 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Generalizable NeRF Architecture Selection for Satellite Scene Reconstruction
Mar 18, 2026Neural Radiance Fields (NeRF) have emerged as a powerful approach for photorealistic 3D reconstruction from multi-view images. However, deploying NeRF for satellite imagery remains challenging. Each scene requires individual training, and optimizing architectures via Neural Architecture Search (NAS) demands hours to days of GPU time. While existing approaches focus on architectural improvements, our SHAP analysis reveals that multi-view consistency, rather than model architecture, determines reconstruction quality. Based on this insight, we develop PreSCAN, a predictive framework that estimates NeRF quality prior to training using lightweight geometric and photometric descriptors. PreSCAN selects suitable architectures in < 30 seconds with < 1 dB prediction error, achieving 1000$\times$ speedup over NAS. We further demonstrate PreSCAN's deployment utility on edge platforms (Jetson Orin), where combining its predictions with offline cost profiling reduces inference power by 26% and latency by 43% with minimal quality loss. Experiments on DFC2019 datasets confirm that PreSCAN generalizes across diverse satellite scenes without retraining.
A Novel One-tap Equalizer for Zero-Padded AFDM System over Doubly Selective Channels
Mar 03, 2026Recently, affine frequency division multiplexing (AFDM) has gained traction as a robust solution for doubly selective channels. In this paper, we present a novel low-complexity one-tap equalizer for zero-padded AFDM (ZP-AFDM) systems. We first select the AFDM parameters, $c_1$ and $c_2$, such that $c_1$ has a relatively high value, and $c_2$ depends on $c_1$, which simplifies the affine domain input-output relation (IOR). This selection also demonstrates that a phase term that varies slowly along the affine domain is experienced by all affine domain symbols and this variation is significantly slower compared to that experienced by the time domain symbols over doubly selective channels. To simplify the equalization, we then introduce zero padding to the transmitted affine domain symbols and reconstruction operation on the received affine domain symbols. By doing so, we convert the effective affine domain IOR of our ZP-AFDM system to be characterized using approximately circular convolution. Next, we transform the resulting affine domain symbols into a new domain called the frequency-of-affine (FoA) domain. We propose our one-tap equalizer in this FoA domain to efficiently recover the transmitted symbols. Numerical results demonstrate the effectiveness of our proposed one-tap equalizer, particularly when $c_1$ is high, without compromising performance robustness.
Selective Prior Synchronization via SYNC Loss
Feb 11, 2026Prediction under uncertainty is a critical requirement for the deep neural network to succeed responsibly. This paper focuses on selective prediction, which allows DNNs to make informed decisions about when to predict or abstain based on the uncertainty level of their predictions. Current methods are either ad-hoc such as SelectiveNet, focusing on how to modify the network architecture or objective function, or post-hoc such as softmax response, achieving selective prediction through analyzing the model's probabilistic outputs. We observe that post-hoc methods implicitly generate uncertainty information, termed the selective prior, which has traditionally been used only during inference. We argue that the selective prior provided by the selection mechanism is equally vital during the training stage. Therefore, we propose the SYNC loss which introduces a novel integration of ad-hoc and post-hoc method. Specifically, our approach incorporates the softmax response into the training process of SelectiveNet, enhancing its selective prediction capabilities by examining the selective prior. Evaluated across various datasets, including CIFAR-100, ImageNet-100, and Stanford Cars, our method not only enhances the model's generalization capabilities but also surpasses previous works in selective prediction performance, and sets new benchmarks for state-of-the-art performance.
Generalizable IoT Traffic Representations for Cross-Network Device Identification
Jan 27, 2026Machine learning models have demonstrated strong performance in classifying network traffic and identifying Internet-of-Things (IoT) devices, enabling operators to discover and manage IoT assets at scale. However, many existing approaches rely on end-to-end supervised pipelines or task-specific fine-tuning, resulting in traffic representations that are tightly coupled to labeled datasets and deployment environments, which can limit generalizability. In this paper, we study the problem of learning generalizable traffic representations for IoT device identification. We design compact encoder architectures that learn per-flow embeddings from unlabeled IoT traffic and evaluate them using a frozen-encoder protocol with a simple supervised classifier. Our specific contributions are threefold. (1) We develop unsupervised encoder--decoder models that learn compact traffic representations from unlabeled IoT network flows and assess their quality through reconstruction-based analysis. (2) We show that these learned representations can be used effectively for IoT device-type classification using simple, lightweight classifiers trained on frozen embeddings. (3) We provide a systematic benchmarking study against the state-of-the-art pretrained traffic encoders, showing that larger models do not necessarily yield more robust representations for IoT traffic. Using more than 18 million real IoT traffic flows collected across multiple years and deployment environments, we learn traffic representations from unlabeled data and evaluate device-type classification on disjoint labeled subsets, achieving macro F1-scores exceeding 0.9 for device-type classification and demonstrating robustness under cross-environment deployment.
Robust and Secure Blockage-Aware Pinching Antenna-assisted Wireless Communication
Jan 10, 2026In this work, we investigate a blockage-aware pinching antenna (PA) system designed for secure and robust wireless communication. The considered system comprises a base station equipped with multiple waveguides, each hosting multiple PAs, and serves multiple single-antenna legitimate users in the presence of multi-antenna eavesdroppers under imperfect channel state information (CSI). To safeguard confidential transmissions, artificial noise (AN) is deliberately injected to degrade the eavesdropping channels. Recognizing that conventional linear CSI-error bounds become overly conservative for spatially distributed PA architectures, we develop new geometry-aware uncertainty sets that jointly characterize eavesdroppers position and array-orientation errors. Building upon these sets, we formulate a robust joint optimization problem that determines per-waveguide beamforming and AN covariance, individual PA power-ratio allocation, and PA positions to maximize the system sum rate subject to secrecy constraints. The highly non-convex design problem is efficiently addressed via a low computational complexity iterative algorithm that capitalizes on block coordinate descent, penalty-based methods, majorization-minimization, the S-procedure, and Lipschitz-based surrogate functions. Simulation results demonstrate that sum rates for the proposed algorithm outperforms conventional fixed antenna systems by 4.7 dB, offering substantially improved rate and secrecy performance. In particular, (i) adaptive PA positioning preserves LoS to legitimate users while effectively exploiting waveguide geometry to disrupt eavesdropper channels, and (ii) neglecting blockage effects in the PA system significantly impacts the system design, leading to performance degradation and inadequate secrecy guarantees.
RobSurv: Vector Quantization-Based Multi-Modal Learning for Robust Cancer Survival Prediction
May 05, 2025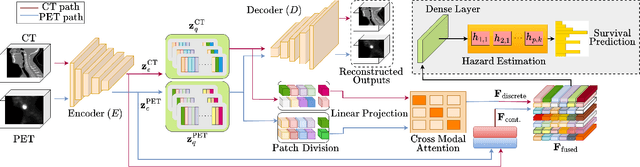
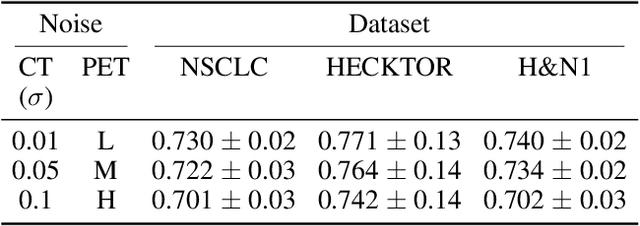
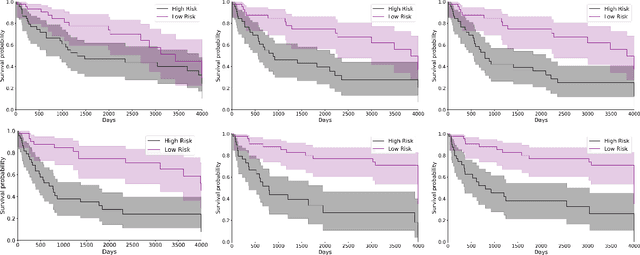
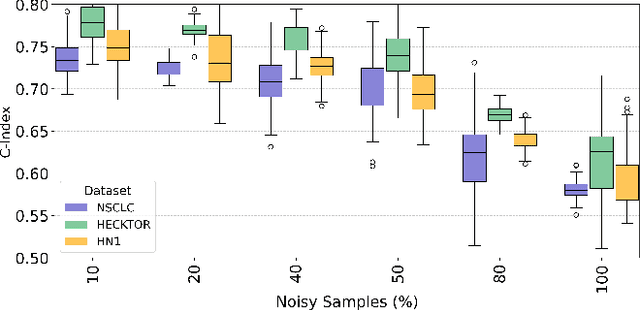
Cancer survival prediction using multi-modal medical imaging presents a critical challenge in oncology, mainly due to the vulnerability of deep learning models to noise and protocol variations across imaging centers. Current approaches struggle to extract consistent features from heterogeneous CT and PET images, limiting their clinical applicability. We address these challenges by introducing RobSurv, a robust deep-learning framework that leverages vector quantization for resilient multi-modal feature learning. The key innovation of our approach lies in its dual-path architecture: one path maps continuous imaging features to learned discrete codebooks for noise-resistant representation, while the parallel path preserves fine-grained details through continuous feature processing. This dual representation is integrated through a novel patch-wise fusion mechanism that maintains local spatial relationships while capturing global context via Transformer-based processing. In extensive evaluations across three diverse datasets (HECKTOR, H\&N1, and NSCLC Radiogenomics), RobSurv demonstrates superior performance, achieving concordance index of 0.771, 0.742, and 0.734 respectively - significantly outperforming existing methods. Most notably, our model maintains robust performance even under severe noise conditions, with performance degradation of only 3.8-4.5\% compared to 8-12\% in baseline methods. These results, combined with strong generalization across different cancer types and imaging protocols, establish RobSurv as a promising solution for reliable clinical prognosis that can enhance treatment planning and patient care.
Fine-Grained Rib Fracture Diagnosis with Hyperbolic Embeddings: A Detailed Annotation Framework and Multi-Label Classification Model
Apr 16, 2025



Accurate rib fracture identification and classification are essential for treatment planning. However, existing datasets often lack fine-grained annotations, particularly regarding rib fracture characterization, type, and precise anatomical location on individual ribs. To address this, we introduce a novel rib fracture annotation protocol tailored for fracture classification. Further, we enhance fracture classification by leveraging cross-modal embeddings that bridge radiological images and clinical descriptions. Our approach employs hyperbolic embeddings to capture the hierarchical nature of fracture, mapping visual features and textual descriptions into a shared non-Euclidean manifold. This framework enables more nuanced similarity computations between imaging characteristics and clinical descriptions, accounting for the inherent hierarchical relationships in fracture taxonomy. Experimental results demonstrate that our approach outperforms existing methods across multiple classification tasks, with average recall improvements of 6% on the AirRib dataset and 17.5% on the public RibFrac dataset.
U-WNO:U-Net-enhanced Wavelet Neural Operator for fetal head segmentation
Nov 25, 2024


This article describes the development of a novel U-Net-enhanced Wavelet Neural Operator (U-WNO),which combines wavelet decomposition, operator learning, and an encoder-decoder mechanism. This approach harnesses the superiority of the wavelets in time frequency localization of the functions, and the combine down-sampling and up-sampling operations to generate the segmentation map to enable accurate tracking of patterns in spatial domain and effective learning of the functional mappings to perform regional segmentation. By bridging the gap between theoretical advancements and practical applications, the U-WNO holds potential for significant impact in multiple science and industrial fields, facilitating more accurate decision-making and improved operational efficiencies. The operator is demonstrated for different pregnancy trimesters, utilizing two-dimensional ultrasound images.
RibCageImp: A Deep Learning Framework for 3D Ribcage Implant Generation
Nov 14, 2024



The recovery of damaged or resected ribcage structures requires precise, custom-designed implants to restore the integrity and functionality of the thoracic cavity. Traditional implant design methods rely mainly on manual processes, making them time-consuming and susceptible to variability. In this work, we explore the feasibility of automated ribcage implant generation using deep learning. We present a framework based on 3D U-Net architecture that processes CT scans to generate patient-specific implant designs. To the best of our knowledge, this is the first investigation into automated thoracic implant generation using deep learning approaches. Our preliminary results, while moderate, highlight both the potential and the significant challenges in this complex domain. These findings establish a foundation for future research in automated ribcage reconstruction and identify key technical challenges that need to be addressed for practical implementation.
Leveraging Auxiliary Classification for Rib Fracture Segmentation
Nov 14, 2024



Thoracic trauma often results in rib fractures, which demand swift and accurate diagnosis for effective treatment. However, detecting these fractures on rib CT scans poses considerable challenges, involving the analysis of many image slices in sequence. Despite notable advancements in algorithms for automated fracture segmentation, the persisting challenges stem from the diverse shapes and sizes of these fractures. To address these issues, this study introduces a sophisticated deep-learning model with an auxiliary classification task designed to enhance the accuracy of rib fracture segmentation. The auxiliary classification task is crucial in distinguishing between fractured ribs and negative regions, encompassing non-fractured ribs and surrounding tissues, from the patches obtained from CT scans. By leveraging this auxiliary task, the model aims to improve feature representation at the bottleneck layer by highlighting the regions of interest. Experimental results on the RibFrac dataset demonstrate significant improvement in segmentation performance.