 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensions Between the Proxies of Human Values in AI
Dec 14, 2022Motivated by mitigating potentially harmful impacts of technologies, the AI community has formulated and accepted mathematical definitions for certain pillars of accountability: e.g. privacy, fairness, and model transparency. Yet, we argue this is fundamentally misguided because these definitions are imperfect, siloed constructions of the human values they hope to proxy, while giving the guise that those values are sufficiently embedded in our technologies. Under popularized methods, tensions arise when practitioners attempt to achieve each pillar of fairness, privacy, and transparency in isolation or simultaneously. In this position paper, we push for redirection. We argue that the AI community needs to consider all the consequences of choosing certain formulations of these pillars -- not just the technical incompatibilities, but also the effects within the context of deployment. We point towards sociotechnical research for frameworks for the latter, but push for broader efforts into implementing these in practice.
An Empirical Analysis of the Impact of Data Augmentation on Knowledge Distillation
Jun 09, 2020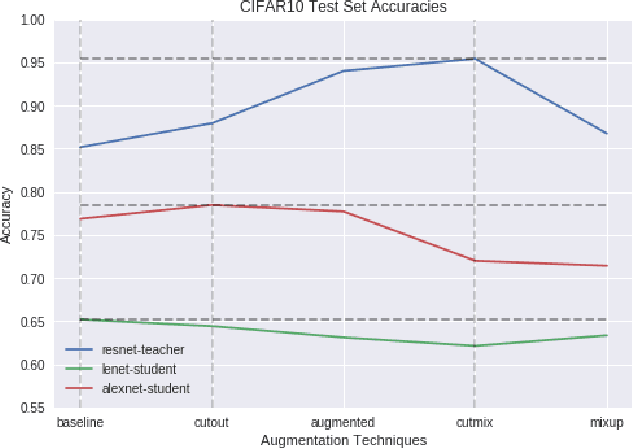
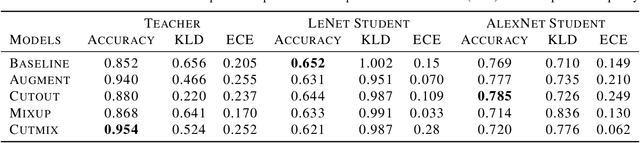


Generalization Performance of Deep Learning models trained using Empirical Risk Minimization can be improved significantly by using Data Augmentation strategies such as simple transformations, or using Mixed Samples. We attempt to empirically analyze the impact of such strategies on the transfer of generalization between teacher and student models in a distillation setup. We observe that if a teacher is trained using any of the mixed sample augmentation strategies, such as MixUp or CutMix, the student model distilled from it is impaired in its generalization capabilities. We hypothesize that such strategies limit a model's capability to learn example-specific features, leading to a loss in quality of the supervision signal during distillation. We present a novel Class-Discrimination metric to quantitatively measure this dichotomy in performance and link it to the discriminative capacity induced by the different strategies on a network's latent space.