 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025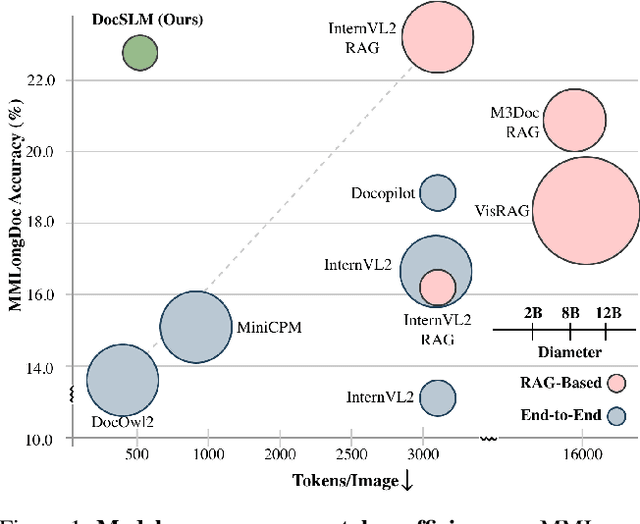

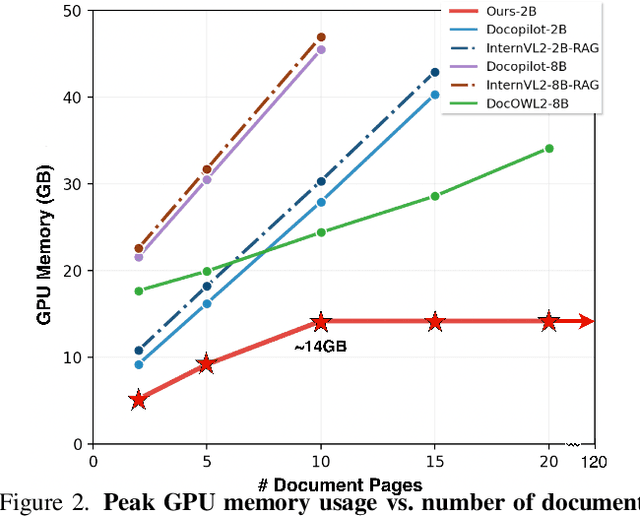
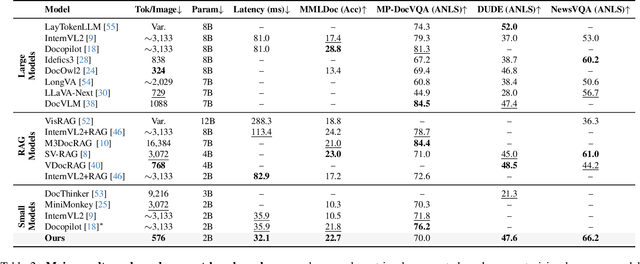
Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
My Answer Is NOT 'Fair': Mitigating Social Bias in Vision-Language Models via Fair and Biased Residuals
May 26, 2025Social bias is a critical issue in large vision-language models (VLMs), where fairness- and ethics-related problems harm certain groups of people in society. It is unknown to what extent VLMs yield social bias in generative responses. In this study, we focus on evaluating and mitigating social bias on both the model's response and probability distribution. To do so, we first evaluate four state-of-the-art VLMs on PAIRS and SocialCounterfactuals datasets with the multiple-choice selection task. Surprisingly, we find that models suffer from generating gender-biased or race-biased responses. We also observe that models are prone to stating their responses are fair, but indeed having mis-calibrated confidence levels towards particular social groups. While investigating why VLMs are unfair in this study, we observe that VLMs' hidden layers exhibit substantial fluctuations in fairness levels. Meanwhile, residuals in each layer show mixed effects on fairness, with some contributing positively while some lead to increased bias. Based on these findings, we propose a post-hoc method for the inference stage to mitigate social bias, which is training-free and model-agnostic. We achieve this by ablating bias-associated residuals while amplifying fairness-associated residuals on model hidden layers during inference. We demonstrate that our post-hoc method outperforms the competing training strategies, helping VLMs have fairer responses and more reliable confidence levels.
ReVisionLLM: Recursive Vision-Language Model for Temporal Grounding in Hour-Long Videos
Nov 22, 2024



Large language models (LLMs) excel at retrieving information from lengthy text, but their vision-language counterparts (VLMs) face difficulties with hour-long videos, especially for temporal grounding. Specifically, these VLMs are constrained by frame limitations, often losing essential temporal details needed for accurate event localization in extended video content. We propose ReVisionLLM, a recursive vision-language model designed to locate events in hour-long videos. Inspired by human search strategies, our model initially targets broad segments of interest, progressively revising its focus to pinpoint exact temporal boundaries. Our model can seamlessly handle videos of vastly different lengths, from minutes to hours. We also introduce a hierarchical training strategy that starts with short clips to capture distinct events and progressively extends to longer videos. To our knowledge, ReVisionLLM is the first VLM capable of temporal grounding in hour-long videos, outperforming previous state-of-the-art methods across multiple datasets by a significant margin (+2.6% R1@0.1 on MAD). The code is available at https://github.com/Tanveer81/ReVisionLLM.
Context Matters: Leveraging Spatiotemporal Metadata for Semi-Supervised Learning on Remote Sensing Images
Apr 29, 2024Remote sensing projects typically generate large amounts of imagery that can be used to train powerful deep neural networks. However, the amount of labeled images is often small, as remote sensing applications generally require expert labelers. Thus, semi-supervised learning (SSL), i.e., learning with a small pool of labeled and a larger pool of unlabeled data, is particularly useful in this domain. Current SSL approaches generate pseudo-labels from model predictions for unlabeled samples. As the quality of these pseudo-labels is crucial for performance, utilizing additional information to improve pseudo-label quality yields a promising direction. For remote sensing images, geolocation and recording time are generally available and provide a valuable source of information as semantic concepts, such as land cover, are highly dependent on spatiotemporal context, e.g., due to seasonal effects and vegetation zones. In this paper, we propose to exploit spatiotemporal metainformation in SSL to improve the quality of pseudo-labels and, therefore, the final model performance. We show that directly adding the available metadata to the input of the predictor at test time degenerates the prediction quality for metadata outside the spatiotemporal distribution of the training set. Thus, we propose a teacher-student SSL framework where only the teacher network uses metainformation to improve the quality of pseudo-labels on the training set. Correspondingly, our student network benefits from the improved pseudo-labels but does not receive metadata as input, making it invariant to spatiotemporal shifts at test time. Furthermore, we propose methods for encoding and injecting spatiotemporal information into the model and introduce a novel distillation mechanism to enhance the knowledge transfer between teacher and student. Our framework dubbed Spatiotemporal SSL can be easily combined with several stat...
RGNet: A Unified Retrieval and Grounding Network for Long Videos
Dec 11, 2023We present a novel end-to-end method for long-form video temporal grounding to locate specific moments described by natural language queries. Prior long-video methods for this task typically contain two stages: proposal selection and grounding regression. However, the proposal selection of these methods is disjoint from the grounding network and is not trained end-to-end, which limits the effectiveness of these methods. Moreover, these methods operate uniformly over the entire temporal window, which is suboptimal given redundant and irrelevant features in long videos. In contrast to these prior approaches, we introduce RGNet, a unified network designed for jointly selecting proposals from hour-long videos and locating moments specified by natural language queries within them. To achieve this, we redefine proposal selection as a video-text retrieval task, i.e., retrieving the correct candidate videos given a text query. The core component of RGNet is a unified cross-modal RG-Encoder that bridges the two stages with shared features and mutual optimization. The encoder strategically focuses on relevant time frames using a sparse sampling technique. RGNet outperforms previous methods, demonstrating state-of-the-art performance on long video temporal grounding datasets MAD and Ego4D. The code is released at https://github.com/Tanveer81/RGNet
GRAtt-VIS: Gated Residual Attention for Auto Rectifying Video Instance Segmentation
May 26, 2023Recent trends in Video Instance Segmentation (VIS) have seen a growing reliance on online methods to model complex and lengthy video sequences. However, the degradation of representation and noise accumulation of the online methods, especially during occlusion and abrupt changes, pose substantial challenges. Transformer-based query propagation provides promising directions at the cost of quadratic memory attention. However, they are susceptible to the degradation of instance features due to the above-mentioned challenges and suffer from cascading effects. The detection and rectification of such errors remain largely underexplored. To this end, we introduce \textbf{GRAtt-VIS}, \textbf{G}ated \textbf{R}esidual \textbf{Att}ention for \textbf{V}ideo \textbf{I}nstance \textbf{S}egmentation. Firstly, we leverage a Gumbel-Softmax-based gate to detect possible errors in the current frame. Next, based on the gate activation, we rectify degraded features from its past representation. Such a residual configuration alleviates the need for dedicated memory and provides a continuous stream of relevant instance features. Secondly, we propose a novel inter-instance interaction using gate activation as a mask for self-attention. This masking strategy dynamically restricts the unrepresentative instance queries in the self-attention and preserves vital information for long-term tracking. We refer to this novel combination of Gated Residual Connection and Masked Self-Attention as \textbf{GRAtt} block, which can easily be integrated into the existing propagation-based framework. Further, GRAtt blocks significantly reduce the attention overhead and simplify dynamic temporal modeling. GRAtt-VIS achieves state-of-the-art performance on YouTube-VIS and the highly challenging OVIS dataset, significantly improving over previous methods. Code is available at \url{https://github.com/Tanveer81/GRAttVIS}.
InstanceFormer: An Online Video Instance Segmentation Framework
Aug 22, 2022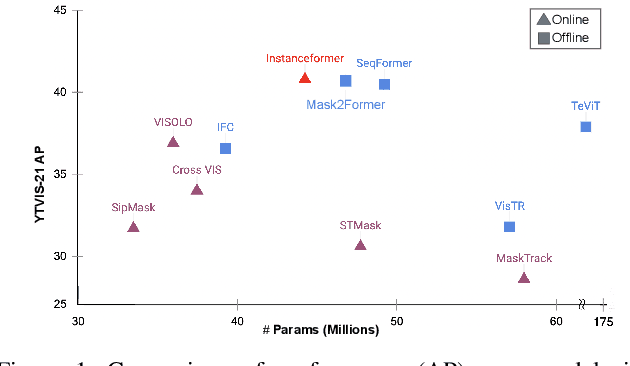
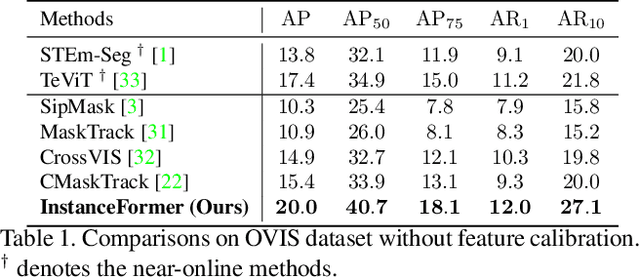
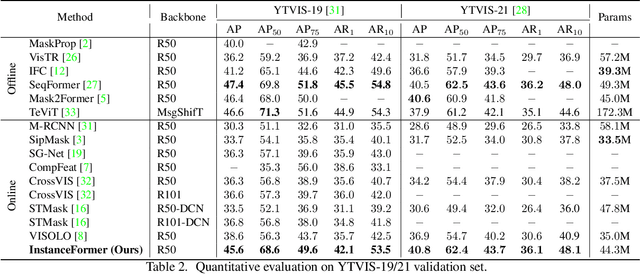
Recent transformer-based offline video instance segmentation (VIS) approaches achieve encouraging results and significantly outperform online approaches. However, their reliance on the whole video and the immense computational complexity caused by full Spatio-temporal attention limit them in real-life applications such as processing lengthy videos. In this paper, we propose a single-stage transformer-based efficient online VIS framework named InstanceFormer, which is especially suitable for long and challenging videos. We propose three novel components to model short-term and long-term dependency and temporal coherence. First, we propagate the representation, location, and semantic information of prior instances to model short-term changes. Second, we propose a novel memory cross-attention in the decoder, which allows the network to look into earlier instances within a certain temporal window. Finally, we employ a temporal contrastive loss to impose coherence in the representation of an instance across all frames. Memory attention and temporal coherence are particularly beneficial to long-range dependency modeling, including challenging scenarios like occlusion. The proposed InstanceFormer outperforms previous online benchmark methods by a large margin across multiple datasets. Most importantly, InstanceFormer surpasses offline approaches for challenging and long datasets such as YouTube-VIS-2021 and OVIS. Code is available at https://github.com/rajatkoner08/InstanceFormer.
Box Supervised Video Segmentation Proposal Network
Feb 16, 2022
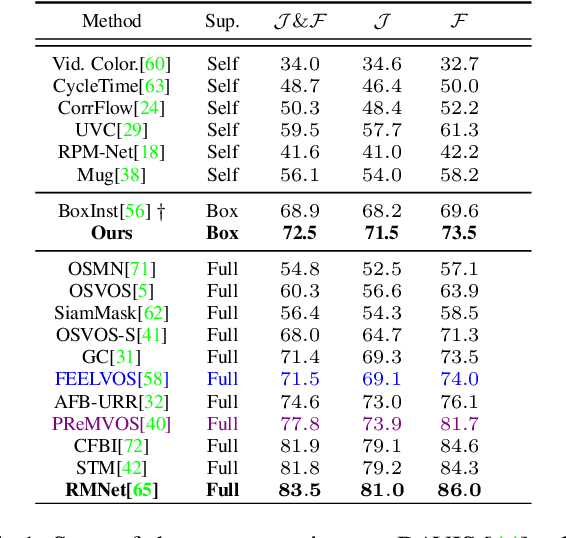
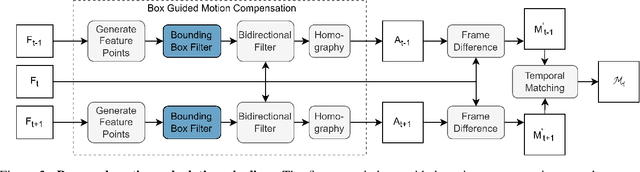
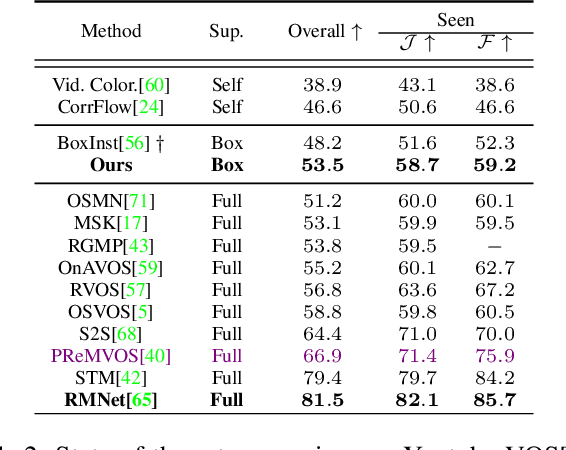
Video Object Segmentation (VOS) has been targeted by various fully-supervised and self-supervised approaches. While fully-supervised methods demonstrate excellent results, self-supervised ones, which do not use pixel-level ground truth, attract much attention. However, self-supervised approaches pose a significant performance gap. Box-level annotations provide a balanced compromise between labeling effort and result quality for image segmentation but have not been exploited for the video domain. In this work, we propose a box-supervised video object segmentation proposal network, which takes advantage of intrinsic video properties. Our method incorporates object motion in the following way: first, motion is computed using a bidirectional temporal difference and a novel bounding box-guided motion compensation. Second, we introduce a novel motion-aware affinity loss that encourages the network to predict positive pixel pairs if they share similar motion and color. The proposed method outperforms the state-of-the-art self-supervised benchmark by 16.4% and 6.9% $\mathcal{J}$ &$\mathcal{F}$ score and the majority of fully supervised methods on the DAVIS and Youtube-VOS dataset without imposing network architectural specifications. We provide extensive tests and ablations on the datasets, demonstrating the robustness of our method.
Prediction of soft proton intensities in the near-Earth space using machine learning
May 11, 2021
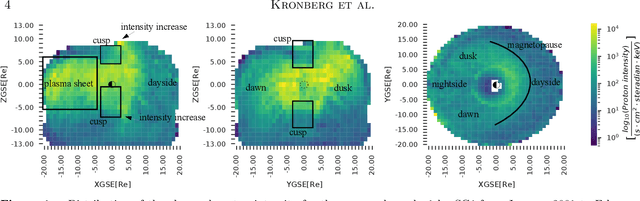
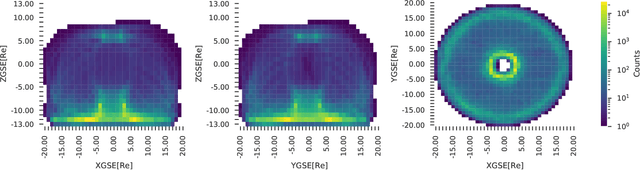

The spatial distribution of energetic protons contributes towards the understanding of magnetospheric dynamics. Based upon 17 years of the Cluster/RAPID observations, we have derived machine learning-based models to predict the proton intensities at energies from 28 to 1,885 keV in the 3D terrestrial magnetosphere at radial distances between 6 and 22 RE. We used the satellite location and indices for solar, solar wind and geomagnetic activity as predictors. The results demonstrate that the neural network (multi-layer perceptron regressor) outperforms baseline models based on the k-Nearest Neighbors and historical binning on average by ~80% and ~33\%, respectively. The average correlation between the observed and predicted data is about 56%, which is reasonable in light of the complex dynamics of fast-moving energetic protons in the magnetosphere. In addition to a quantitative analysis of the prediction results, we also investigate parameter importance in our model. The most decisive parameters for predicting proton intensities are related to the location: ZGSE direction and the radial distance. Among the activity indices, the solar wind dynamic pressure is the most important. The results have a direct practical application, for instance, for assessing the contamination particle background in the X-Ray telescopes for X-ray astronomy orbiting above the radiation belts. To foster reproducible research and to enable the community to build upon our work we publish our complete code, the data, as well as weights of trained models. Further description can be found in the GitHub project at https://github.com/Tanveer81/deep_horizon.