 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebArbiter: A Principle-Guided Reasoning Process Reward Model for Web Agents
Jan 29, 2026Web agents hold great potential for automating complex computer tasks, yet their interactions involve long-horizon, sequential decision-making with irreversible actions. In such settings, outcome-based supervision is sparse and delayed, often rewarding incorrect trajectories and failing to support inference-time scaling. This motivates the use of Process Reward Models (WebPRMs) for web navigation, but existing approaches remain limited: scalar WebPRMs collapse progress into coarse, weakly grounded signals, while checklist-based WebPRMs rely on brittle template matching that fails under layout or semantic changes and often mislabels superficially correct actions as successful, providing little insight or interpretability. To address these challenges, we introduce WebArbiter, a reasoning-first, principle-inducing WebPRM that formulates reward modeling as text generation, producing structured justifications that conclude with a preference verdict and identify the action most conducive to task completion under the current context. Training follows a two-stage pipeline: reasoning distillation equips the model with coherent principle-guided reasoning, and reinforcement learning corrects teacher biases by directly aligning verdicts with correctness, enabling stronger generalization. To support systematic evaluation, we release WebPRMBench, a comprehensive benchmark spanning four diverse web environments with rich tasks and high-quality preference annotations. On WebPRMBench, WebArbiter-7B outperforms the strongest baseline, GPT-5, by 9.1 points. In reward-guided trajectory search on WebArena-Lite, it surpasses the best prior WebPRM by up to 7.2 points, underscoring its robustness and practical value in real-world complex web tasks.
AUVIC: Adversarial Unlearning of Visual Concepts for Multi-modal Large Language Models
Nov 14, 2025Multimodal Large Language Models (MLLMs) achieve impressive performance once optimized on massive datasets. Such datasets often contain sensitive or copyrighted content, raising significant data privacy concerns. Regulatory frameworks mandating the 'right to be forgotten' drive the need for machine unlearning. This technique allows for the removal of target data without resource-consuming retraining. However, while well-studied for text, visual concept unlearning in MLLMs remains underexplored. A primary challenge is precisely removing a target visual concept without disrupting model performance on related entities. To address this, we introduce AUVIC, a novel visual concept unlearning framework for MLLMs. AUVIC applies adversarial perturbations to enable precise forgetting. This approach effectively isolates the target concept while avoiding unintended effects on similar entities. To evaluate our method, we construct VCUBench. It is the first benchmark designed to assess visual concept unlearning in group contexts. Experimental results demonstrate that AUVIC achieves state-of-the-art target forgetting rates while incurs minimal performance degradation on non-target concepts.
Improving Perturbation-based Explanations by Understanding the Role of Uncertainty Calibration
Nov 13, 2025Perturbation-based explanations are widely utilized to enhance the transparency of machine-learning models in practice. However, their reliability is often compromised by the unknown model behavior under the specific perturbations used. This paper investigates the relationship between uncertainty calibration - the alignment of model confidence with actual accuracy - and perturbation-based explanations. We show that models systematically produce unreliable probability estimates when subjected to explainability-specific perturbations and theoretically prove that this directly undermines global and local explanation quality. To address this, we introduce ReCalX, a novel approach to recalibrate models for improved explanations while preserving their original predictions. Empirical evaluations across diverse models and datasets demonstrate that ReCalX consistently reduces perturbation-specific miscalibration most effectively while enhancing explanation robustness and the identification of globally important input features.
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Aug 27, 2025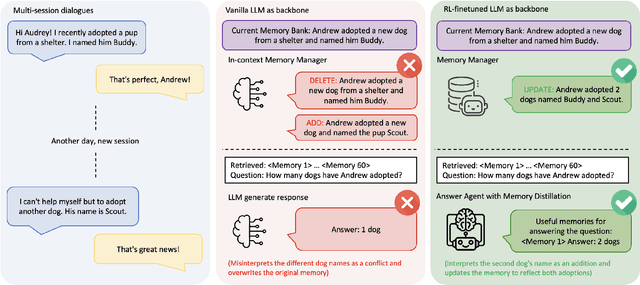
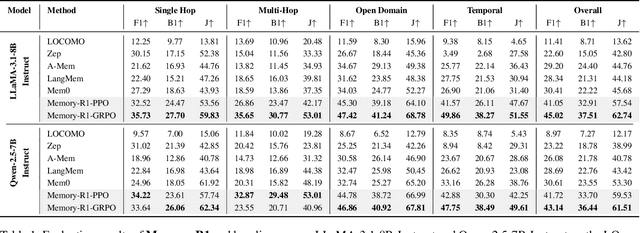
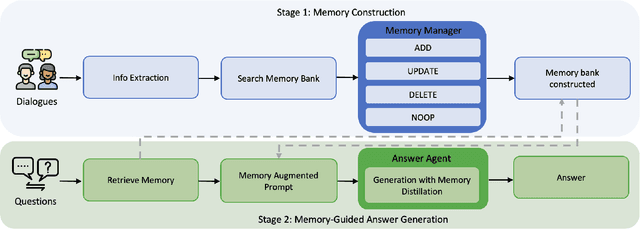

Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking any learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns to perform structured memory operations {ADD, UPDATE, DELETE, NOOP}, and an Answer Agent that selects the most relevant entries and reasons over them to produce an answer. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management and use with minimal supervision. With as few as 152 question-answer pairs and a corresponding temporal memory bank for training, Memory-R1 outperforms the most competitive existing baseline and demonstrates strong generalization across diverse question types and LLM backbones. Beyond presenting an effective approach, this work provides insights into how RL can unlock more agentic, memory-aware behaviors in LLMs, pointing toward richer, more persistent reasoning systems.
Why Uncertainty Calibration Matters for Reliable Perturbation-based Explanations
Jun 24, 2025Perturbation-based explanations are widely utilized to enhance the transparency of modern machine-learning models. However, their reliability is often compromised by the unknown model behavior under the specific perturbations used. This paper investigates the relationship between uncertainty calibration - the alignment of model confidence with actual accuracy - and perturbation-based explanations. We show that models frequently produce unreliable probability estimates when subjected to explainability-specific perturbations and theoretically prove that this directly undermines explanation quality. To address this, we introduce ReCalX, a novel approach to recalibrate models for improved perturbation-based explanations while preserving their original predictions. Experiments on popular computer vision models demonstrate that our calibration strategy produces explanations that are more aligned with human perception and actual object locations.
SwarmAgentic: Towards Fully Automated Agentic System Generation via Swarm Intelligence
Jun 18, 2025The rapid progress of Large Language Models has advanced agentic systems in decision-making, coordination, and task execution. Yet, existing agentic system generation frameworks lack full autonomy, missing from-scratch agent generation, self-optimizing agent functionality, and collaboration, limiting adaptability and scalability. We propose SwarmAgentic, a framework for fully automated agentic system generation that constructs agentic systems from scratch and jointly optimizes agent functionality and collaboration as interdependent components through language-driven exploration. To enable efficient search over system-level structures, SwarmAgentic maintains a population of candidate systems and evolves them via feedback-guided updates, drawing inspiration from Particle Swarm Optimization (PSO). We evaluate our method on six real-world, open-ended, and exploratory tasks involving high-level planning, system-level coordination, and creative reasoning. Given only a task description and an objective function, SwarmAgentic outperforms all baselines, achieving a +261.8% relative improvement over ADAS on the TravelPlanner benchmark, highlighting the effectiveness of full automation in structurally unconstrained tasks. This framework marks a significant step toward scalable and autonomous agentic system design, bridging swarm intelligence with fully automated system multi-agent generation. Our code is publicly released at https://yaoz720.github.io/SwarmAgentic/.
Agentic Neural Networks: Self-Evolving Multi-Agent Systems via Textual Backpropagation
Jun 10, 2025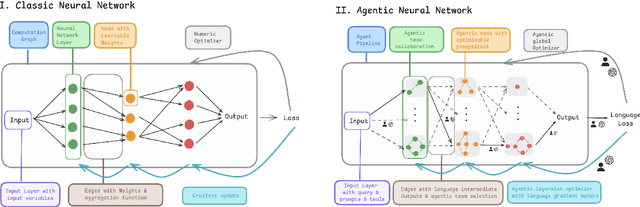

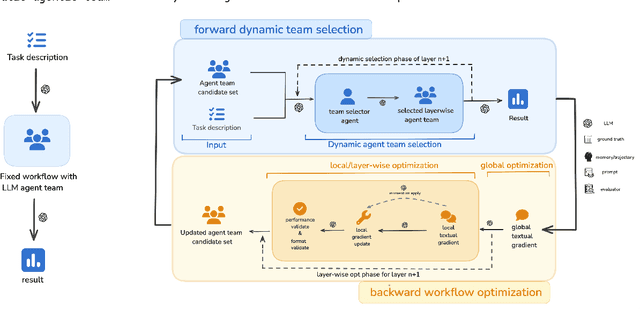
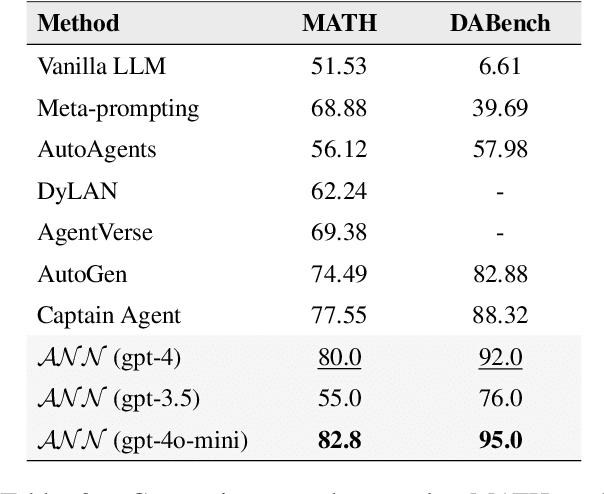
Leveraging multiple Large Language Models(LLMs) has proven effective for addressing complex, high-dimensional tasks, but current approaches often rely on static, manually engineered multi-agent configurations. To overcome these constraints, we present the Agentic Neural Network(ANN), a framework that conceptualizes multi-agent collaboration as a layered neural network architecture. In this design, each agent operates as a node, and each layer forms a cooperative "team" focused on a specific subtask. Agentic Neural Network follows a two-phase optimization strategy: (1) Forward Phase-Drawing inspiration from neural network forward passes, tasks are dynamically decomposed into subtasks, and cooperative agent teams with suitable aggregation methods are constructed layer by layer. (2) Backward Phase-Mirroring backpropagation, we refine both global and local collaboration through iterative feedback, allowing agents to self-evolve their roles, prompts, and coordination. This neuro-symbolic approach enables ANN to create new or specialized agent teams post-training, delivering notable gains in accuracy and adaptability. Across four benchmark datasets, ANN surpasses leading multi-agent baselines under the same configurations, showing consistent performance improvements. Our findings indicate that ANN provides a scalable, data-driven framework for multi-agent systems, combining the collaborative capabilities of LLMs with the efficiency and flexibility of neural network principles. We plan to open-source the entire framework.
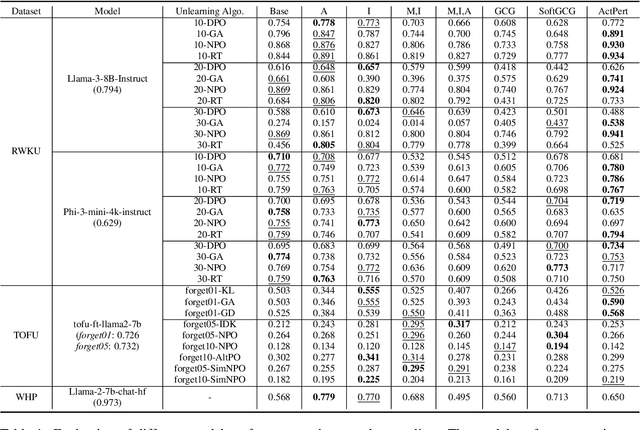
Does Machine Unlearning Truly Remove Model Knowledge? A Framework for Auditing Unlearning in LLMs
May 29, 2025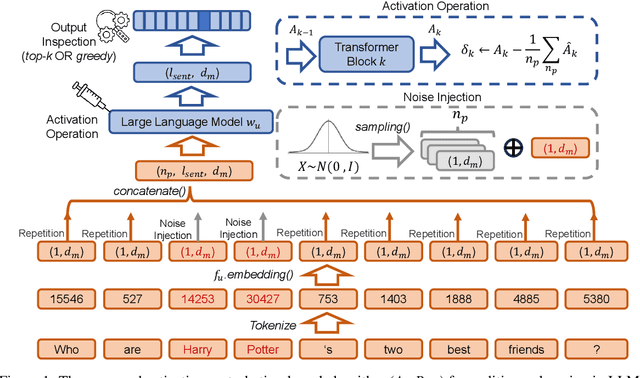
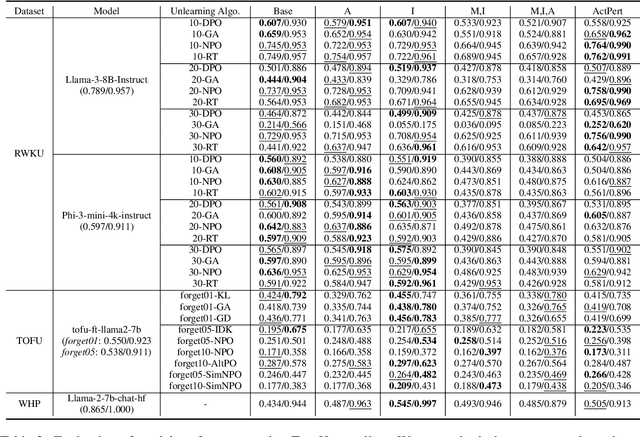
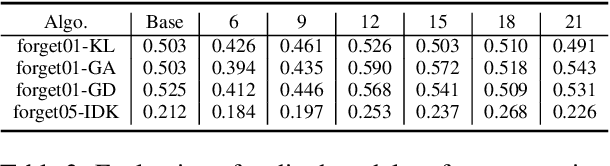
In recent years, Large Language Models (LLMs) have achieved remarkable advancements, drawing significant attention from the research community. Their capabilities are largely attributed to large-scale architectures, which require extensive training on massive datasets. However, such datasets often contain sensitive or copyrighted content sourced from the public internet, raising concerns about data privacy and ownership. Regulatory frameworks, such as the General Data Protection Regulation (GDPR), grant individuals the right to request the removal of such sensitive information. This has motivated the development of machine unlearning algorithms that aim to remove specific knowledge from models without the need for costly retraining. Despite these advancements, evaluating the efficacy of unlearning algorithms remains a challenge due to the inherent complexity and generative nature of LLMs. In this work, we introduce a comprehensive auditing framework for unlearning evaluation, comprising three benchmark datasets, six unlearning algorithms, and five prompt-based auditing methods. By using various auditing algorithms, we evaluate the effectiveness and robustness of different unlearning strategies. To explore alternatives beyond prompt-based auditing, we propose a novel technique that leverages intermediate activation perturbations, addressing the limitations of auditing methods that rely solely on model inputs and outputs.
CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
May 19, 2025Recent Large Reasoning Models significantly improve the reasoning ability of Large Language Models by learning to reason, exhibiting the promising performance in solving complex tasks. LRMs solve tasks that require complex reasoning by explicitly generating reasoning trajectories together with answers. Nevertheless, judging the quality of such an output answer is not easy because only considering the correctness of the answer is not enough and the soundness of the reasoning trajectory part matters as well. Logically, if the soundness of the reasoning part is poor, even if the answer is correct, the confidence of the derived answer should be low. Existing methods did consider jointly assessing the overall output answer by taking into account the reasoning part, however, their capability is still not satisfactory as the causal relationship of the reasoning to the concluded answer cannot properly reflected. In this paper, inspired by classical mechanics, we present a novel approach towards establishing a CoT-Kinetics energy equation. Specifically, our CoT-Kinetics energy equation formulates the token state transformation process, which is regulated by LRM internal transformer layers, as like a particle kinetics dynamics governed in a mechanical field. Our CoT-Kinetics energy assigns a scalar score to evaluate specifically the soundness of the reasoning phase, telling how confident the derived answer could be given the evaluated reasoning. As such, the LRM's overall output quality can be accurately measured, rather than a coarse judgment (e.g., correct or incorrect) anymore.
Incremental Uncertainty-aware Performance Monitoring with Active Labeling Intervention
May 11, 2025We study the problem of monitoring machine learning models under gradual distribution shifts, where circumstances change slowly over time, often leading to unnoticed yet significant declines in accuracy. To address this, we propose Incremental Uncertainty-aware Performance Monitoring (IUPM), a novel label-free method that estimates performance changes by modeling gradual shifts using optimal transport. In addition, IUPM quantifies the uncertainty in the performance prediction and introduces an active labeling procedure to restore a reliable estimate under a limited labeling budget. Our experiments show that IUPM outperforms existing performance estimation baselines in various gradual shift scenarios and that its uncertainty awareness guides label acquisition more effectively compared to other strategies.