 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025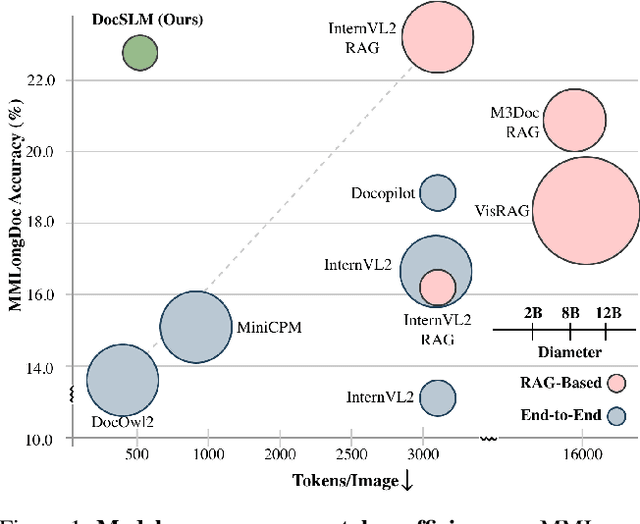

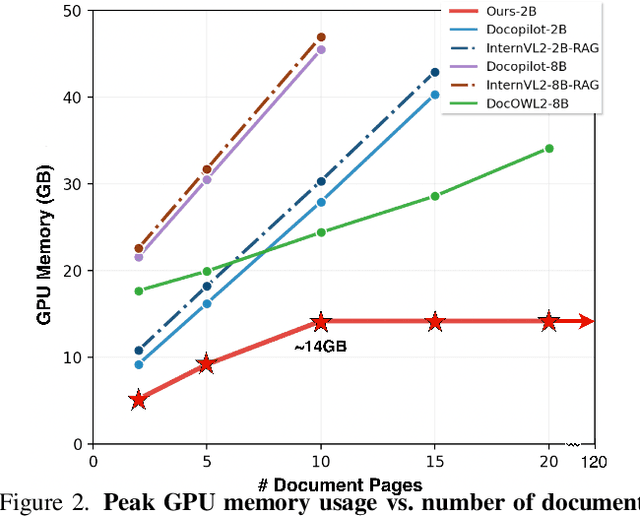
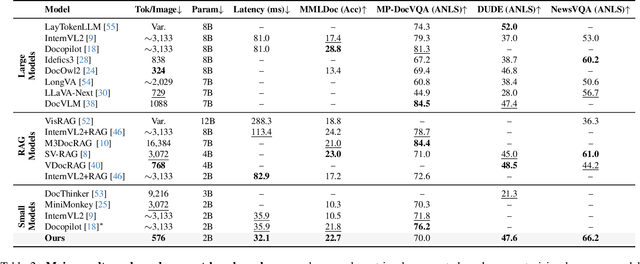
Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
PRSM: A Measure to Evaluate CLIP's Robustness Against Paraphrases
Nov 14, 2025Contrastive Language-Image Pre-training (CLIP) is a widely used multimodal model that aligns text and image representations through large-scale training. While it performs strongly on zero-shot and few-shot tasks, its robustness to linguistic variation, particularly paraphrasing, remains underexplored. Paraphrase robustness is essential for reliable deployment, especially in socially sensitive contexts where inconsistent representations can amplify demographic biases. In this paper, we introduce the Paraphrase Ranking Stability Metric (PRSM), a novel measure for quantifying CLIP's sensitivity to paraphrased queries. Using the Social Counterfactuals dataset, a benchmark designed to reveal social and demographic biases, we empirically assess CLIP's stability under paraphrastic variation, examine the interaction between paraphrase robustness and gender, and discuss implications for fairness and equitable deployment of multimodal systems. Our analysis reveals that robustness varies across paraphrasing strategies, with subtle yet consistent differences observed between male- and female-associated queries.
SHAining on Process Mining: Explaining Event Log Characteristics Impact on Algorithms
Sep 10, 2025Process mining aims to extract and analyze insights from event logs, yet algorithm metric results vary widely depending on structural event log characteristics. Existing work often evaluates algorithms on a fixed set of real-world event logs but lacks a systematic analysis of how event log characteristics impact algorithms individually. Moreover, since event logs are generated from processes, where characteristics co-occur, we focus on associational rather than causal effects to assess how strong the overlapping individual characteristic affects evaluation metrics without assuming isolated causal effects, a factor often neglected by prior work. We introduce SHAining, the first approach to quantify the marginal contribution of varying event log characteristics to process mining algorithms' metrics. Using process discovery as a downstream task, we analyze over 22,000 event logs covering a wide span of characteristics to uncover which affect algorithms across metrics (e.g., fitness, precision, complexity) the most. Furthermore, we offer novel insights about how the value of event log characteristics correlates with their contributed impact, assessing the algorithm's robustness.
Enhancing Robustness of Autoregressive Language Models against Orthographic Attacks via Pixel-based Approach
Aug 28, 2025Autoregressive language models are vulnerable to orthographic attacks, where input text is perturbed with characters from multilingual alphabets, leading to substantial performance degradation. This vulnerability primarily stems from the out-of-vocabulary issue inherent in subword tokenizers and their embeddings. To address this limitation, we propose a pixel-based generative language model that replaces the text-based embeddings with pixel-based representations by rendering words as individual images. This design provides stronger robustness to noisy inputs, while an extension of compatibility to multilingual text across diverse writing systems. We evaluate the proposed method on the multilingual LAMBADA dataset, WMT24 dataset and the SST-2 benchmark, demonstrating both its resilience to orthographic noise and its effectiveness in multilingual settings.
Towards Explainable Deep Clustering for Time Series Data
Jul 28, 2025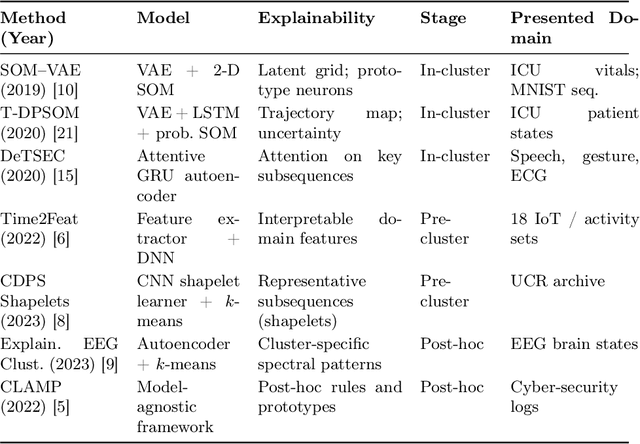
Deep clustering uncovers hidden patterns and groups in complex time series data, yet its opaque decision-making limits use in safety-critical settings. This survey offers a structured overview of explainable deep clustering for time series, collecting current methods and their real-world applications. We thoroughly discuss and compare peer-reviewed and preprint papers through application domains across healthcare, finance, IoT, and climate science. Our analysis reveals that most work relies on autoencoder and attention architectures, with limited support for streaming, irregularly sampled, or privacy-preserved series, and interpretability is still primarily treated as an add-on. To push the field forward, we outline six research opportunities: (1) combining complex networks with built-in interpretability; (2) setting up clear, faithfulness-focused evaluation metrics for unsupervised explanations; (3) building explainers that adapt to live data streams; (4) crafting explanations tailored to specific domains; (5) adding human-in-the-loop methods that refine clusters and explanations together; and (6) improving our understanding of how time series clustering models work internally. By making interpretability a primary design goal rather than an afterthought, we propose the groundwork for the next generation of trustworthy deep clustering time series analytics.
My Answer Is NOT 'Fair': Mitigating Social Bias in Vision-Language Models via Fair and Biased Residuals
May 26, 2025Social bias is a critical issue in large vision-language models (VLMs), where fairness- and ethics-related problems harm certain groups of people in society. It is unknown to what extent VLMs yield social bias in generative responses. In this study, we focus on evaluating and mitigating social bias on both the model's response and probability distribution. To do so, we first evaluate four state-of-the-art VLMs on PAIRS and SocialCounterfactuals datasets with the multiple-choice selection task. Surprisingly, we find that models suffer from generating gender-biased or race-biased responses. We also observe that models are prone to stating their responses are fair, but indeed having mis-calibrated confidence levels towards particular social groups. While investigating why VLMs are unfair in this study, we observe that VLMs' hidden layers exhibit substantial fluctuations in fairness levels. Meanwhile, residuals in each layer show mixed effects on fairness, with some contributing positively while some lead to increased bias. Based on these findings, we propose a post-hoc method for the inference stage to mitigate social bias, which is training-free and model-agnostic. We achieve this by ablating bias-associated residuals while amplifying fairness-associated residuals on model hidden layers during inference. We demonstrate that our post-hoc method outperforms the competing training strategies, helping VLMs have fairer responses and more reliable confidence levels.
ReVisionLLM: Recursive Vision-Language Model for Temporal Grounding in Hour-Long Videos
Nov 22, 2024



Large language models (LLMs) excel at retrieving information from lengthy text, but their vision-language counterparts (VLMs) face difficulties with hour-long videos, especially for temporal grounding. Specifically, these VLMs are constrained by frame limitations, often losing essential temporal details needed for accurate event localization in extended video content. We propose ReVisionLLM, a recursive vision-language model designed to locate events in hour-long videos. Inspired by human search strategies, our model initially targets broad segments of interest, progressively revising its focus to pinpoint exact temporal boundaries. Our model can seamlessly handle videos of vastly different lengths, from minutes to hours. We also introduce a hierarchical training strategy that starts with short clips to capture distinct events and progressively extends to longer videos. To our knowledge, ReVisionLLM is the first VLM capable of temporal grounding in hour-long videos, outperforming previous state-of-the-art methods across multiple datasets by a significant margin (+2.6% R1@0.1 on MAD). The code is available at https://github.com/Tanveer81/ReVisionLLM.
Dying Clusters Is All You Need -- Deep Clustering With an Unknown Number of Clusters
Oct 12, 2024
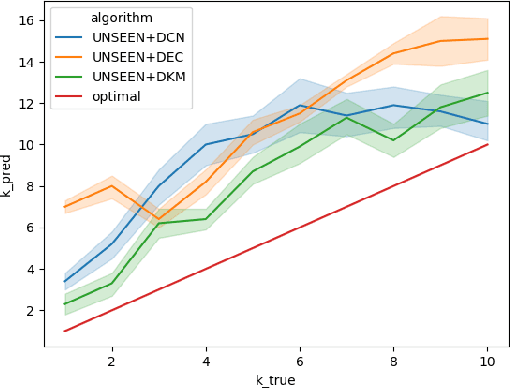


Finding meaningful groups, i.e., clusters, in high-dimensional data such as images or texts without labeled data at hand is an important challenge in data mining. In recent years, deep clustering methods have achieved remarkable results in these tasks. However, most of these methods require the user to specify the number of clusters in advance. This is a major limitation since the number of clusters is typically unknown if labeled data is unavailable. Thus, an area of research has emerged that addresses this problem. Most of these approaches estimate the number of clusters separated from the clustering process. This results in a strong dependency of the clustering result on the quality of the initial embedding. Other approaches are tailored to specific clustering processes, making them hard to adapt to other scenarios. In this paper, we propose UNSEEN, a general framework that, starting from a given upper bound, is able to estimate the number of clusters. To the best of our knowledge, it is the first method that can be easily combined with various deep clustering algorithms. We demonstrate the applicability of our approach by combining UNSEEN with the popular deep clustering algorithms DCN, DEC, and DKM and verify its effectiveness through an extensive experimental evaluation on several image and tabular datasets. Moreover, we perform numerous ablations to analyze our approach and show the importance of its components. The code is available at: https://github.com/collinleiber/UNSEEN
Autoregressive Policy Optimization for Constrained Allocation Tasks
Sep 27, 2024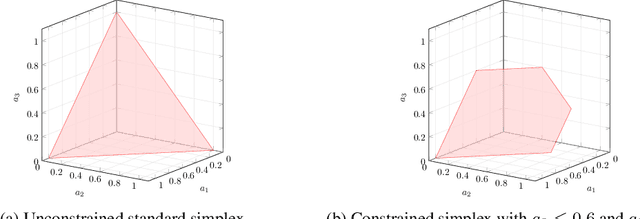
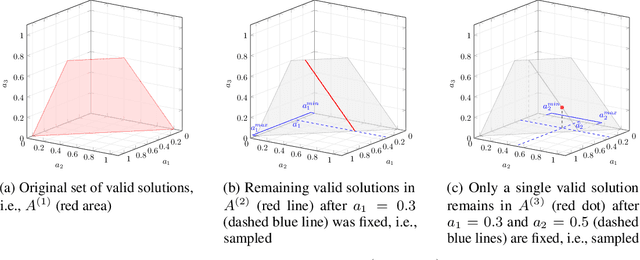
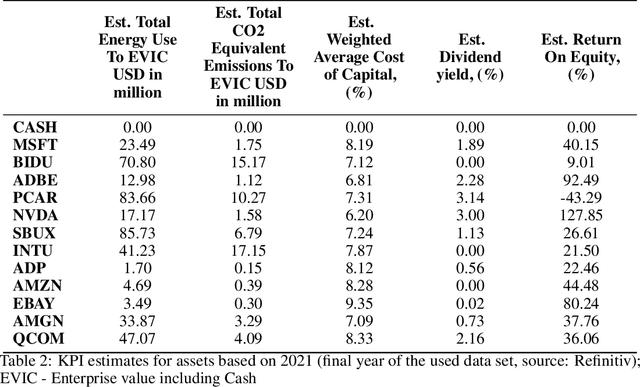
Allocation tasks represent a class of problems where a limited amount of resources must be allocated to a set of entities at each time step. Prominent examples of this task include portfolio optimization or distributing computational workloads across servers. Allocation tasks are typically bound by linear constraints describing practical requirements that have to be strictly fulfilled at all times. In portfolio optimization, for example, investors may be obligated to allocate less than 30\% of the funds into a certain industrial sector in any investment period. Such constraints restrict the action space of allowed allocations in intricate ways, which makes learning a policy that avoids constraint violations difficult. In this paper, we propose a new method for constrained allocation tasks based on an autoregressive process to sequentially sample allocations for each entity. In addition, we introduce a novel de-biasing mechanism to counter the initial bias caused by sequential sampling. We demonstrate the superior performance of our approach compared to a variety of Constrained Reinforcement Learning (CRL) methods on three distinct constrained allocation tasks: portfolio optimization, computational workload distribution, and a synthetic allocation benchmark. Our code is available at: https://github.com/niklasdbs/paspo
ALPBench: A Benchmark for Active Learning Pipelines on Tabular Data
Jun 25, 2024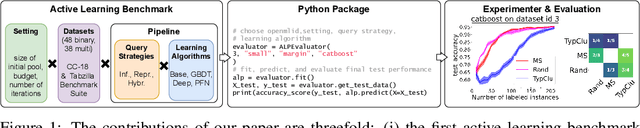

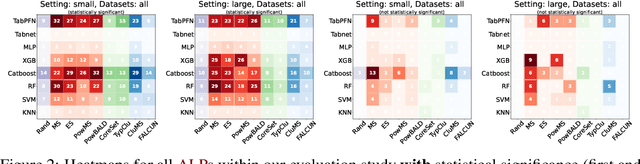

In settings where only a budgeted amount of labeled data can be afforded, active learning seeks to devise query strategies for selecting the most informative data points to be labeled, aiming to enhance learning algorithms' efficiency and performance. Numerous such query strategies have been proposed and compared in the active learning literature. However, the community still lacks standardized benchmarks for comparing the performance of different query strategies. This particularly holds for the combination of query strategies with different learning algorithms into active learning pipelines and examining the impact of the learning algorithm choice. To close this gap, we propose ALPBench, which facilitates the specification, execution, and performance monitoring of active learning pipelines. It has built-in measures to ensure evaluations are done reproducibly, saving exact dataset splits and hyperparameter settings of used algorithms. In total, ALPBench consists of 86 real-world tabular classification datasets and 5 active learning settings, yielding 430 active learning problems. To demonstrate its usefulness and broad compatibility with various learning algorithms and query strategies, we conduct an exemplary study evaluating 9 query strategies paired with 8 learning algorithms in 2 different settings. We provide ALPBench here: https://github.com/ValentinMargraf/ActiveLearningPipelines.