 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Reduced Sample Cost in Prior-Guided Hyperparameter Optimization
Jun 03, 2026Large-scale hyperparameter optimization (HPO) in automated machine learning (AutoML) consumes substantial computational resources, raising growing concerns about scalability and energy efficiency. Existing methods use prior information heuristically to accelerate both black-box and multi-fidelity settings, but they lack a characterization of how prior informativeness quantitatively reduces sample complexity. In this work, we provide the first distribution-dependent sample complexity bounds for multi-fidelity HPO with priors through the formal lens of fixed-budget best-arm identification. By modeling priors directly over arm means as configuration performance, we derive explicit, distribution-dependent error bounds that quantify the relationship between priors and evaluation budget. Our analysis shows that informative priors, which concentrate probability mass on near-optimal arms, yield reductions in the number of required evaluations, whereas baseline performance is recovered with uninformative or misleading priors. We conduct proof-of-concept experiments on a synthetic benchmark and on LCBench, a common multi-fidelity HPO benchmark for deep learning, to confirm our theoretical results, achieving up to 90% budget reduction while retaining solution quality. Together, our results provide a principled foundation for prior-guided and compute-efficient green AutoML.
Evolutionary Mapping of Neural Networks to Spatial Accelerators
Feb 04, 2026Spatial accelerators, composed of arrays of compute-memory integrated units, offer an attractive platform for deploying inference workloads with low latency and low energy consumption. However, fully exploiting their architectural advantages typically requires careful, expert-driven mapping of computational graphs to distributed processing elements. In this work, we automate this process by framing the mapping challenge as a black-box optimization problem. We introduce the first evolutionary, hardware-in-the-loop mapping framework for neuromorphic accelerators, enabling users without deep hardware knowledge to deploy workloads more efficiently. We evaluate our approach on Intel Loihi 2, a representative spatial accelerator featuring 152 cores per chip in a 2D mesh. Our method achieves up to 35% reduction in total latency compared to default heuristics on two sparse multi-layer perceptron networks. Furthermore, we demonstrate the scalability of our approach to multi-chip systems and observe an up to 40% improvement in energy efficiency, without explicitly optimizing for it.
Dynamic Hyperparameter Importance for Efficient Multi-Objective Optimization
Jan 06, 2026Choosing a suitable ML model is a complex task that can depend on several objectives, e.g., accuracy, model size, fairness, inference time, or energy consumption. In practice, this requires trading off multiple, often competing, objectives through multi-objective optimization (MOO). However, existing MOO methods typically treat all hyperparameters as equally important, overlooking that hyperparameter importance (HPI) can vary significantly depending on the trade-off between objectives. We propose a novel dynamic optimization approach that prioritizes the most influential hyperparameters based on varying objective trade-offs during the search process, which accelerates empirical convergence and leads to better solutions. Building on prior work on HPI for MOO post-analysis, we now integrate HPI, calculated with HyperSHAP, into the optimization. For this, we leverage the objective weightings naturally produced by the MOO algorithm ParEGO and adapt the configuration space by fixing the unimportant hyperparameters, allowing the search to focus on the important ones. Eventually, we validate our method with diverse tasks from PyMOO and YAHPO-Gym. Empirical results demonstrate improvements in convergence speed and Pareto front quality compared to baselines.
Best Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025
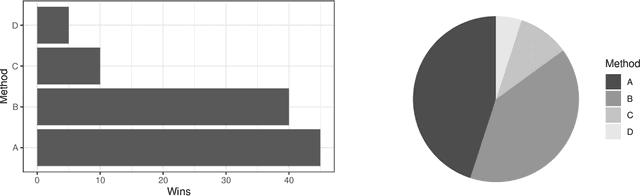
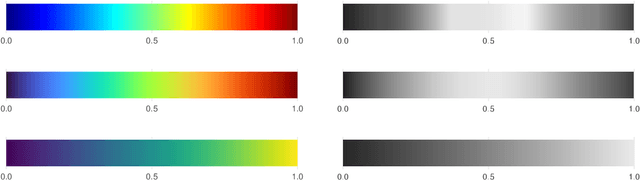
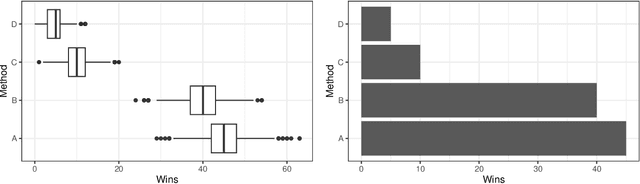
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
HyperSHAP: Shapley Values and Interactions for Hyperparameter Importance
Feb 03, 2025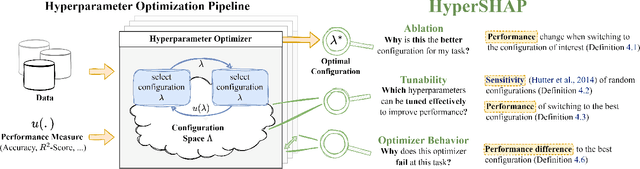



Hyperparameter optimization (HPO) is a crucial step in achieving strong predictive performance. However, the impact of individual hyperparameters on model generalization is highly context-dependent, prohibiting a one-size-fits-all solution and requiring opaque automated machine learning (AutoML) systems to find optimal configurations. The black-box nature of most AutoML systems undermines user trust and discourages adoption. To address this, we propose a game-theoretic explainability framework for HPO that is based on Shapley values and interactions. Our approach provides an additive decomposition of a performance measure across hyperparameters, enabling local and global explanations of hyperparameter importance and interactions. The framework, named HyperSHAP, offers insights into ablations, the tunability of learning algorithms, and optimizer behavior across different hyperparameter spaces. We evaluate HyperSHAP on various HPO benchmarks by analyzing the interaction structure of the HPO problem. Our results show that while higher-order interactions exist, most performance improvements can be explained by focusing on lower-order representations.
ALPBench: A Benchmark for Active Learning Pipelines on Tabular Data
Jun 25, 2024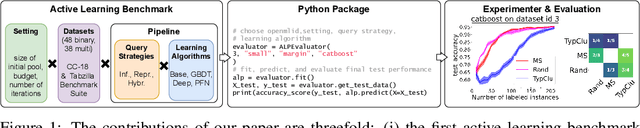

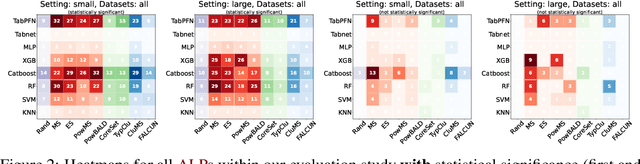

In settings where only a budgeted amount of labeled data can be afforded, active learning seeks to devise query strategies for selecting the most informative data points to be labeled, aiming to enhance learning algorithms' efficiency and performance. Numerous such query strategies have been proposed and compared in the active learning literature. However, the community still lacks standardized benchmarks for comparing the performance of different query strategies. This particularly holds for the combination of query strategies with different learning algorithms into active learning pipelines and examining the impact of the learning algorithm choice. To close this gap, we propose ALPBench, which facilitates the specification, execution, and performance monitoring of active learning pipelines. It has built-in measures to ensure evaluations are done reproducibly, saving exact dataset splits and hyperparameter settings of used algorithms. In total, ALPBench consists of 86 real-world tabular classification datasets and 5 active learning settings, yielding 430 active learning problems. To demonstrate its usefulness and broad compatibility with various learning algorithms and query strategies, we conduct an exemplary study evaluating 9 query strategies paired with 8 learning algorithms in 2 different settings. We provide ALPBench here: https://github.com/ValentinMargraf/ActiveLearningPipelines.
Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation
May 03, 2024We warn against a common but incomplete understanding of empirical research in machine learning (ML) that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical ML research is fashioned as confirmatory research while it should rather be considered exploratory.
Automated Machine Learning for Multi-Label Classification
Feb 28, 2024



Automated machine learning (AutoML) aims to select and configure machine learning algorithms and combine them into machine learning pipelines tailored to a dataset at hand. For supervised learning tasks, most notably binary and multinomial classification, aka single-label classification (SLC), such AutoML approaches have shown promising results. However, the task of multi-label classification (MLC), where data points are associated with a set of class labels instead of a single class label, has received much less attention so far. In the context of multi-label classification, the data-specific selection and configuration of multi-label classifiers are challenging even for experts in the field, as it is a high-dimensional optimization problem with multi-level hierarchical dependencies. While for SLC, the space of machine learning pipelines is already huge, the size of the MLC search space outnumbers the one of SLC by several orders. In the first part of this thesis, we devise a novel AutoML approach for single-label classification tasks optimizing pipelines of machine learning algorithms, consisting of two algorithms at most. This approach is then extended first to optimize pipelines of unlimited length and eventually configure the complex hierarchical structures of multi-label classification methods. Furthermore, we investigate how well AutoML approaches that form the state of the art for single-label classification tasks scale with the increased problem complexity of AutoML for multi-label classification. In the second part, we explore how methods for SLC and MLC could be configured more flexibly to achieve better generalization performance and how to increase the efficiency of execution-based AutoML systems.
Information Leakage Detection through Approximate Bayes-optimal Prediction
Jan 25, 2024



In today's data-driven world, the proliferation of publicly available information intensifies the challenge of information leakage (IL), raising security concerns. IL involves unintentionally exposing secret (sensitive) information to unauthorized parties via systems' observable information. Conventional statistical approaches, which estimate mutual information (MI) between observable and secret information for detecting IL, face challenges such as the curse of dimensionality, convergence, computational complexity, and MI misestimation. Furthermore, emerging supervised machine learning (ML) methods, though effective, are limited to binary system-sensitive information and lack a comprehensive theoretical framework. To address these limitations, we establish a theoretical framework using statistical learning theory and information theory to accurately quantify and detect IL. We demonstrate that MI can be accurately estimated by approximating the log-loss and accuracy of the Bayes predictor. As the Bayes predictor is typically unknown in practice, we propose to approximate it with the help of automated machine learning (AutoML). First, we compare our MI estimation approaches against current baselines, using synthetic data sets generated using the multivariate normal (MVN) distribution with known MI. Second, we introduce a cut-off technique using one-sided statistical tests to detect IL, employing the Holm-Bonferroni correction to increase confidence in detection decisions. Our study evaluates IL detection performance on real-world data sets, highlighting the effectiveness of the Bayes predictor's log-loss estimation, and finds our proposed method to effectively estimate MI on synthetic data sets and thus detect ILs accurately.
Iterative Deepening Hyperband
Feb 06, 2023


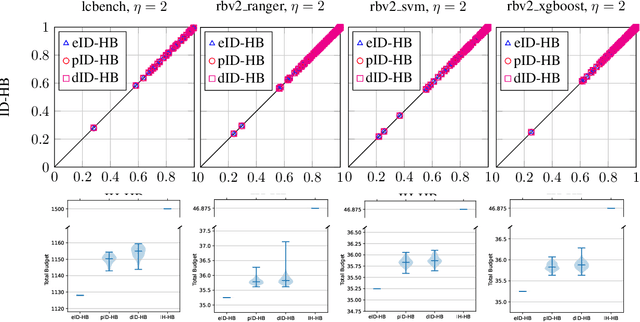
Hyperparameter optimization (HPO) is concerned with the automated search for the most appropriate hyperparameter configuration (HPC) of a parameterized machine learning algorithm. A state-of-the-art HPO method is Hyperband, which, however, has its own parameters that influence its performance. One of these parameters, the maximal budget, is especially problematic: If chosen too small, the budget needs to be increased in hindsight and, as Hyperband is not incremental by design, the entire algorithm must be re-run. This is not only costly but also comes with a loss of valuable knowledge already accumulated. In this paper, we propose incremental variants of Hyperband that eliminate these drawbacks, and show that these variants satisfy theoretical guarantees qualitatively similar to those for the original Hyperband with the "right" budget. Moreover, we demonstrate their practical utility in experiments with benchmark data sets.