perform similarly as the whole layer on a variety of downstream tasks. For example, a linear probe trained on $20\%$ of randomly picked neurons from a ResNet50 pre-trained on ImageNet1k achieves an accuracy within $5\%$ of a linear probe trained on the full layer of neurons for downstream CIFAR10 classification. We conduct experiments on different neural architectures (including CNNs and Transformers) pre-trained on both ImageNet1k and ImageNet21k and evaluate a variety of downstream tasks taken from the VTAB benchmark. We find that the loss & dataset used during pre-training largely govern the degree of diffuse redundancy and the "critical mass" of neurons needed often depends on the downstream task, suggesting that there is a task-inherent redundancy-performance Pareto frontier. Our findings shed light on the nature of representations learned by pre-trained deep neural networks and suggest that entire layers might not be necessary to perform many downstream tasks. We investigate the potential for exploiting this redundancy to achieve efficient generalization for downstream tasks and also draw caution to certain possible unintended consequences.
Who's Thinking? A Push for Human-Centered Evaluation of LLMs using the XAI Playbook
Mar 10, 2023Deployed artificial intelligence (AI) often impacts humans, and there is no one-size-fits-all metric to evaluate these tools. Human-centered evaluation of AI-based systems combines quantitative and qualitative analysis and human input. It has been explored to some depth in the explainable AI (XAI) and human-computer interaction (HCI) communities. Gaps remain, but the basic understanding that humans interact with AI and accompanying explanations, and that humans' needs -- complete with their cognitive biases and quirks -- should be held front and center, is accepted by the community. In this paper, we draw parallels between the relatively mature field of XAI and the rapidly evolving research boom around large language models (LLMs). Accepted evaluative metrics for LLMs are not human-centered. We argue that many of the same paths tread by the XAI community over the past decade will be retread when discussing LLMs. Specifically, we argue that humans' tendencies -- again, complete with their cognitive biases and quirks -- should rest front and center when evaluating deployed LLMs. We outline three developed focus areas of human-centered evaluation of XAI: mental models, use case utility, and cognitive engagement, and we highlight the importance of exploring each of these concepts for LLMs. Our goal is to jumpstart human-centered LLM evaluation.
Tensions Between the Proxies of Human Values in AI
Dec 14, 2022Motivated by mitigating potentially harmful impacts of technologies, the AI community has formulated and accepted mathematical definitions for certain pillars of accountability: e.g. privacy, fairness, and model transparency. Yet, we argue this is fundamentally misguided because these definitions are imperfect, siloed constructions of the human values they hope to proxy, while giving the guise that those values are sufficiently embedded in our technologies. Under popularized methods, tensions arise when practitioners attempt to achieve each pillar of fairness, privacy, and transparency in isolation or simultaneously. In this position paper, we push for redirection. We argue that the AI community needs to consider all the consequences of choosing certain formulations of these pillars -- not just the technical incompatibilities, but also the effects within the context of deployment. We point towards sociotechnical research for frameworks for the latter, but push for broader efforts into implementing these in practice.
Networked Restless Bandits with Positive Externalities
Dec 09, 2022



Restless multi-armed bandits are often used to model budget-constrained resource allocation tasks where receipt of the resource is associated with an increased probability of a favorable state transition. Prior work assumes that individual arms only benefit if they receive the resource directly. However, many allocation tasks occur within communities and can be characterized by positive externalities that allow arms to derive partial benefit when their neighbor(s) receive the resource. We thus introduce networked restless bandits, a novel multi-armed bandit setting in which arms are both restless and embedded within a directed graph. We then present Greta, a graph-aware, Whittle index-based heuristic algorithm that can be used to efficiently construct a constrained reward-maximizing action vector at each timestep. Our empirical results demonstrate that Greta outperforms comparison policies across a range of hyperparameter values and graph topologies.
Robustness Disparities in Face Detection
Nov 29, 2022
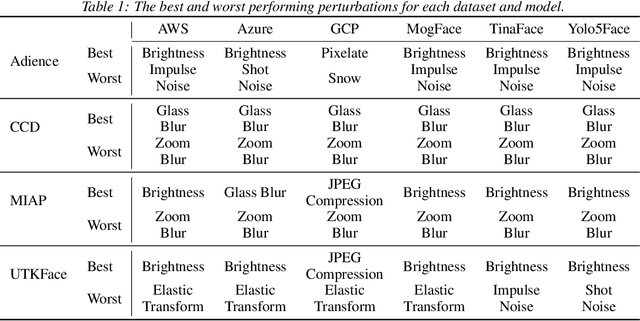

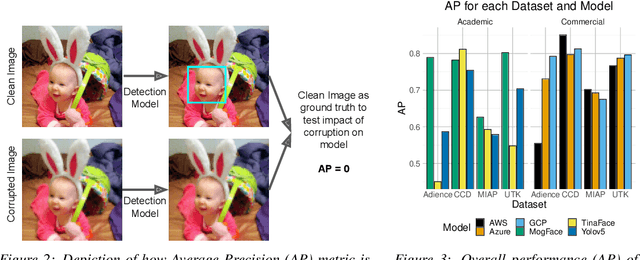
Facial analysis systems have been deployed by large companies and critiqued by scholars and activists for the past decade. Many existing algorithmic audits examine the performance of these systems on later stage elements of facial analysis systems like facial recognition and age, emotion, or perceived gender prediction; however, a core component to these systems has been vastly understudied from a fairness perspective: face detection, sometimes called face localization. Since face detection is a pre-requisite step in facial analysis systems, the bias we observe in face detection will flow downstream to the other components like facial recognition and emotion prediction. Additionally, no prior work has focused on the robustness of these systems under various perturbations and corruptions, which leaves open the question of how various people are impacted by these phenomena. We present the first of its kind detailed benchmark of face detection systems, specifically examining the robustness to noise of commercial and academic models. We use both standard and recently released academic facial datasets to quantitatively analyze trends in face detection robustness. Across all the datasets and systems, we generally find that photos of individuals who are $\textit{masculine presenting}$, $\textit{older}$, of $\textit{darker skin type}$, or have $\textit{dim lighting}$ are more susceptible to errors than their counterparts in other identities.
Interpretable Deep Reinforcement Learning for Green Security Games with Real-Time Information
Nov 09, 2022



Green Security Games with real-time information (GSG-I) add the real-time information about the agents' movement to the typical GSG formulation. Prior works on GSG-I have used deep reinforcement learning (DRL) to learn the best policy for the agent in such an environment without any need to store the huge number of state representations for GSG-I. However, the decision-making process of DRL methods is largely opaque, which results in a lack of trust in their predictions. To tackle this issue, we present an interpretable DRL method for GSG-I that generates visualization to explain the decisions taken by the DRL algorithm. We also show that this approach performs better and works well with a simpler training regimen compared to the existing method.