 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphhopper: Multi-Hop Scene Graph Reasoning for Visual Question Answering
Jul 13, 2021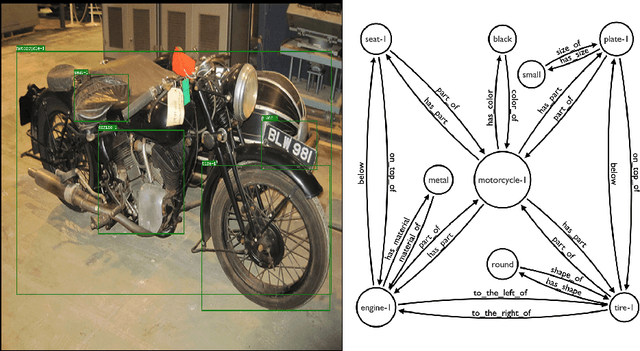
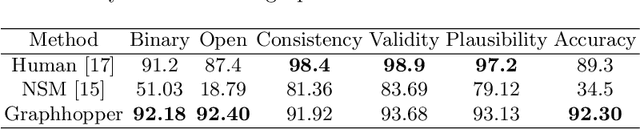
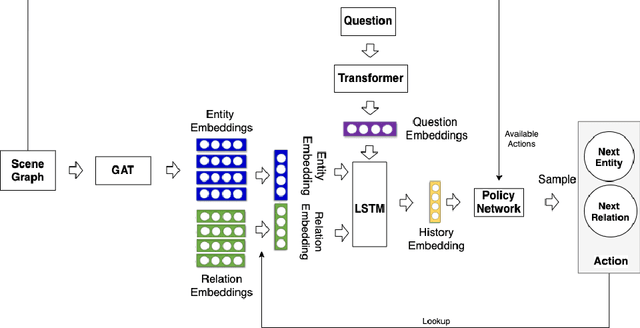

Visual Question Answering (VQA) is concerned with answering free-form questions about an image. Since it requires a deep semantic and linguistic understanding of the question and the ability to associate it with various objects that are present in the image, it is an ambitious task and requires multi-modal reasoning from both computer vision and natural language processing. We propose Graphhopper, a novel method that approaches the task by integrating knowledge graph reasoning, computer vision, and natural language processing techniques. Concretely, our method is based on performing context-driven, sequential reasoning based on the scene entities and their semantic and spatial relationships. As a first step, we derive a scene graph that describes the objects in the image, as well as their attributes and their mutual relationships. Subsequently, a reinforcement learning agent is trained to autonomously navigate in a multi-hop manner over the extracted scene graph to generate reasoning paths, which are the basis for deriving answers. We conduct an experimental study on the challenging dataset GQA, based on both manually curated and automatically generated scene graphs. Our results show that we keep up with a human performance on manually curated scene graphs. Moreover, we find that Graphhopper outperforms another state-of-the-art scene graph reasoning model on both manually curated and automatically generated scene graphs by a significant margin.
Active learning using weakly supervised signals for quality inspection
Apr 07, 2021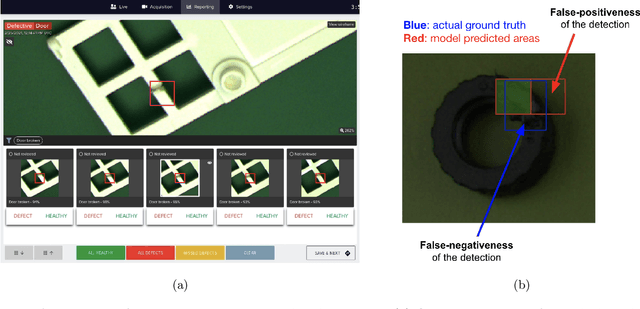

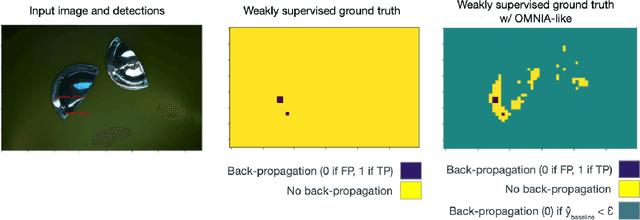
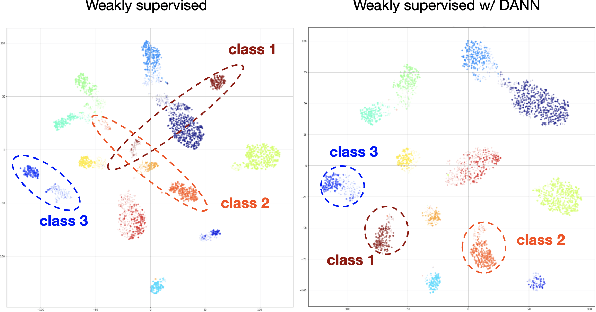
Because manufacturing processes evolve fast, and since production visual aspect can vary significantly on a daily basis, the ability to rapidly update machine vision based inspection systems is paramount. Unfortunately, supervised learning of convolutional neural networks requires a significant amount of annotated images for being able to learn effectively from new data. Acknowledging the abundance of continuously generated images coming from the production line and the cost of their annotation, we demonstrate it is possible to prioritize and accelerate the annotation process. In this work, we develop a methodology for learning actively, from rapidly mined, weakly (i.e. partially) annotated data, enabling a fast, direct feedback from the operators on the production line and tackling a big machine vision weakness: false positives. We also consider the problem of covariate shift, which arises inevitably due to changing conditions during data acquisition. In that regard, we show domain-adversarial training to be an efficient way to address this issue.
An Empirical Analysis of the Impact of Data Augmentation on Knowledge Distillation
Jun 09, 2020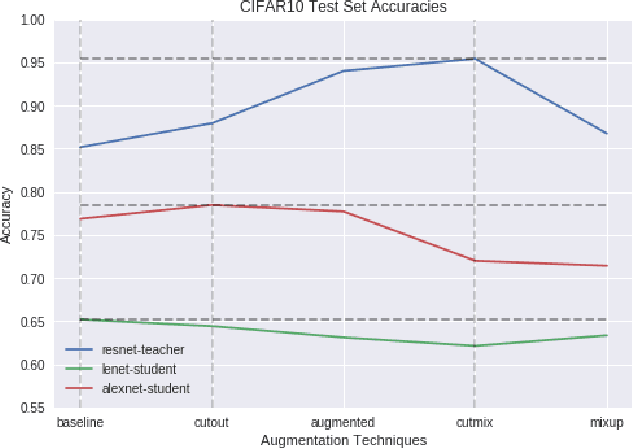
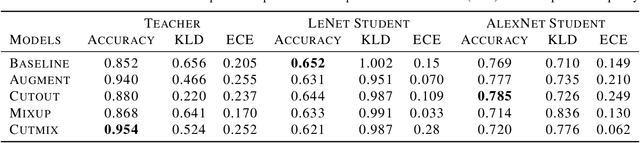


Generalization Performance of Deep Learning models trained using Empirical Risk Minimization can be improved significantly by using Data Augmentation strategies such as simple transformations, or using Mixed Samples. We attempt to empirically analyze the impact of such strategies on the transfer of generalization between teacher and student models in a distillation setup. We observe that if a teacher is trained using any of the mixed sample augmentation strategies, such as MixUp or CutMix, the student model distilled from it is impaired in its generalization capabilities. We hypothesize that such strategies limit a model's capability to learn example-specific features, leading to a loss in quality of the supervision signal during distillation. We present a novel Class-Discrimination metric to quantitatively measure this dichotomy in performance and link it to the discriminative capacity induced by the different strategies on a network's latent space.
Semi Supervised Phrase Localization in a Bidirectional Caption-Image Retrieval Framework
Aug 08, 2019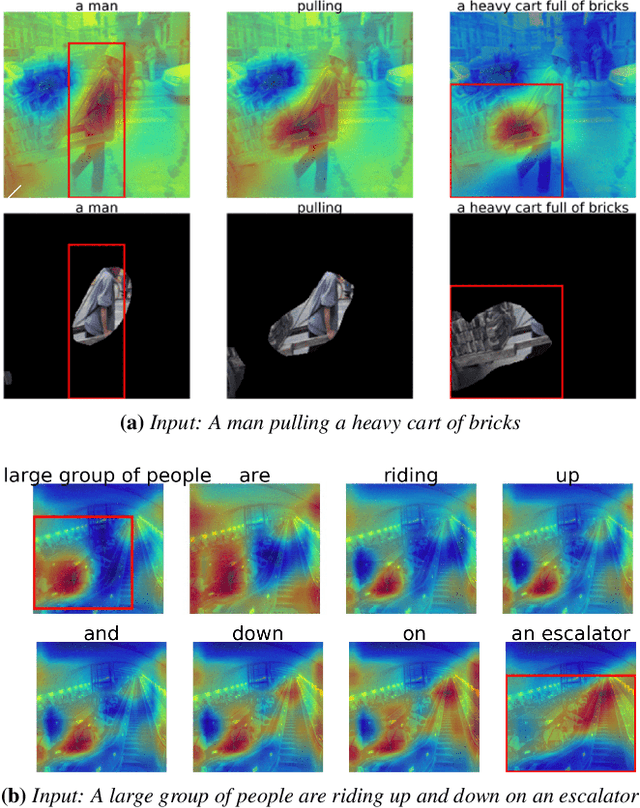
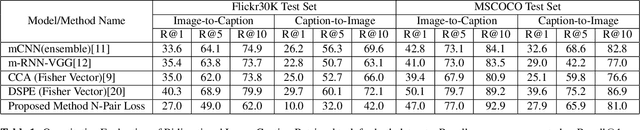
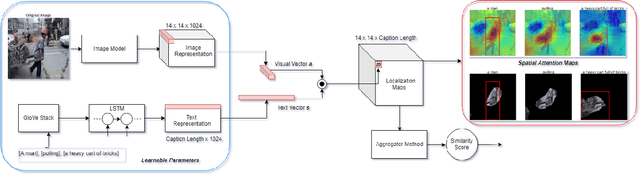
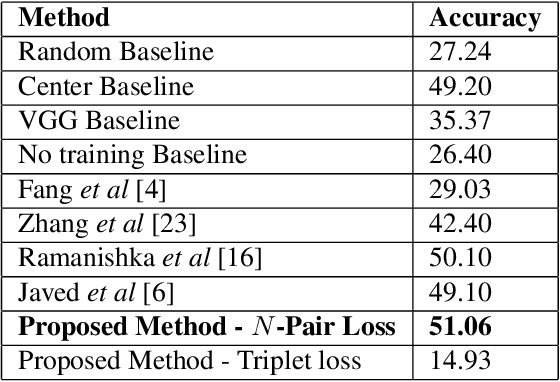
We introduce a novel deep neural network architecture that links visual regions to corresponding textual segments including phrases and words. To accomplish this task, our architecture makes use of the rich semantic information available in a joint embedding space of multi-modal data. From this joint embedding space, we extract the associative localization maps that develop naturally, without explicitly providing supervision during training for the localization task. The joint space is learned using a bidirectional ranking objective that is optimized using a $N$-Pair loss formulation. This training mechanism demonstrates the idea that localization information is learned inherently while optimizing a Bidirectional Retrieval objective. The model's retrieval and localization performance is evaluated on MSCOCO and Flickr30K Entities datasets. This architecture outperforms the state of the art results in the semi-supervised phrase localization setting.
Unsupervised Anomalous Trajectory Detection for Crowded Scenes
Jul 03, 2019

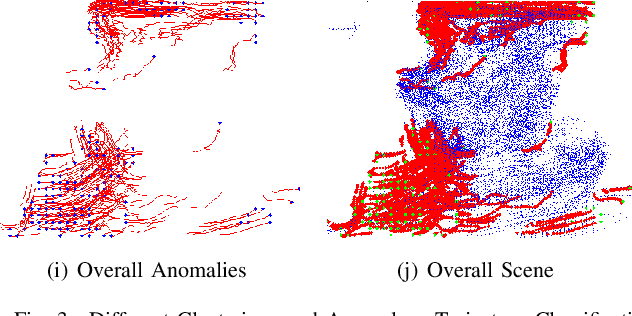
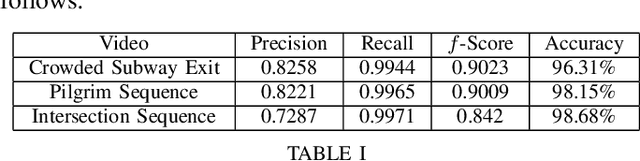
We present an improved clustering based, unsupervised anomalous trajectory detection algorithm for crowded scenes. The proposed work is based on four major steps, namely, extraction of trajectories from crowded scene video, extraction of several features from these trajectories, independent mean-shift clustering and anomaly detection. First, the trajectories of all moving objects in a crowd are extracted using a multi feature video object tracker. These trajectories are then transformed into a set of feature spaces. Mean shift clustering is applied on these feature matrices to obtain distinct clusters, while a Shannon Entropy based anomaly detector identifies corresponding anomalies. In the final step, a voting mechanism identifies the trajectories that exhibit anomalous characteristics. The algorithm is tested on crowd scene videos from datasets. The videos represent various possible crowd scenes with different motion patterns and the method performs well to detect the expected anomalous trajectories from the scene.