 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025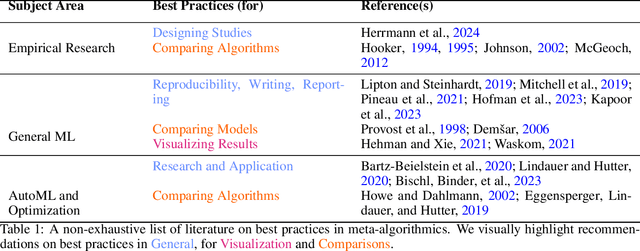
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Position: A Call to Action for a Human-Centered AutoML Paradigm
Jun 05, 2024Automated machine learning (AutoML) was formed around the fundamental objectives of automatically and efficiently configuring machine learning (ML) workflows, aiding the research of new ML algorithms, and contributing to the democratization of ML by making it accessible to a broader audience. Over the past decade, commendable achievements in AutoML have primarily focused on optimizing predictive performance. This focused progress, while substantial, raises questions about how well AutoML has met its broader, original goals. In this position paper, we argue that a key to unlocking AutoML's full potential lies in addressing the currently underexplored aspect of user interaction with AutoML systems, including their diverse roles, expectations, and expertise. We envision a more human-centered approach in future AutoML research, promoting the collaborative design of ML systems that tightly integrates the complementary strengths of human expertise and AutoML methodologies.
Interactive Hyperparameter Optimization in Multi-Objective Problems via Preference Learning
Sep 13, 2023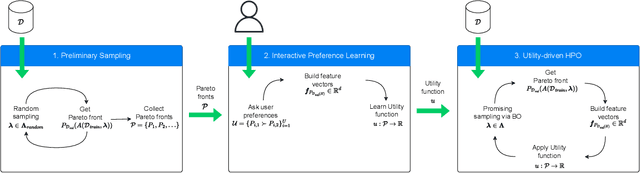

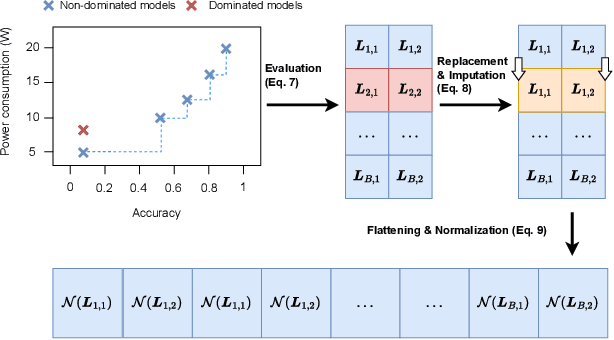

Hyperparameter optimization (HPO) is important to leverage the full potential of machine learning (ML). In practice, users are often interested in multi-objective (MO) problems, i.e., optimizing potentially conflicting objectives, like accuracy and energy consumption. To tackle this, the vast majority of MO-ML algorithms return a Pareto front of non-dominated machine learning models to the user. Optimizing the hyperparameters of such algorithms is non-trivial as evaluating a hyperparameter configuration entails evaluating the quality of the resulting Pareto front. In literature, there are known indicators that assess the quality of a Pareto front (e.g., hypervolume, R2) by quantifying different properties (e.g., volume, proximity to a reference point). However, choosing the indicator that leads to the desired Pareto front might be a hard task for a user. In this paper, we propose a human-centered interactive HPO approach tailored towards multi-objective ML leveraging preference learning to extract desiderata from users that guide the optimization. Instead of relying on the user guessing the most suitable indicator for their needs, our approach automatically learns an appropriate indicator. Concretely, we leverage pairwise comparisons of distinct Pareto fronts to learn such an appropriate quality indicator. Then, we optimize the hyperparameters of the underlying MO-ML algorithm towards this learned indicator using a state-of-the-art HPO approach. In an experimental study targeting the environmental impact of ML, we demonstrate that our approach leads to substantially better Pareto fronts compared to optimizing based on a wrong indicator pre-selected by the user, and performs comparable in the case of an advanced user knowing which indicator to pick.
AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks
Jun 13, 2023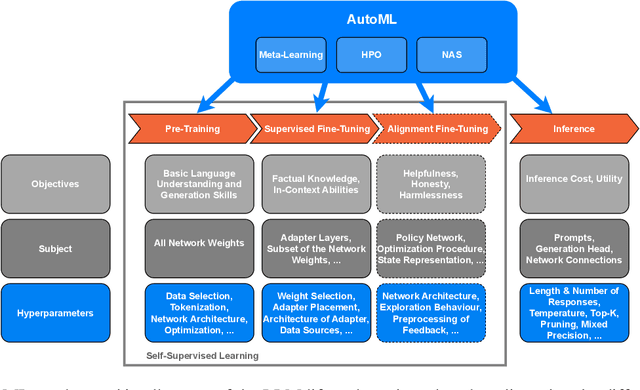
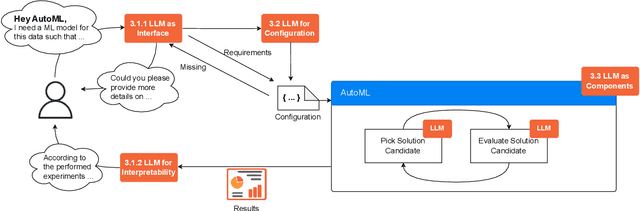
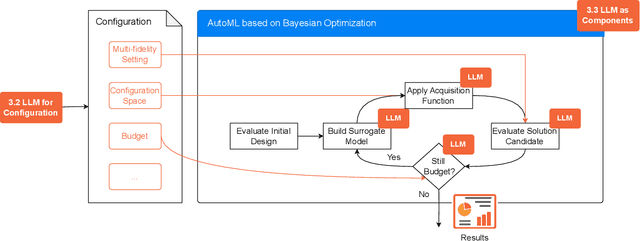
The fields of both Natural Language Processing (NLP) and Automated Machine Learning (AutoML) have achieved remarkable results over the past years. In NLP, especially Large Language Models (LLMs) have experienced a rapid series of breakthroughs very recently. We envision that the two fields can radically push the boundaries of each other through tight integration. To showcase this vision, we explore the potential of a symbiotic relationship between AutoML and LLMs, shedding light on how they can benefit each other. In particular, we investigate both the opportunities to enhance AutoML approaches with LLMs from different perspectives and the challenges of leveraging AutoML to further improve LLMs. To this end, we survey existing work, and we critically assess risks. We strongly believe that the integration of the two fields has the potential to disrupt both fields, NLP and AutoML. By highlighting conceivable synergies, but also risks, we aim to foster further exploration at the intersection of AutoML and LLMs.
PyExperimenter: Easily distribute experiments and track results
Jan 16, 2023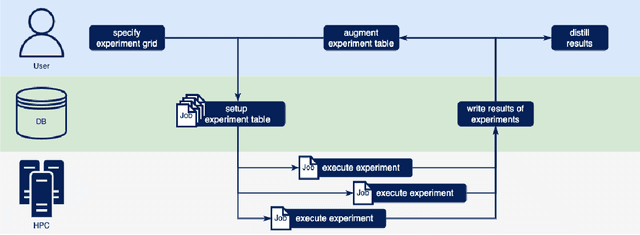
PyExperimenter is a tool to facilitate the setup, documentation, execution, and subsequent evaluation of results from an empirical study of algorithms and in particular is designed to reduce the involved manual effort significantly. It is intended to be used by researchers in the field of artificial intelligence, but is not limited to those.
HARRIS: Hybrid Ranking and Regression Forests for Algorithm Selection
Oct 31, 2022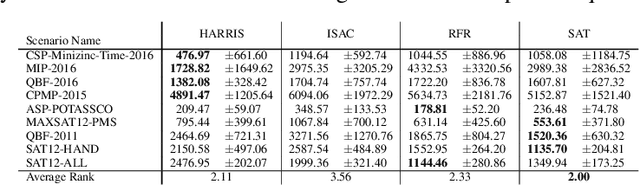
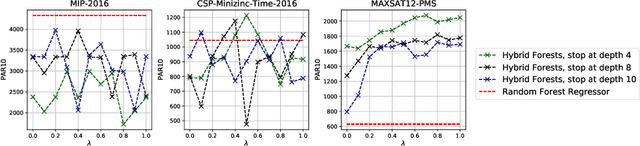

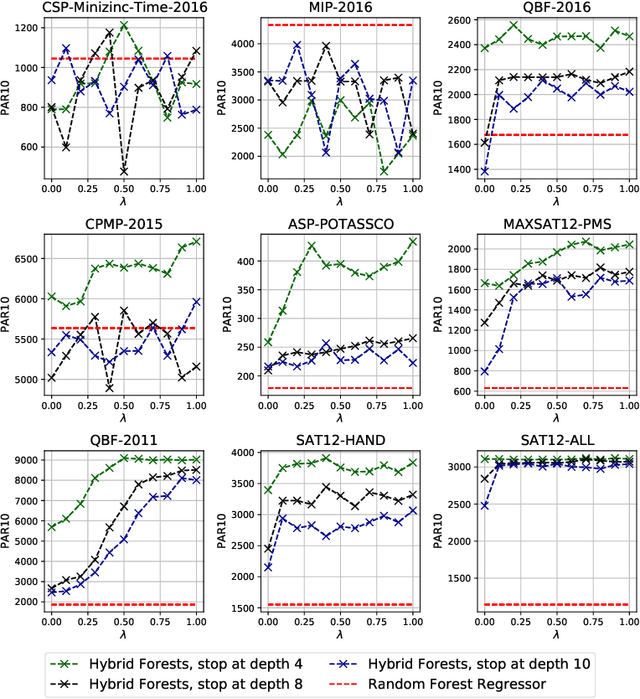
It is well known that different algorithms perform differently well on an instance of an algorithmic problem, motivating algorithm selection (AS): Given an instance of an algorithmic problem, which is the most suitable algorithm to solve it? As such, the AS problem has received considerable attention resulting in various approaches - many of which either solve a regression or ranking problem under the hood. Although both of these formulations yield very natural ways to tackle AS, they have considerable weaknesses. On the one hand, correctly predicting the performance of an algorithm on an instance is a sufficient, but not a necessary condition to produce a correct ranking over algorithms and in particular ranking the best algorithm first. On the other hand, classical ranking approaches often do not account for concrete performance values available in the training data, but only leverage rankings composed from such data. We propose HARRIS- Hybrid rAnking and RegRessIon foreSts - a new algorithm selector leveraging special forests, combining the strengths of both approaches while alleviating their weaknesses. HARRIS' decisions are based on a forest model, whose trees are created based on splits optimized on a hybrid ranking and regression loss function. As our preliminary experimental study on ASLib shows, HARRIS improves over standard algorithm selection approaches on some scenarios showing that combining ranking and regression in trees is indeed promising for AS.
A Survey of Methods for Automated Algorithm Configuration
Feb 03, 2022
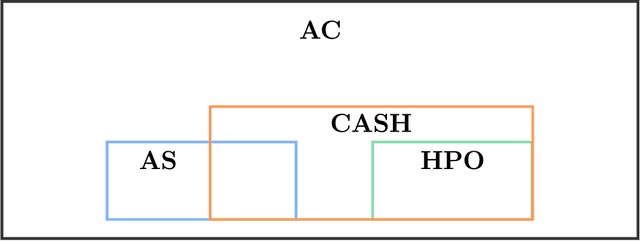
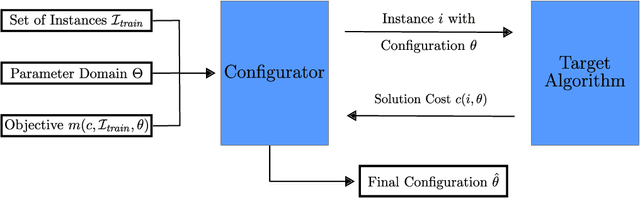
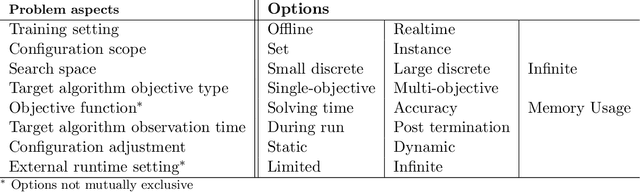
Algorithm configuration (AC) is concerned with the automated search of the most suitable parameter configuration of a parametrized algorithm. There is currently a wide variety of AC problem variants and methods proposed in the literature. Existing reviews do not take into account all derivatives of the AC problem, nor do they offer a complete classification scheme. To this end, we introduce taxonomies to describe the AC problem and features of configuration methods, respectively. We review existing AC literature within the lens of our taxonomies, outline relevant design choices of configuration approaches, contrast methods and problem variants against each other, and describe the state of AC in industry. Finally, our review provides researchers and practitioners with a look at future research directions in the field of AC.
Towards Green Automated Machine Learning: Status Quo and Future Directions
Nov 10, 2021
Automated machine learning (AutoML) strives for the automatic configuration of machine learning algorithms and their composition into an overall (software) solution - a machine learning pipeline - tailored to the learning task (dataset) at hand. Over the last decade, AutoML has become a hot research topic with hundreds of contributions. While AutoML offers many prospects, it is also known to be quite resource-intensive, which is one of its major points of criticism. The primary cause for a high resource consumption is that many approaches rely on the (costly) evaluation of many ML pipelines while searching for good candidates. This problem is amplified in the context of research on AutoML methods, due to large scale experiments conducted with many datasets and approaches, each of them being run with several repetitions to rule out random effects. In the spirit of recent work on Green AI, this paper is written in an attempt to raise the awareness of AutoML researchers for the problem and to elaborate on possible remedies. To this end, we identify four categories of actions the community may take towards more sustainable research on AutoML, namely approach design, benchmarking, research incentives, and transparency.
Machine Learning for Online Algorithm Selection under Censored Feedback
Sep 13, 2021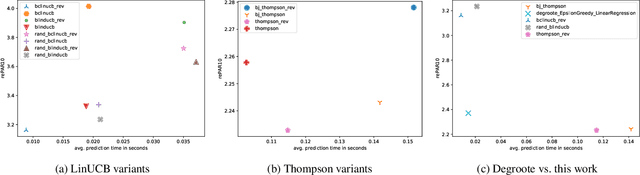
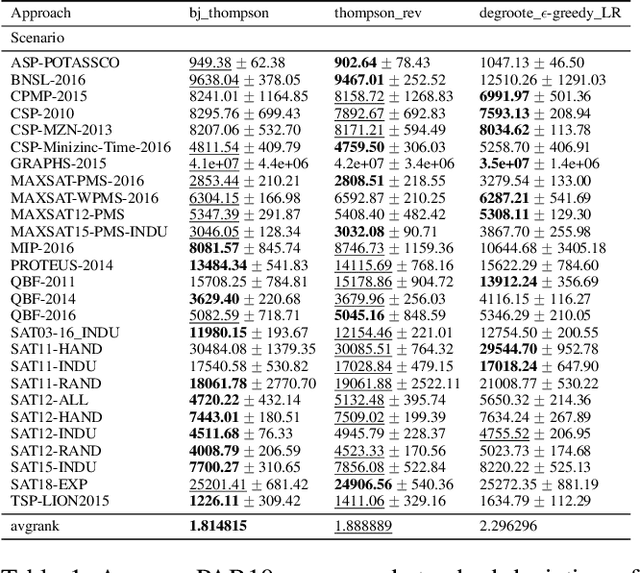
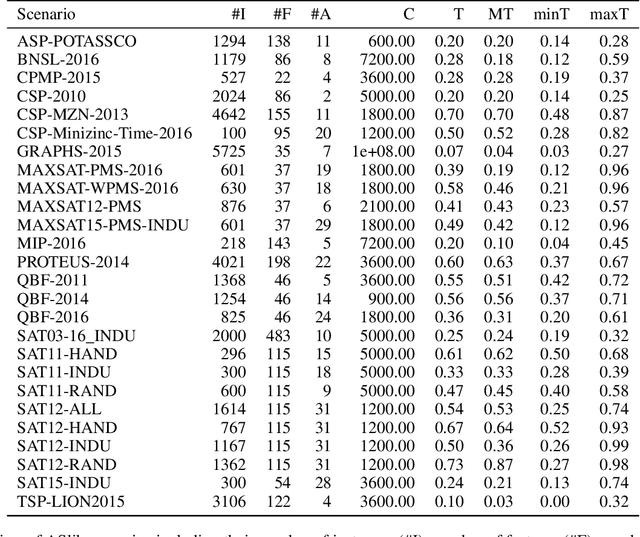
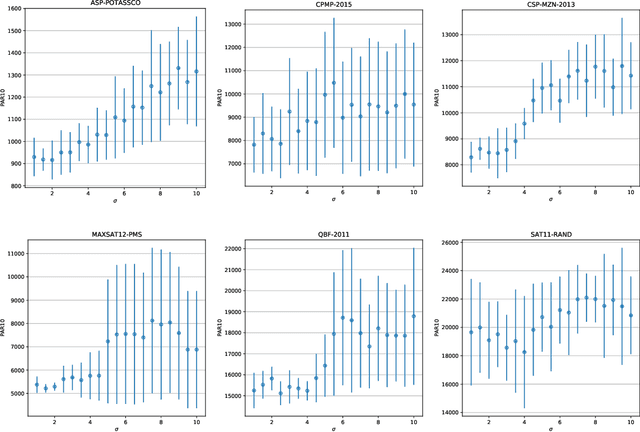
In online algorithm selection (OAS), instances of an algorithmic problem class are presented to an agent one after another, and the agent has to quickly select a presumably best algorithm from a fixed set of candidate algorithms. For decision problems such as satisfiability (SAT), quality typically refers to the algorithm's runtime. As the latter is known to exhibit a heavy-tail distribution, an algorithm is normally stopped when exceeding a predefined upper time limit. As a consequence, machine learning methods used to optimize an algorithm selection strategy in a data-driven manner need to deal with right-censored samples, a problem that has received little attention in the literature so far. In this work, we revisit multi-armed bandit algorithms for OAS and discuss their capability of dealing with the problem. Moreover, we adapt them towards runtime-oriented losses, allowing for partially censored data while keeping a space- and time-complexity independent of the time horizon. In an extensive experimental evaluation on an adapted version of the ASlib benchmark, we demonstrate that theoretically well-founded methods based on Thompson sampling perform specifically strong and improve in comparison to existing methods.
Automated Machine Learning, Bounded Rationality, and Rational Metareasoning
Sep 10, 2021The notion of bounded rationality originated from the insight that perfectly rational behavior cannot be realized by agents with limited cognitive or computational resources. Research on bounded rationality, mainly initiated by Herbert Simon, has a longstanding tradition in economics and the social sciences, but also plays a major role in modern AI and intelligent agent design. Taking actions under bounded resources requires an agent to reflect on how to use these resources in an optimal way - hence, to reason and make decisions on a meta-level. In this paper, we will look at automated machine learning (AutoML) and related problems from the perspective of bounded rationality, essentially viewing an AutoML tool as an agent that has to train a model on a given set of data, and the search for a good way of doing so (a suitable "ML pipeline") as deliberation on a meta-level.