 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDying Clusters Is All You Need -- Deep Clustering With an Unknown Number of Clusters
Oct 12, 2024
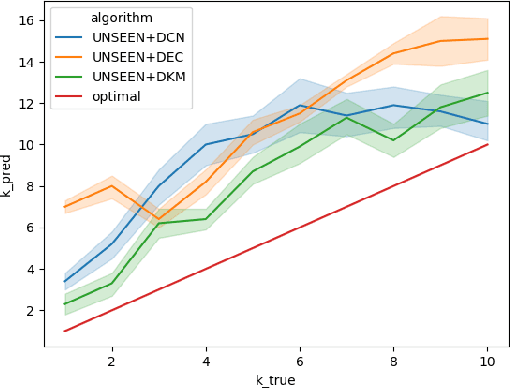


Finding meaningful groups, i.e., clusters, in high-dimensional data such as images or texts without labeled data at hand is an important challenge in data mining. In recent years, deep clustering methods have achieved remarkable results in these tasks. However, most of these methods require the user to specify the number of clusters in advance. This is a major limitation since the number of clusters is typically unknown if labeled data is unavailable. Thus, an area of research has emerged that addresses this problem. Most of these approaches estimate the number of clusters separated from the clustering process. This results in a strong dependency of the clustering result on the quality of the initial embedding. Other approaches are tailored to specific clustering processes, making them hard to adapt to other scenarios. In this paper, we propose UNSEEN, a general framework that, starting from a given upper bound, is able to estimate the number of clusters. To the best of our knowledge, it is the first method that can be easily combined with various deep clustering algorithms. We demonstrate the applicability of our approach by combining UNSEEN with the popular deep clustering algorithms DCN, DEC, and DKM and verify its effectiveness through an extensive experimental evaluation on several image and tabular datasets. Moreover, we perform numerous ablations to analyze our approach and show the importance of its components. The code is available at: https://github.com/collinleiber/UNSEEN
Autoregressive Policy Optimization for Constrained Allocation Tasks
Sep 27, 2024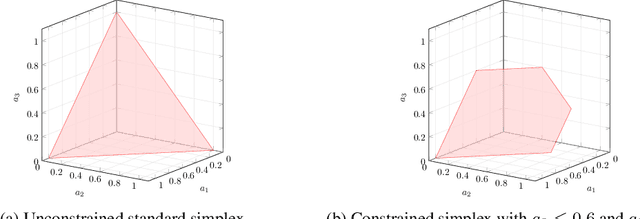
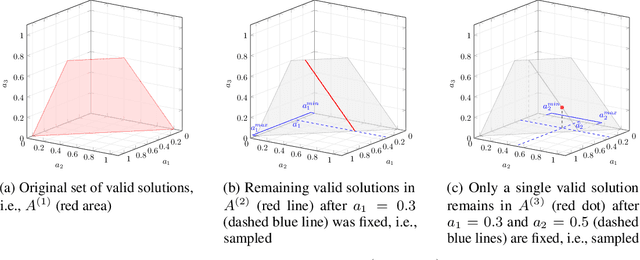
Allocation tasks represent a class of problems where a limited amount of resources must be allocated to a set of entities at each time step. Prominent examples of this task include portfolio optimization or distributing computational workloads across servers. Allocation tasks are typically bound by linear constraints describing practical requirements that have to be strictly fulfilled at all times. In portfolio optimization, for example, investors may be obligated to allocate less than 30\% of the funds into a certain industrial sector in any investment period. Such constraints restrict the action space of allowed allocations in intricate ways, which makes learning a policy that avoids constraint violations difficult. In this paper, we propose a new method for constrained allocation tasks based on an autoregressive process to sequentially sample allocations for each entity. In addition, we introduce a novel de-biasing mechanism to counter the initial bias caused by sequential sampling. We demonstrate the superior performance of our approach compared to a variety of Constrained Reinforcement Learning (CRL) methods on three distinct constrained allocation tasks: portfolio optimization, computational workload distribution, and a synthetic allocation benchmark. Our code is available at: https://github.com/niklasdbs/paspo
Context Matters: Leveraging Spatiotemporal Metadata for Semi-Supervised Learning on Remote Sensing Images
Apr 29, 2024Remote sensing projects typically generate large amounts of imagery that can be used to train powerful deep neural networks. However, the amount of labeled images is often small, as remote sensing applications generally require expert labelers. Thus, semi-supervised learning (SSL), i.e., learning with a small pool of labeled and a larger pool of unlabeled data, is particularly useful in this domain. Current SSL approaches generate pseudo-labels from model predictions for unlabeled samples. As the quality of these pseudo-labels is crucial for performance, utilizing additional information to improve pseudo-label quality yields a promising direction. For remote sensing images, geolocation and recording time are generally available and provide a valuable source of information as semantic concepts, such as land cover, are highly dependent on spatiotemporal context, e.g., due to seasonal effects and vegetation zones. In this paper, we propose to exploit spatiotemporal metainformation in SSL to improve the quality of pseudo-labels and, therefore, the final model performance. We show that directly adding the available metadata to the input of the predictor at test time degenerates the prediction quality for metadata outside the spatiotemporal distribution of the training set. Thus, we propose a teacher-student SSL framework where only the teacher network uses metainformation to improve the quality of pseudo-labels on the training set. Correspondingly, our student network benefits from the improved pseudo-labels but does not receive metadata as input, making it invariant to spatiotemporal shifts at test time. Furthermore, we propose methods for encoding and injecting spatiotemporal information into the model and introduce a novel distillation mechanism to enhance the knowledge transfer between teacher and student. Our framework dubbed Spatiotemporal SSL can be easily combined with several stat...
Efficient Parking Search using Shared Fleet Data
Apr 16, 2024Finding an available on-street parking spot is a relevant problem of day-to-day life. In recent years, cities such as Melbourne and San Francisco deployed sensors that provide real-time information about the occupation of parking spots. Finding a free parking spot in such a smart environment can be modeled and solved as a Markov decision process (MDP). The problem has to consider uncertainty as available parking spots might not remain available until arrival due to other vehicles also claiming spots in the meantime. Knowing the parking intention of every vehicle in the environment would eliminate this uncertainty. Unfortunately, it does currently not seem realistic to have such data from all vehicles. In contrast, acquiring data from a subset of vehicles or a vehicle fleet appears feasible and has the potential to reduce uncertainty. In this paper, we examine the question of how useful sharing data within a vehicle fleet might be for the search times of particular drivers. We use fleet data to better estimate the availability of parking spots at arrival. Since optimal solutions for large scenarios are infeasible, we base our method on approximate solutions, which have been shown to perform well in single-agent settings. Our experiments are conducted on a simulation using real-world and synthetic data from the city of Melbourne. The results indicate that fleet data can significantly reduce search times for an available parking spot.
* Long Version; published at 2021 22nd IEEE International Conference on Mobile Data Management (MDM)
Simplex Decomposition for Portfolio Allocation Constraints in Reinforcement Learning
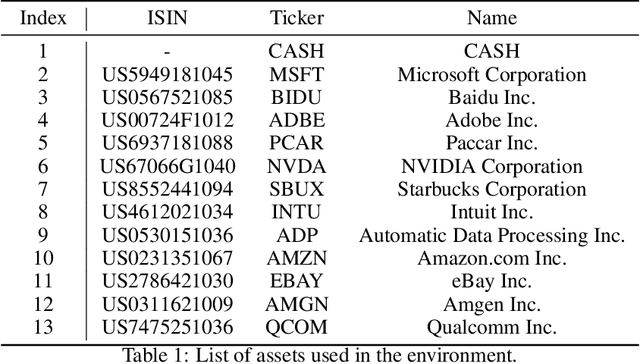
Apr 16, 2024Portfolio optimization tasks describe sequential decision problems in which the investor's wealth is distributed across a set of assets. Allocation constraints are used to enforce minimal or maximal investments into particular subsets of assets to control for objectives such as limiting the portfolio's exposure to a certain sector due to environmental concerns. Although methods for constrained Reinforcement Learning (CRL) can optimize policies while considering allocation constraints, it can be observed that these general methods yield suboptimal results. In this paper, we propose a novel approach to handle allocation constraints based on a decomposition of the constraint action space into a set of unconstrained allocation problems. In particular, we examine this approach for the case of two constraints. For example, an investor may wish to invest at least a certain percentage of the portfolio into green technologies while limiting the investment in the fossil energy sector. We show that the action space of the task is equivalent to the decomposed action space, and introduce a new reinforcement learning (RL) approach CAOSD, which is built on top of the decomposition. The experimental evaluation on real-world Nasdaq-100 data demonstrates that our approach consistently outperforms state-of-the-art CRL benchmarks for portfolio optimization.
Spatial-Aware Deep Reinforcement Learning for the Traveling Officer Problem
Jan 11, 2024The traveling officer problem (TOP) is a challenging stochastic optimization task. In this problem, a parking officer is guided through a city equipped with parking sensors to fine as many parking offenders as possible. A major challenge in TOP is the dynamic nature of parking offenses, which randomly appear and disappear after some time, regardless of whether they have been fined. Thus, solutions need to dynamically adjust to currently fineable parking offenses while also planning ahead to increase the likelihood that the officer arrives during the offense taking place. Though various solutions exist, these methods often struggle to take the implications of actions on the ability to fine future parking violations into account. This paper proposes SATOP, a novel spatial-aware deep reinforcement learning approach for TOP. Our novel state encoder creates a representation of each action, leveraging the spatial relationships between parking spots, the agent, and the action. Furthermore, we propose a novel message-passing module for learning future inter-action correlations in the given environment. Thus, the agent can estimate the potential to fine further parking violations after executing an action. We evaluate our method using an environment based on real-world data from Melbourne. Our results show that SATOP consistently outperforms state-of-the-art TOP agents and is able to fine up to 22% more parking offenses.
MapFormer: Boosting Change Detection by Using Pre-change Information
Mar 31, 2023
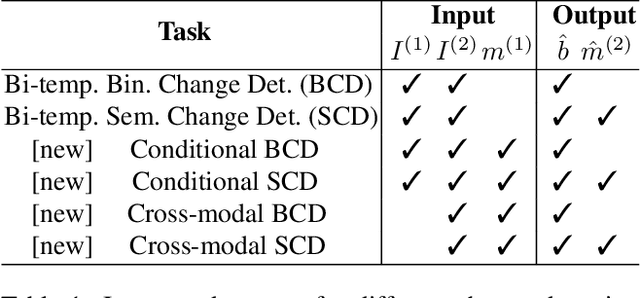

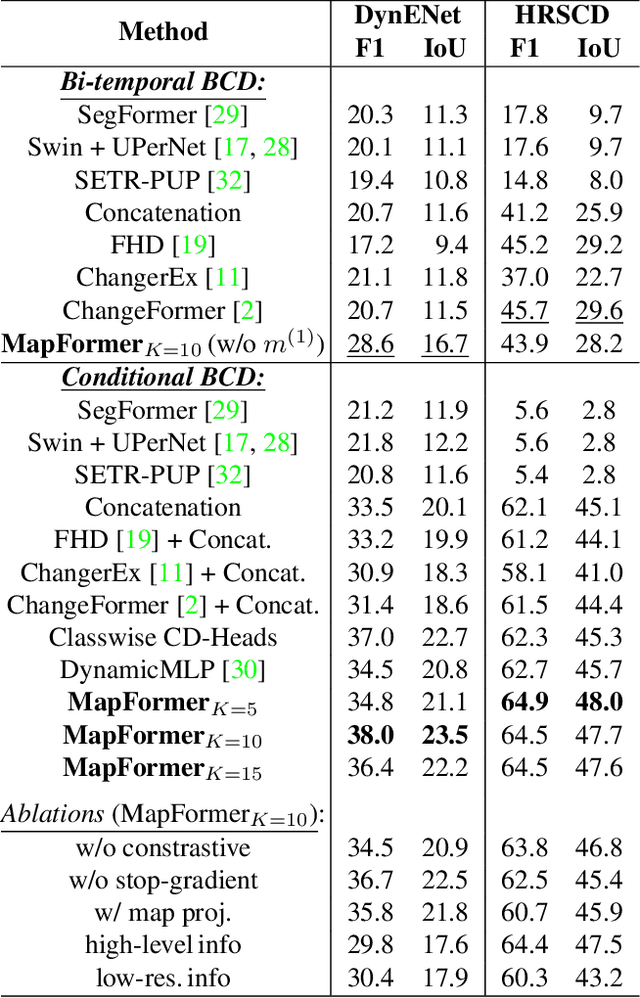
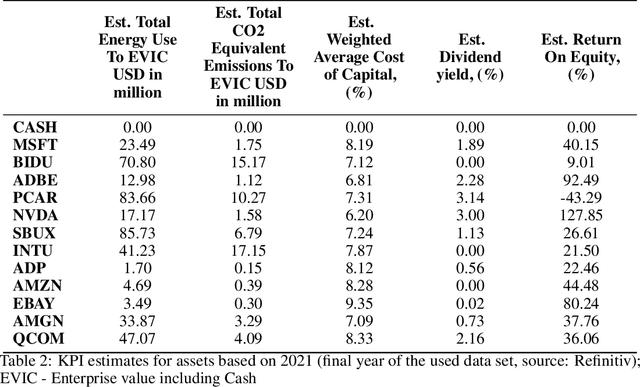
Change detection in remote sensing imagery is essential for a variety of applications such as urban planning, disaster management, and climate research. However, existing methods for identifying semantically changed areas overlook the availability of semantic information in the form of existing maps describing features of the earth's surface. In this paper, we leverage this information for change detection in bi-temporal images. We show that the simple integration of the additional information via concatenation of latent representations suffices to significantly outperform state-of-the-art change detection methods. Motivated by this observation, we propose the new task of Conditional Change Detection, where pre-change semantic information is used as input next to bi-temporal images. To fully exploit the extra information, we propose MapFormer, a novel architecture based on a multi-modal feature fusion module that allows for feature processing conditioned on the available semantic information. We further employ a supervised, cross-modal contrastive loss to guide the learning of visual representations. Our approach outperforms existing change detection methods by an absolute 11.7% and 18.4% in terms of binary change IoU on DynamicEarthNet and HRSCD, respectively. Furthermore, we demonstrate the robustness of our approach to the quality of the pre-change semantic information and the absence pre-change imagery. The code will be made publicly available.