 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introductory Survey to Autoencoder-based Deep Clustering -- Sandboxes for Combining Clustering with Deep Learning
Apr 02, 2025Autoencoders offer a general way of learning low-dimensional, non-linear representations from data without labels. This is achieved without making any particular assumptions about the data type or other domain knowledge. The generality and domain agnosticism in combination with their simplicity make autoencoders a perfect sandbox for researching and developing novel (deep) clustering algorithms. Clustering methods group data based on similarity, a task that benefits from the lower-dimensional representation learned by an autoencoder, mitigating the curse of dimensionality. Specifically, the combination of deep learning with clustering, called Deep Clustering, enables to learn a representation tailored to specific clustering tasks, leading to high-quality results. This survey provides an introduction to fundamental autoencoder-based deep clustering algorithms that serve as building blocks for many modern approaches.
Breaking the Reclustering Barrier in Centroid-based Deep Clustering
Nov 04, 2024



This work investigates an important phenomenon in centroid-based deep clustering (DC) algorithms: Performance quickly saturates after a period of rapid early gains. Practitioners commonly address early saturation with periodic reclustering, which we demonstrate to be insufficient to address performance plateaus. We call this phenomenon the "reclustering barrier" and empirically show when the reclustering barrier occurs, what its underlying mechanisms are, and how it is possible to Break the Reclustering Barrier with our algorithm BRB. BRB avoids early over-commitment to initial clusterings and enables continuous adaptation to reinitialized clustering targets while remaining conceptually simple. Applying our algorithm to widely-used centroid-based DC algorithms, we show that (1) BRB consistently improves performance across a wide range of clustering benchmarks, (2) BRB enables training from scratch, and (3) BRB performs competitively against state-of-the-art DC algorithms when combined with a contrastive loss. We release our code and pre-trained models at https://github.com/Probabilistic-and-Interactive-ML/breaking-the-reclustering-barrier .
Dying Clusters Is All You Need -- Deep Clustering With an Unknown Number of Clusters
Oct 12, 2024
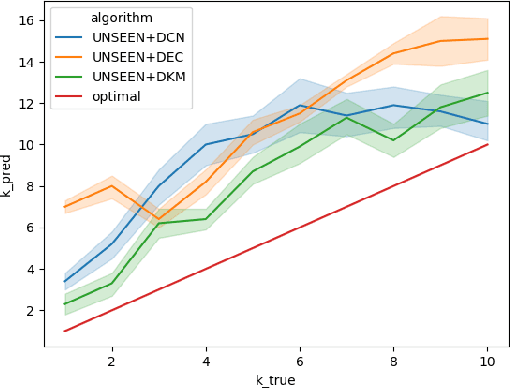


Finding meaningful groups, i.e., clusters, in high-dimensional data such as images or texts without labeled data at hand is an important challenge in data mining. In recent years, deep clustering methods have achieved remarkable results in these tasks. However, most of these methods require the user to specify the number of clusters in advance. This is a major limitation since the number of clusters is typically unknown if labeled data is unavailable. Thus, an area of research has emerged that addresses this problem. Most of these approaches estimate the number of clusters separated from the clustering process. This results in a strong dependency of the clustering result on the quality of the initial embedding. Other approaches are tailored to specific clustering processes, making them hard to adapt to other scenarios. In this paper, we propose UNSEEN, a general framework that, starting from a given upper bound, is able to estimate the number of clusters. To the best of our knowledge, it is the first method that can be easily combined with various deep clustering algorithms. We demonstrate the applicability of our approach by combining UNSEEN with the popular deep clustering algorithms DCN, DEC, and DKM and verify its effectiveness through an extensive experimental evaluation on several image and tabular datasets. Moreover, we perform numerous ablations to analyze our approach and show the importance of its components. The code is available at: https://github.com/collinleiber/UNSEEN
SHADE: Deep Density-based Clustering
Oct 08, 2024



Detecting arbitrarily shaped clusters in high-dimensional noisy data is challenging for current clustering methods. We introduce SHADE (Structure-preserving High-dimensional Analysis with Density-based Exploration), the first deep clustering algorithm that incorporates density-connectivity into its loss function. Similar to existing deep clustering algorithms, SHADE supports high-dimensional and large data sets with the expressive power of a deep autoencoder. In contrast to most existing deep clustering methods that rely on a centroid-based clustering objective, SHADE incorporates a novel loss function that captures density-connectivity. SHADE thereby learns a representation that enhances the separation of density-connected clusters. SHADE detects a stable clustering and noise points fully automatically without any user input. It outperforms existing methods in clustering quality, especially on data that contain non-Gaussian clusters, such as video data. Moreover, the embedded space of SHADE is suitable for visualization and interpretation of the clustering results as the individual shapes of the clusters are preserved.
Automatic Parameter Selection for Non-Redundant Clustering
Dec 19, 2023



High-dimensional datasets often contain multiple meaningful clusterings in different subspaces. For example, objects can be clustered either by color, weight, or size, revealing different interpretations of the given dataset. A variety of approaches are able to identify such non-redundant clusterings. However, most of these methods require the user to specify the expected number of subspaces and clusters for each subspace. Stating these values is a non-trivial problem and usually requires detailed knowledge of the input dataset. In this paper, we propose a framework that utilizes the Minimum Description Length Principle (MDL) to detect the number of subspaces and clusters per subspace automatically. We describe an efficient procedure that greedily searches the parameter space by splitting and merging subspaces and clusters within subspaces. Additionally, an encoding strategy is introduced that allows us to detect outliers in each subspace. Extensive experiments show that our approach is highly competitive to state-of-the-art methods.
Extension of the Dip-test Repertoire -- Efficient and Differentiable p-value Calculation for Clustering
Dec 19, 2023



Over the last decade, the Dip-test of unimodality has gained increasing interest in the data mining community as it is a parameter-free statistical test that reliably rates the modality in one-dimensional samples. It returns a so called Dip-value and a corresponding probability for the sample's unimodality (Dip-p-value). These two values share a sigmoidal relationship. However, the specific transformation is dependent on the sample size. Many Dip-based clustering algorithms use bootstrapped look-up tables translating Dip- to Dip-p-values for a certain limited amount of sample sizes. We propose a specifically designed sigmoid function as a substitute for these state-of-the-art look-up tables. This accelerates computation and provides an approximation of the Dip- to Dip-p-value transformation for every single sample size. Further, it is differentiable and can therefore easily be integrated in learning schemes using gradient descent. We showcase this by exploiting our function in a novel subspace clustering algorithm called Dip'n'Sub. We highlight in extensive experiments the various benefits of our proposal.