 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUVIC: Adversarial Unlearning of Visual Concepts for Multi-modal Large Language Models
Nov 14, 2025Multimodal Large Language Models (MLLMs) achieve impressive performance once optimized on massive datasets. Such datasets often contain sensitive or copyrighted content, raising significant data privacy concerns. Regulatory frameworks mandating the 'right to be forgotten' drive the need for machine unlearning. This technique allows for the removal of target data without resource-consuming retraining. However, while well-studied for text, visual concept unlearning in MLLMs remains underexplored. A primary challenge is precisely removing a target visual concept without disrupting model performance on related entities. To address this, we introduce AUVIC, a novel visual concept unlearning framework for MLLMs. AUVIC applies adversarial perturbations to enable precise forgetting. This approach effectively isolates the target concept while avoiding unintended effects on similar entities. To evaluate our method, we construct VCUBench. It is the first benchmark designed to assess visual concept unlearning in group contexts. Experimental results demonstrate that AUVIC achieves state-of-the-art target forgetting rates while incurs minimal performance degradation on non-target concepts.
SwarmAgentic: Towards Fully Automated Agentic System Generation via Swarm Intelligence
Jun 18, 2025The rapid progress of Large Language Models has advanced agentic systems in decision-making, coordination, and task execution. Yet, existing agentic system generation frameworks lack full autonomy, missing from-scratch agent generation, self-optimizing agent functionality, and collaboration, limiting adaptability and scalability. We propose SwarmAgentic, a framework for fully automated agentic system generation that constructs agentic systems from scratch and jointly optimizes agent functionality and collaboration as interdependent components through language-driven exploration. To enable efficient search over system-level structures, SwarmAgentic maintains a population of candidate systems and evolves them via feedback-guided updates, drawing inspiration from Particle Swarm Optimization (PSO). We evaluate our method on six real-world, open-ended, and exploratory tasks involving high-level planning, system-level coordination, and creative reasoning. Given only a task description and an objective function, SwarmAgentic outperforms all baselines, achieving a +261.8% relative improvement over ADAS on the TravelPlanner benchmark, highlighting the effectiveness of full automation in structurally unconstrained tasks. This framework marks a significant step toward scalable and autonomous agentic system design, bridging swarm intelligence with fully automated system multi-agent generation. Our code is publicly released at https://yaoz720.github.io/SwarmAgentic/.
Does Machine Unlearning Truly Remove Model Knowledge? A Framework for Auditing Unlearning in LLMs
May 29, 2025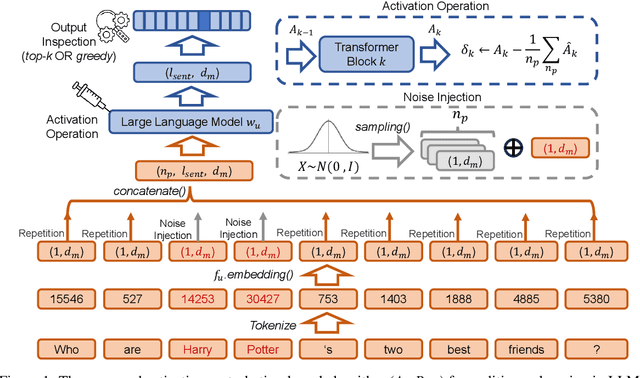
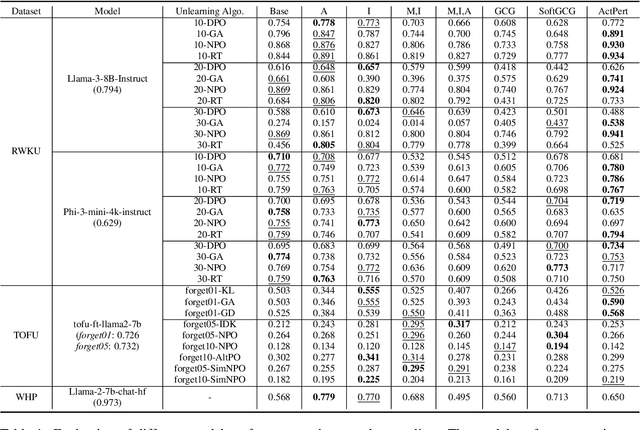
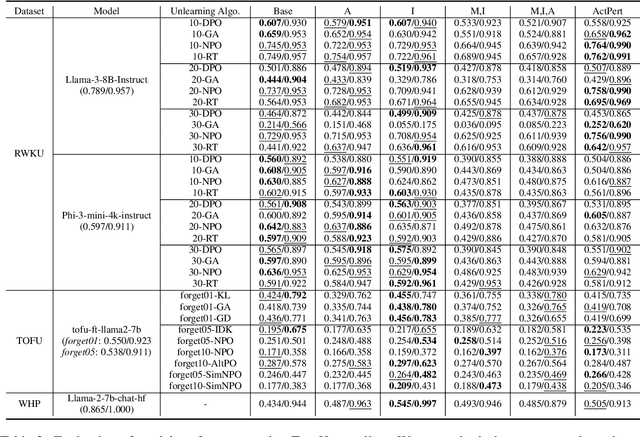
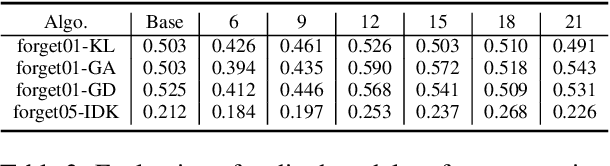
In recent years, Large Language Models (LLMs) have achieved remarkable advancements, drawing significant attention from the research community. Their capabilities are largely attributed to large-scale architectures, which require extensive training on massive datasets. However, such datasets often contain sensitive or copyrighted content sourced from the public internet, raising concerns about data privacy and ownership. Regulatory frameworks, such as the General Data Protection Regulation (GDPR), grant individuals the right to request the removal of such sensitive information. This has motivated the development of machine unlearning algorithms that aim to remove specific knowledge from models without the need for costly retraining. Despite these advancements, evaluating the efficacy of unlearning algorithms remains a challenge due to the inherent complexity and generative nature of LLMs. In this work, we introduce a comprehensive auditing framework for unlearning evaluation, comprising three benchmark datasets, six unlearning algorithms, and five prompt-based auditing methods. By using various auditing algorithms, we evaluate the effectiveness and robustness of different unlearning strategies. To explore alternatives beyond prompt-based auditing, we propose a novel technique that leverages intermediate activation perturbations, addressing the limitations of auditing methods that rely solely on model inputs and outputs.
My Answer Is NOT 'Fair': Mitigating Social Bias in Vision-Language Models via Fair and Biased Residuals
May 26, 2025



Social bias is a critical issue in large vision-language models (VLMs), where fairness- and ethics-related problems harm certain groups of people in society. It is unknown to what extent VLMs yield social bias in generative responses. In this study, we focus on evaluating and mitigating social bias on both the model's response and probability distribution. To do so, we first evaluate four state-of-the-art VLMs on PAIRS and SocialCounterfactuals datasets with the multiple-choice selection task. Surprisingly, we find that models suffer from generating gender-biased or race-biased responses. We also observe that models are prone to stating their responses are fair, but indeed having mis-calibrated confidence levels towards particular social groups. While investigating why VLMs are unfair in this study, we observe that VLMs' hidden layers exhibit substantial fluctuations in fairness levels. Meanwhile, residuals in each layer show mixed effects on fairness, with some contributing positively while some lead to increased bias. Based on these findings, we propose a post-hoc method for the inference stage to mitigate social bias, which is training-free and model-agnostic. We achieve this by ablating bias-associated residuals while amplifying fairness-associated residuals on model hidden layers during inference. We demonstrate that our post-hoc method outperforms the competing training strategies, helping VLMs have fairer responses and more reliable confidence levels.
CoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
May 19, 2025Recent Large Reasoning Models significantly improve the reasoning ability of Large Language Models by learning to reason, exhibiting the promising performance in solving complex tasks. LRMs solve tasks that require complex reasoning by explicitly generating reasoning trajectories together with answers. Nevertheless, judging the quality of such an output answer is not easy because only considering the correctness of the answer is not enough and the soundness of the reasoning trajectory part matters as well. Logically, if the soundness of the reasoning part is poor, even if the answer is correct, the confidence of the derived answer should be low. Existing methods did consider jointly assessing the overall output answer by taking into account the reasoning part, however, their capability is still not satisfactory as the causal relationship of the reasoning to the concluded answer cannot properly reflected. In this paper, inspired by classical mechanics, we present a novel approach towards establishing a CoT-Kinetics energy equation. Specifically, our CoT-Kinetics energy equation formulates the token state transformation process, which is regulated by LRM internal transformer layers, as like a particle kinetics dynamics governed in a mechanical field. Our CoT-Kinetics energy assigns a scalar score to evaluate specifically the soundness of the reasoning phase, telling how confident the derived answer could be given the evaluated reasoning. As such, the LRM's overall output quality can be accurately measured, rather than a coarse judgment (e.g., correct or incorrect) anymore.
EmoAgent: Multi-Agent Collaboration of Plan, Edit, and Critic, for Affective Image Manipulation
Mar 14, 2025



Affective Image Manipulation (AIM) aims to alter an image's emotional impact by adjusting multiple visual elements to evoke specific feelings.Effective AIM is inherently complex, necessitating a collaborative approach that involves identifying semantic cues within source images, manipulating these elements to elicit desired emotional responses, and verifying that the combined adjustments successfully evoke the target emotion.To address these challenges, we introduce EmoAgent, the first multi-agent collaboration framework for AIM. By emulating the cognitive behaviors of a human painter, EmoAgent incorporates three specialized agents responsible for planning, editing, and critical evaluation. Furthermore, we develop an emotion-factor knowledge retriever, a decision-making tree space, and a tool library to enhance EmoAgent's effectiveness in handling AIM. Experiments demonstrate that the proposed multi-agent framework outperforms existing methods, offering more reasonable and effective emotional expression.
Soft Token Attacks Cannot Reliably Audit Unlearning in Large Language Models
Feb 20, 2025Large language models (LLMs) have become increasingly popular. Their emergent capabilities can be attributed to their massive training datasets. However, these datasets often contain undesirable or inappropriate content, e.g., harmful texts, personal information, and copyrighted material. This has promoted research into machine unlearning that aims to remove information from trained models. In particular, approximate unlearning seeks to achieve information removal by strategically editing the model rather than complete model retraining. Recent work has shown that soft token attacks (STA) can successfully extract purportedly unlearned information from LLMs, thereby exposing limitations in current unlearning methodologies. In this work, we reveal that STAs are an inadequate tool for auditing unlearning. Through systematic evaluation on common unlearning benchmarks (Who Is Harry Potter? and TOFU), we demonstrate that such attacks can elicit any information from the LLM, regardless of (1) the deployed unlearning algorithm, and (2) whether the queried content was originally present in the training corpus. Furthermore, we show that STA with just a few soft tokens (1-10) can elicit random strings over 400-characters long. Thus showing that STAs are too powerful, and misrepresent the effectiveness of the unlearning methods. Our work highlights the need for better evaluation baselines, and more appropriate auditing tools for assessing the effectiveness of unlearning in LLMs.
Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
Dec 16, 2024



Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.
FedBiP: Heterogeneous One-Shot Federated Learning with Personalized Latent Diffusion Models
Oct 07, 2024



One-Shot Federated Learning (OSFL), a special decentralized machine learning paradigm, has recently gained significant attention. OSFL requires only a single round of client data or model upload, which reduces communication costs and mitigates privacy threats compared to traditional FL. Despite these promising prospects, existing methods face challenges due to client data heterogeneity and limited data quantity when applied to real-world OSFL systems. Recently, Latent Diffusion Models (LDM) have shown remarkable advancements in synthesizing high-quality images through pretraining on large-scale datasets, thereby presenting a potential solution to overcome these issues. However, directly applying pretrained LDM to heterogeneous OSFL results in significant distribution shifts in synthetic data, leading to performance degradation in classification models trained on such data. This issue is particularly pronounced in rare domains, such as medical imaging, which are underrepresented in LDM's pretraining data. To address this challenge, we propose Federated Bi-Level Personalization (FedBiP), which personalizes the pretrained LDM at both instance-level and concept-level. Hereby, FedBiP synthesizes images following the client's local data distribution without compromising the privacy regulations. FedBiP is also the first approach to simultaneously address feature space heterogeneity and client data scarcity in OSFL. Our method is validated through extensive experiments on three OSFL benchmarks with feature space heterogeneity, as well as on challenging medical and satellite image datasets with label heterogeneity. The results demonstrate the effectiveness of FedBiP, which substantially outperforms other OSFL methods.
DiffsFormer: A Diffusion Transformer on Stock Factor Augmentation
Feb 05, 2024



Machine learning models have demonstrated remarkable efficacy and efficiency in a wide range of stock forecasting tasks. However, the inherent challenges of data scarcity, including low signal-to-noise ratio (SNR) and data homogeneity, pose significant obstacles to accurate forecasting. To address this issue, we propose a novel approach that utilizes artificial intelligence-generated samples (AIGS) to enhance the training procedures. In our work, we introduce the Diffusion Model to generate stock factors with Transformer architecture (DiffsFormer). DiffsFormer is initially trained on a large-scale source domain, incorporating conditional guidance so as to capture global joint distribution. When presented with a specific downstream task, we employ DiffsFormer to augment the training procedure by editing existing samples. This editing step allows us to control the strength of the editing process, determining the extent to which the generated data deviates from the target domain. To evaluate the effectiveness of DiffsFormer augmented training, we conduct experiments on the CSI300 and CSI800 datasets, employing eight commonly used machine learning models. The proposed method achieves relative improvements of 7.2% and 27.8% in annualized return ratio for the respective datasets. Furthermore, we perform extensive experiments to gain insights into the functionality of DiffsFormer and its constituent components, elucidating how they address the challenges of data scarcity and enhance the overall model performance. Our research demonstrates the efficacy of leveraging AIGS and the DiffsFormer architecture to mitigate data scarcity in stock forecasting tasks.