 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Embracing Negative Results in Machine Learning
Jun 06, 2024Publications proposing novel machine learning methods are often primarily rated by exhibited predictive performance on selected problems. In this position paper we argue that predictive performance alone is not a good indicator for the worth of a publication. Using it as such even fosters problems like inefficiencies of the machine learning research community as a whole and setting wrong incentives for researchers. We therefore put out a call for the publication of "negative" results, which can help alleviate some of these problems and improve the scientific output of the machine learning research community. To substantiate our position, we present the advantages of publishing negative results and provide concrete measures for the community to move towards a paradigm where their publication is normalized.
Position: A Call to Action for a Human-Centered AutoML Paradigm
Jun 05, 2024Automated machine learning (AutoML) was formed around the fundamental objectives of automatically and efficiently configuring machine learning (ML) workflows, aiding the research of new ML algorithms, and contributing to the democratization of ML by making it accessible to a broader audience. Over the past decade, commendable achievements in AutoML have primarily focused on optimizing predictive performance. This focused progress, while substantial, raises questions about how well AutoML has met its broader, original goals. In this position paper, we argue that a key to unlocking AutoML's full potential lies in addressing the currently underexplored aspect of user interaction with AutoML systems, including their diverse roles, expectations, and expertise. We envision a more human-centered approach in future AutoML research, promoting the collaborative design of ML systems that tightly integrates the complementary strengths of human expertise and AutoML methodologies.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022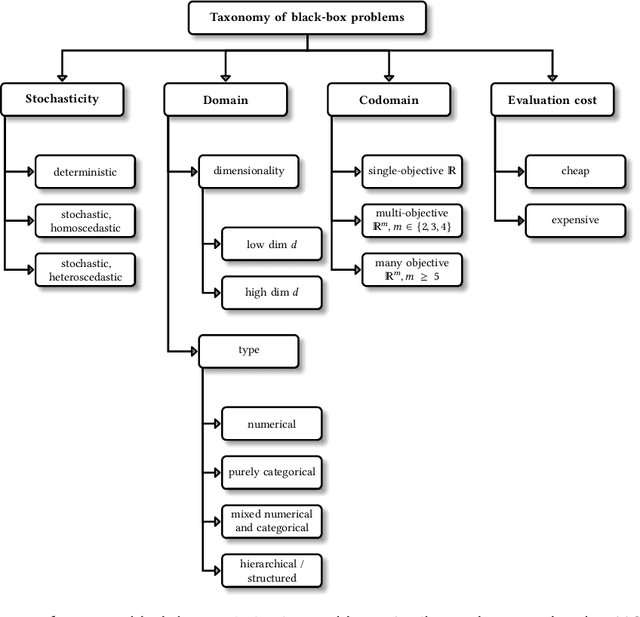

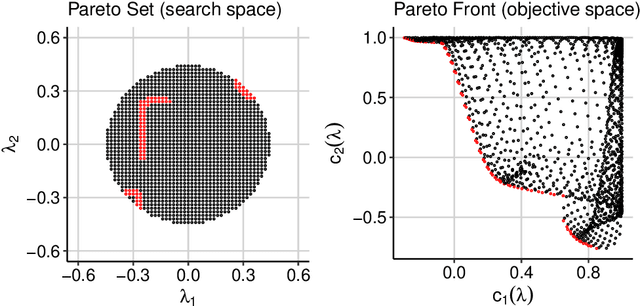
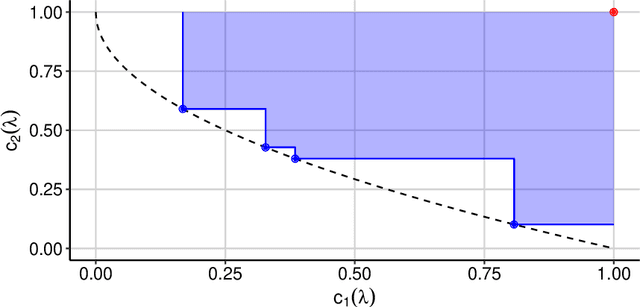
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
Efficient Automated Deep Learning for Time Series Forecasting
May 13, 2022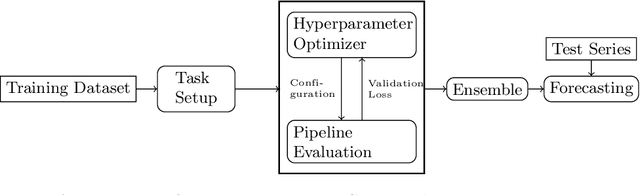
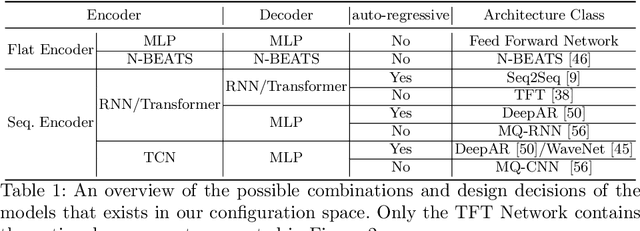
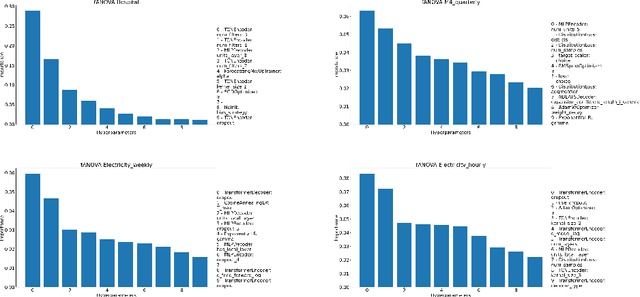
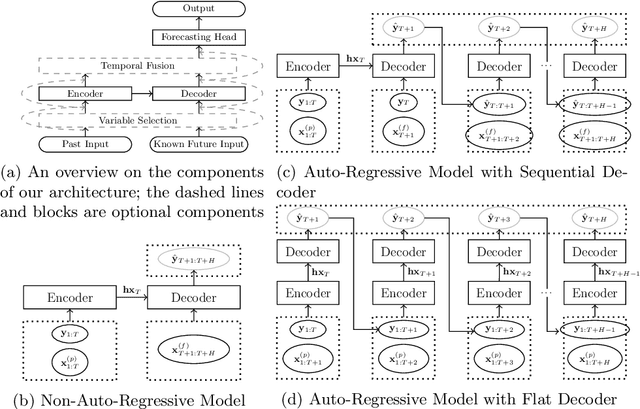
Recent years have witnessed tremendously improved efficiency of Automated Machine Learning (AutoML), especially Automated Deep Learning (AutoDL) systems, but recent work focuses on tabular, image, or NLP tasks. So far, little attention has been paid to general AutoDL frameworks for time series forecasting, despite the enormous success in applying different novel architectures to such tasks. In this paper, we propose an efficient approach for the joint optimization of neural architecture and hyperparameters of the entire data processing pipeline for time series forecasting. In contrast to common NAS search spaces, we designed a novel neural architecture search space covering various state-of-the-art architectures, allowing for an efficient macro-search over different DL approaches. To efficiently search in such a large configuration space, we use Bayesian optimization with multi-fidelity optimization. We empirically study several different budget types enabling efficient multi-fidelity optimization on different forecasting datasets. Furthermore, we compared our resulting system, dubbed Auto-PyTorch-TS, against several established baselines and show that it significantly outperforms all of them across several datasets.