 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemlr3mbo: Bayesian Optimization in R
Mar 31, 2026We present mlr3mbo, a comprehensive and modular toolbox for Bayesian optimization in R. mlr3mbo supports single- and multi-objective optimization, multi-point proposals, batch and asynchronous parallelization, input and output transformations, and robust error handling. While it can be used for many standard Bayesian optimization variants in applied settings, researchers can also construct custom BO algorithms from its flexible building blocks. In addition to an introduction to the software, its design principles, and its building blocks, the paper presents two extensive empirical evaluations of the software on the surrogate-based benchmark suite YAHPO Gym. To identify robust default configurations for both numeric and mixed-hierarchical optimization regimes, and to gain further insights into the respective impacts of individual settings, we run a coordinate descent search over the mlr3mbo configuration space and analyze its results. Furthermore, we demonstrate that mlr3mbo achieves state-of-the-art performance by benchmarking it against a wide range of optimizers, including HEBO, SMAC3, Ax, and Optuna.
Overtuning in Hyperparameter Optimization
Jun 24, 2025Hyperparameter optimization (HPO) aims to identify an optimal hyperparameter configuration (HPC) such that the resulting model generalizes well to unseen data. As the expected generalization error cannot be optimized directly, it is estimated with a resampling strategy, such as holdout or cross-validation. This approach implicitly assumes that minimizing the validation error leads to improved generalization. However, since validation error estimates are inherently stochastic and depend on the resampling strategy, a natural question arises: Can excessive optimization of the validation error lead to overfitting at the HPO level, akin to overfitting in model training based on empirical risk minimization? In this paper, we investigate this phenomenon, which we term overtuning, a form of overfitting specific to HPO. Despite its practical relevance, overtuning has received limited attention in the HPO and AutoML literature. We provide a formal definition of overtuning and distinguish it from related concepts such as meta-overfitting. We then conduct a large-scale reanalysis of HPO benchmark data to assess the prevalence and severity of overtuning. Our results show that overtuning is more common than previously assumed, typically mild but occasionally severe. In approximately 10% of cases, overtuning leads to the selection of a seemingly optimal HPC with worse generalization error than the default or first configuration tried. We further analyze how factors such as performance metric, resampling strategy, dataset size, learning algorithm, and HPO method affect overtuning and discuss mitigation strategies. Our results highlight the need to raise awareness of overtuning, particularly in the small-data regime, indicating that further mitigation strategies should be studied.
Hyperband-based Bayesian Optimization for Black-box Prompt Selection
Dec 10, 2024



Optimal prompt selection is crucial for maximizing large language model (LLM) performance on downstream tasks. As the most powerful models are proprietary and can only be invoked via an API, users often manually refine prompts in a black-box setting by adjusting instructions and few-shot examples until they achieve good performance as measured on a validation set. Recent methods addressing static black-box prompt selection face significant limitations: They often fail to leverage the inherent structure of prompts, treating instructions and few-shot exemplars as a single block of text. Moreover, they often lack query-efficiency by evaluating prompts on all validation instances, or risk sub-optimal selection of a prompt by using random subsets of validation instances. We introduce HbBoPs, a novel Hyperband-based Bayesian optimization method for black-box prompt selection addressing these key limitations. Our approach combines a structural-aware deep kernel Gaussian Process to model prompt performance with Hyperband as a multi-fidelity scheduler to select the number of validation instances for prompt evaluations. The structural-aware modeling approach utilizes separate embeddings for instructions and few-shot exemplars, enhancing the surrogate model's ability to capture prompt performance and predict which prompt to evaluate next in a sample-efficient manner. Together with Hyperband as a multi-fidelity scheduler we further enable query-efficiency by adaptively allocating resources across different fidelity levels, keeping the total number of validation instances prompts are evaluated on low. Extensive evaluation across ten benchmarks and three LLMs demonstrate that HbBoPs outperforms state-of-the-art methods.
Reshuffling Resampling Splits Can Improve Generalization of Hyperparameter Optimization
May 24, 2024



Hyperparameter optimization is crucial for obtaining peak performance of machine learning models. The standard protocol evaluates various hyperparameter configurations using a resampling estimate of the generalization error to guide optimization and select a final hyperparameter configuration. Without much evidence, paired resampling splits, i.e., either a fixed train-validation split or a fixed cross-validation scheme, are often recommended. We show that, surprisingly, reshuffling the splits for every configuration often improves the final model's generalization performance on unseen data. Our theoretical analysis explains how reshuffling affects the asymptotic behavior of the validation loss surface and provides a bound on the expected regret in the limiting regime. This bound connects the potential benefits of reshuffling to the signal and noise characteristics of the underlying optimization problem. We confirm our theoretical results in a controlled simulation study and demonstrate the practical usefulness of reshuffling in a large-scale, realistic hyperparameter optimization experiment. While reshuffling leads to test performances that are competitive with using fixed splits, it drastically improves results for a single train-validation holdout protocol and can often make holdout become competitive with standard CV while being computationally cheaper.
Evaluating machine learning models in non-standard settings: An overview and new findings
Oct 23, 2023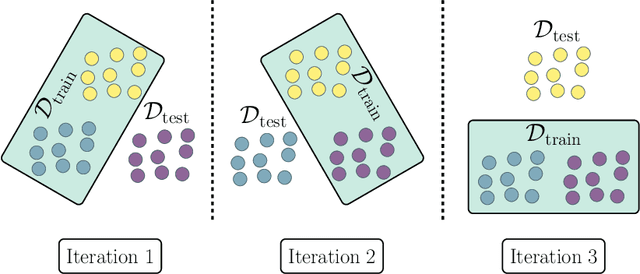

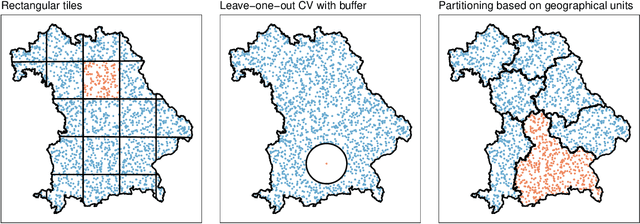

Estimating the generalization error (GE) of machine learning models is fundamental, with resampling methods being the most common approach. However, in non-standard settings, particularly those where observations are not independently and identically distributed, resampling using simple random data divisions may lead to biased GE estimates. This paper strives to present well-grounded guidelines for GE estimation in various such non-standard settings: clustered data, spatial data, unequal sampling probabilities, concept drift, and hierarchically structured outcomes. Our overview combines well-established methodologies with other existing methods that, to our knowledge, have not been frequently considered in these particular settings. A unifying principle among these techniques is that the test data used in each iteration of the resampling procedure should reflect the new observations to which the model will be applied, while the training data should be representative of the entire data set used to obtain the final model. Beyond providing an overview, we address literature gaps by conducting simulation studies. These studies assess the necessity of using GE-estimation methods tailored to the respective setting. Our findings corroborate the concern that standard resampling methods often yield biased GE estimates in non-standard settings, underscoring the importance of tailored GE estimation.
Q(D)O-ES: Population-based Quality (Diversity) Optimisation for Post Hoc Ensemble Selection in AutoML
Aug 02, 2023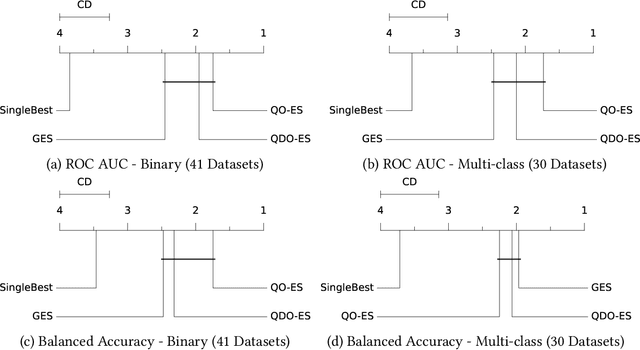
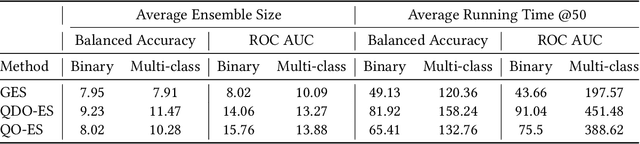
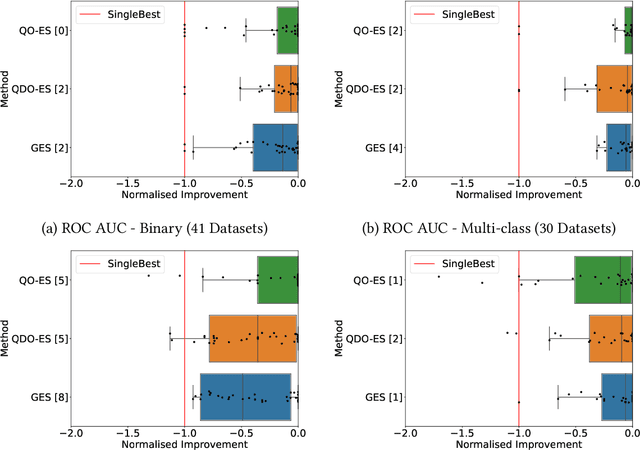
Automated machine learning (AutoML) systems commonly ensemble models post hoc to improve predictive performance, typically via greedy ensemble selection (GES). However, we believe that GES may not always be optimal, as it performs a simple deterministic greedy search. In this work, we introduce two novel population-based ensemble selection methods, QO-ES and QDO-ES, and compare them to GES. While QO-ES optimises solely for predictive performance, QDO-ES also considers the diversity of ensembles within the population, maintaining a diverse set of well-performing ensembles during optimisation based on ideas of quality diversity optimisation. The methods are evaluated using 71 classification datasets from the AutoML benchmark, demonstrating that QO-ES and QDO-ES often outrank GES, albeit only statistically significant on validation data. Our results further suggest that diversity can be beneficial for post hoc ensembling but also increases the risk of overfitting.
Multi-Objective Optimization of Performance and Interpretability of Tabular Supervised Machine Learning Models
Jul 17, 2023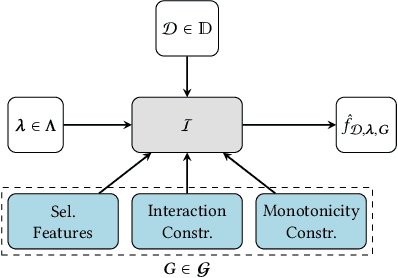
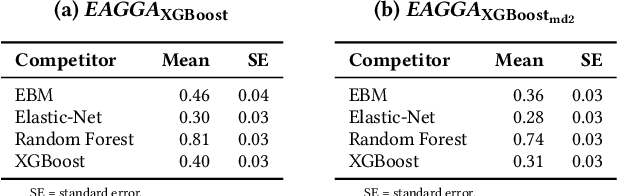
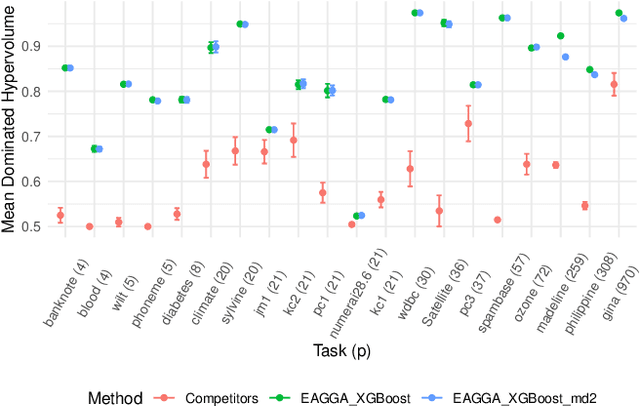
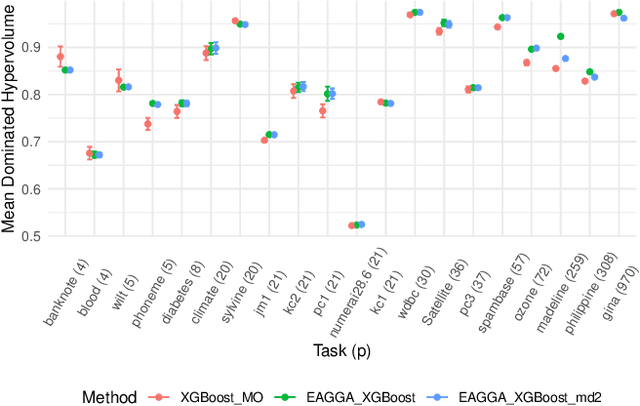
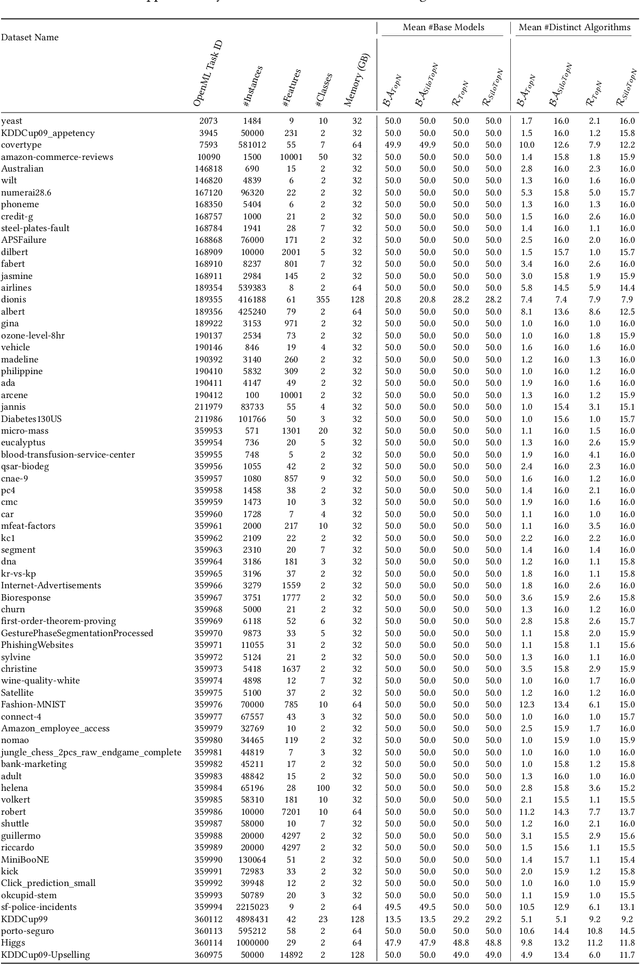
We present a model-agnostic framework for jointly optimizing the predictive performance and interpretability of supervised machine learning models for tabular data. Interpretability is quantified via three measures: feature sparsity, interaction sparsity of features, and sparsity of non-monotone feature effects. By treating hyperparameter optimization of a machine learning algorithm as a multi-objective optimization problem, our framework allows for generating diverse models that trade off high performance and ease of interpretability in a single optimization run. Efficient optimization is achieved via augmentation of the search space of the learning algorithm by incorporating feature selection, interaction and monotonicity constraints into the hyperparameter search space. We demonstrate that the optimization problem effectively translates to finding the Pareto optimal set of groups of selected features that are allowed to interact in a model, along with finding their optimal monotonicity constraints and optimal hyperparameters of the learning algorithm itself. We then introduce a novel evolutionary algorithm that can operate efficiently on this augmented search space. In benchmark experiments, we show that our framework is capable of finding diverse models that are highly competitive or outperform state-of-the-art XGBoost or Explainable Boosting Machine models, both with respect to performance and interpretability.
HPO X ELA: Investigating Hyperparameter Optimization Landscapes by Means of Exploratory Landscape Analysis
Jul 30, 2022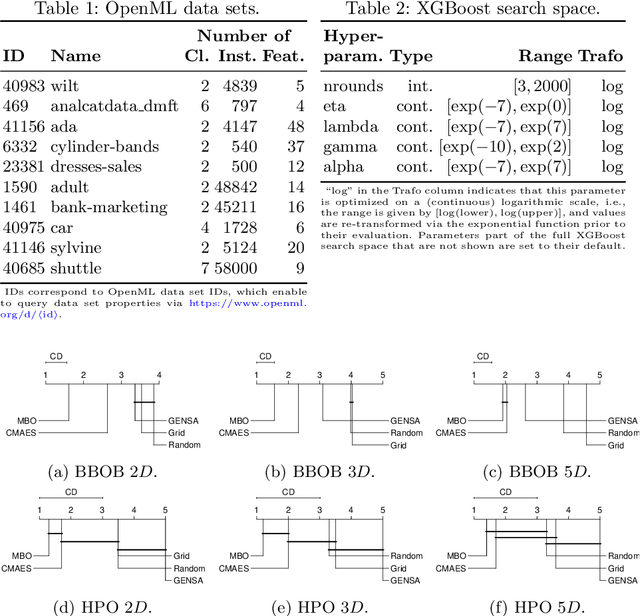
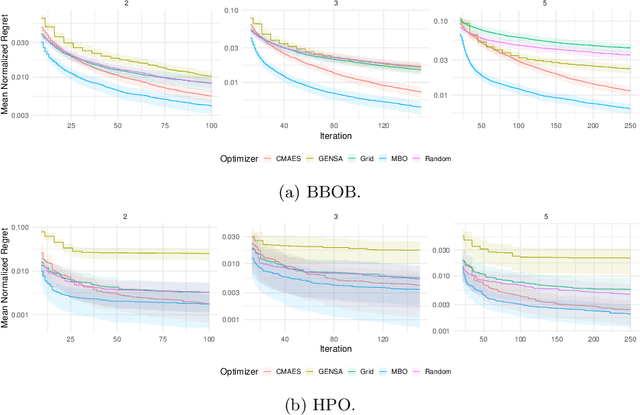

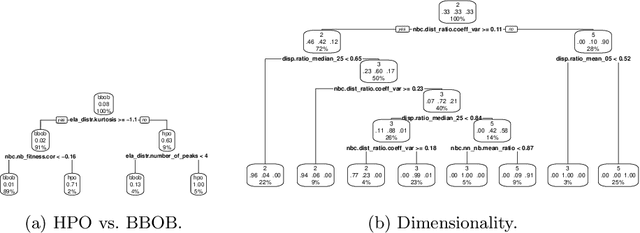
Hyperparameter optimization (HPO) is a key component of machine learning models for achieving peak predictive performance. While numerous methods and algorithms for HPO have been proposed over the last years, little progress has been made in illuminating and examining the actual structure of these black-box optimization problems. Exploratory landscape analysis (ELA) subsumes a set of techniques that can be used to gain knowledge about properties of unknown optimization problems. In this paper, we evaluate the performance of five different black-box optimizers on 30 HPO problems, which consist of two-, three- and five-dimensional continuous search spaces of the XGBoost learner trained on 10 different data sets. This is contrasted with the performance of the same optimizers evaluated on 360 problem instances from the black-box optimization benchmark (BBOB). We then compute ELA features on the HPO and BBOB problems and examine similarities and differences. A cluster analysis of the HPO and BBOB problems in ELA feature space allows us to identify how the HPO problems compare to the BBOB problems on a structural meta-level. We identify a subset of BBOB problems that are close to the HPO problems in ELA feature space and show that optimizer performance is comparably similar on these two sets of benchmark problems. We highlight open challenges of ELA for HPO and discuss potential directions of future research and applications.
Tackling Neural Architecture Search With Quality Diversity Optimization
Jul 30, 2022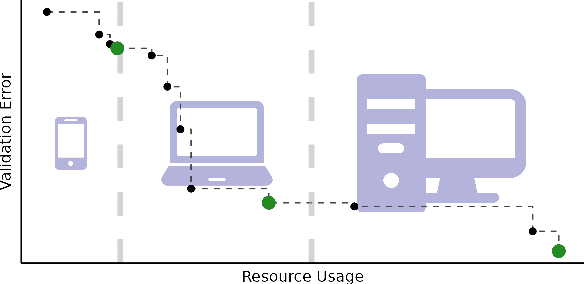

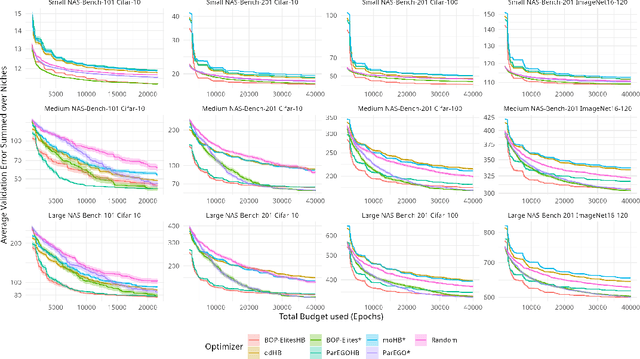

Neural architecture search (NAS) has been studied extensively and has grown to become a research field with substantial impact. While classical single-objective NAS searches for the architecture with the best performance, multi-objective NAS considers multiple objectives that should be optimized simultaneously, e.g., minimizing resource usage along the validation error. Although considerable progress has been made in the field of multi-objective NAS, we argue that there is some discrepancy between the actual optimization problem of practical interest and the optimization problem that multi-objective NAS tries to solve. We resolve this discrepancy by formulating the multi-objective NAS problem as a quality diversity optimization (QDO) problem and introduce three quality diversity NAS optimizers (two of them belonging to the group of multifidelity optimizers), which search for high-performing yet diverse architectures that are optimal for application-specific niches, e.g., hardware constraints. By comparing these optimizers to their multi-objective counterparts, we demonstrate that quality diversity NAS in general outperforms multi-objective NAS with respect to quality of solutions and efficiency. We further show how applications and future NAS research can thrive on QDO.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022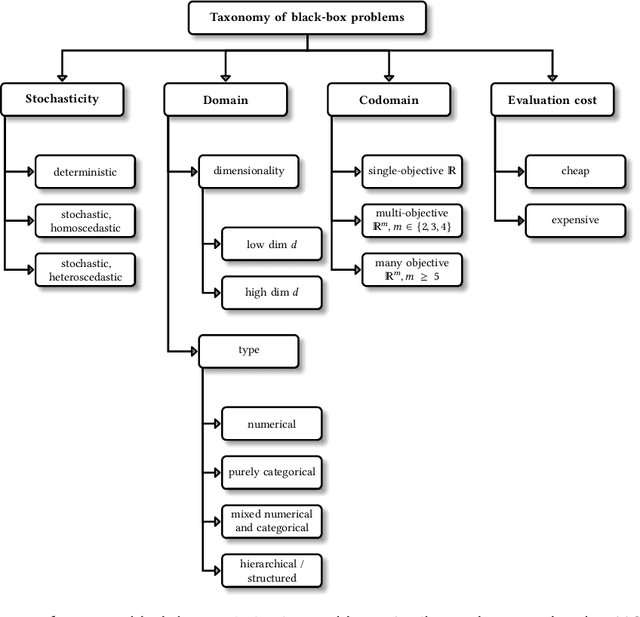

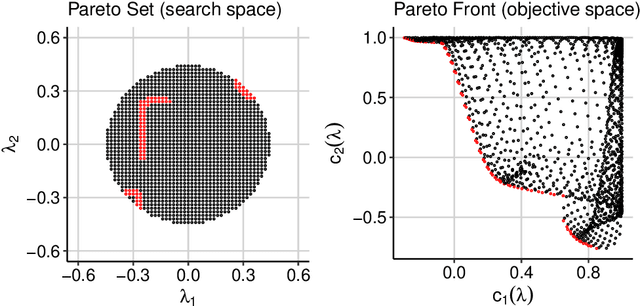
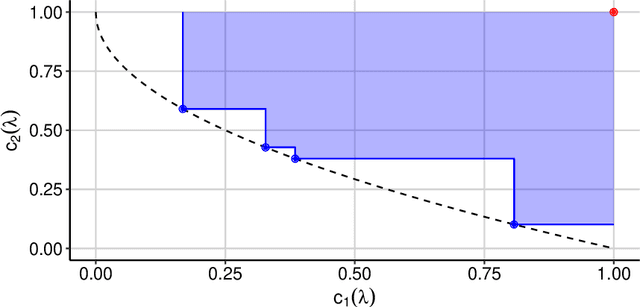
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.